
The Complete Guide to Database Sharding for System Design Interviews [2026 Edition]
A beginner-friendly sharding guide that explains shard keys, routing, resharding, hotspots, and cross-shard consistency with an interview-ready structure.

This blog explains:
Sharding goals
Shard key selection rules
Sharding Strategies
Routing and query planning
Resharding and rebalancing basics
Consistency and transaction tradeoffs

A database starts out fast when it is small. Then the dataset grows, traffic grows, and the workload changes from occasional spikes to sustained pressure.
Query time slowly drifts upward, background jobs run longer, and operational tasks such as backups, failover, and schema changes become harder to do safely.
At a certain point, adding more CPU or RAM stops being a reliable plan. Storage, write throughput, and peak concurrency can become bounded by a single machine’s limits, even if that machine is expensive.
This is the point where horizontal scaling becomes the main option, meaning adding more machines instead of upgrading one machine.
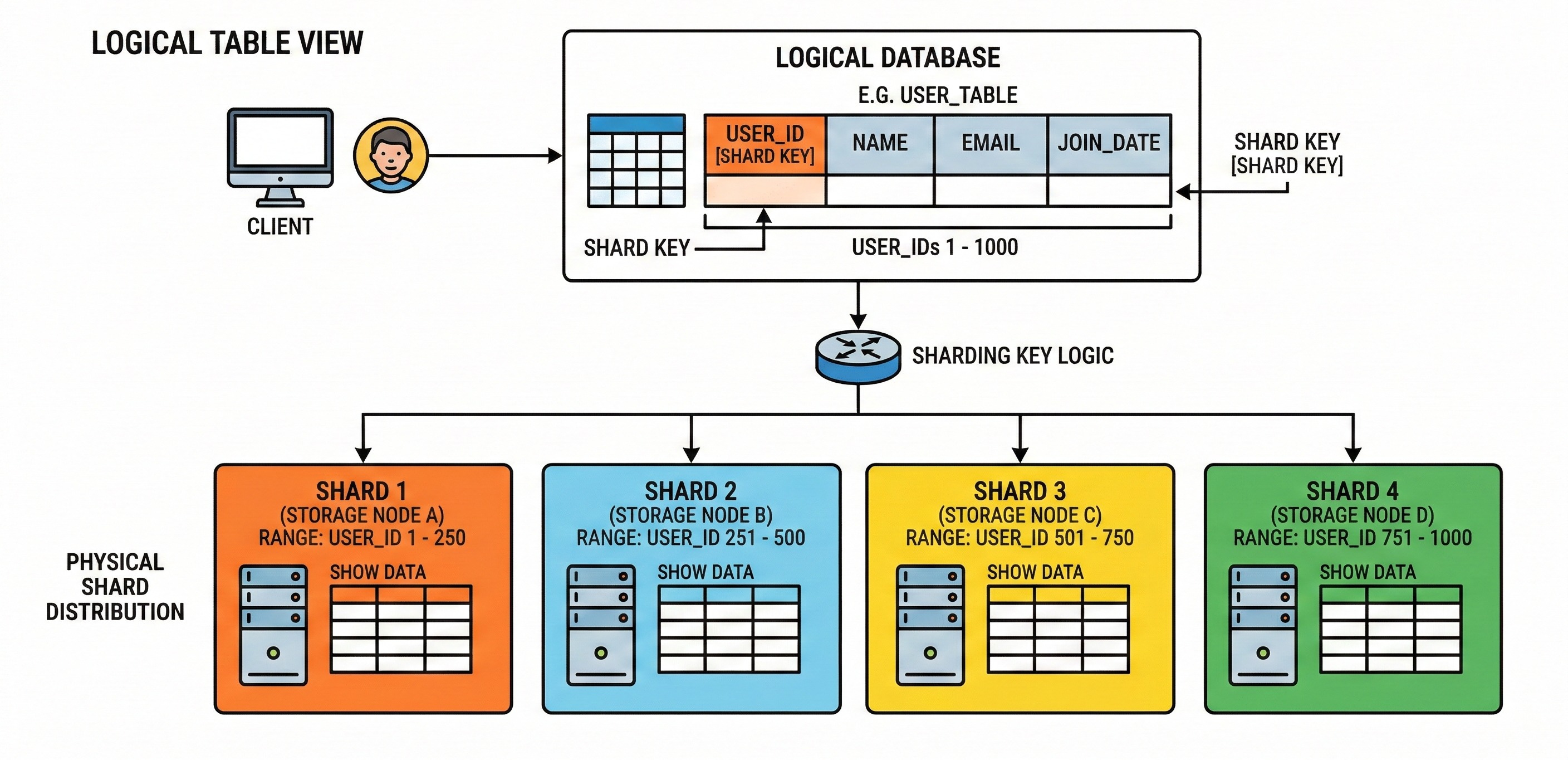
Database sharding is one of the most central horizontal scaling techniques. Sharding means splitting one logical dataset into multiple smaller datasets called shards, then placing those shards on different database servers. Each shard holds only a subset of the rows, so total storage and throughput can grow beyond what a single server can handle.
This guide focuses on what matters in system design interviews. It explains why sharding exists, how it works behind the scenes, how to choose a shard key, and what fails first when sharding is done poorly.
Sharding Fundamentals that Interviews Expect
Sharding is frequently mixed up with related ideas, so an interview-quality explanation starts by separating the terms.
Sharding: data is split across multiple database instances, usually on multiple servers. Each shard owns a subset of rows for a table (horizontal sharding) or a subset of columns (vertical sharding).
Partitioning (database partitioning): data is split into partitions, which are typically managed within a single database instance.
Partitioning is often used to reduce how much data a query must scan and to make maintenance easier.
A crisp way to say it in interviews is: partitioning organizes data inside one database system, while sharding distributes data across multiple database systems.
Replication: the same data is copied to multiple nodes.
Replication is mainly for availability and read scaling, not for increasing the maximum dataset size beyond one node’s storage.
Replication is often used together with sharding, because each shard is typically replicated for fault tolerance.
When interviewers ask about sharding, they almost always mean horizontal sharding. That is the approach where each shard stores the same schema, but different rows.
The Hidden Requirement that Makes Sharding Work
Sharding only works when the system can answer one question quickly:
Given a record or query, which shard should handle it?
That question is answered using a shard key, also called a partition key in many systems. A shard key is a column (or set of columns) used to deterministically map a row to a shard.
If the shard key maps evenly, shards share load.
If the shard key maps unevenly, one shard becomes overloaded and the entire system behaves as if it were not sharded at all.
This is why interviews treat the shard key as the “make or break” decision. Many real systems fail at sharding because the shard key was chosen before the access pattern was understood.
The Cost Side of Sharding
A strong candidate also says what gets worse after sharding.
Sharding increases complexity because:
Cross-shard queries require extra coordination, sometimes requiring the system to contact many shards and merge results.
Cross-shard transactions can require distributed transaction protocols such as two-phase commit, which adds latency and introduces failure modes.
Operational tasks become distributed, including backups, schema changes, migrations, and debugging.
This trade is usually correct only when the system has surpassed what partitioning, indexing, caching, and read replicas can achieve within a single primary database.
Shard Keys and Data Modeling for Beginners
A shard key is the field that decides shard placement.
If the shard key is user_id, then for any request that includes a user_id, the application can compute the shard and route the request directly to that shard.
This creates targeted operations, which is the best-case sharding behavior because only one shard is touched.
If a request does not include the shard key, the system may have to query multiple shards and merge the results. That is often called a scatter-gather pattern, and it can quickly erase the performance benefits of sharding.
So, the shard key is not only about distribution. It is also about whether queries can be targeted.
What Makes a Shard Key “Good”
A beginner-friendly way to evaluate a shard key is to test it against five properties.
A good shard key tends to have high cardinality, meaning many distinct values. High cardinality makes it easier to spread records across many shards evenly.
A good shard key tends to produce uniform access, meaning requests are spread across many values instead of concentrating on a few.
If most traffic hits one key value or a narrow range, the shard holding that range becomes a hotspot.
A good shard key aligns with the most common query filters.
If most queries filter by user_id, then user_id is often a strong candidate.
If most queries filter by created_at ranges, then a time-based strategy may be relevant, but it can create hot ranges if new records always land in the same shard.
A good shard key supports the required uniqueness and constraints.
In a sharded world, enforcing uniqueness across all shards can become expensive, because it becomes a distributed check. Many systems restrict features or require careful planning around keys and sequences when sharded.
A good shard key keeps related updates on the same shard when possible. This matters because cross-shard transactions are slower and riskier than single-shard transactions.
These properties sound abstract, but interviews reward being able to say them clearly and then apply them.
The Hotspot Problem
A hotspot happens when a small subset of shards gets a disproportionate share of traffic.
In systems that partition by a key, uneven key access can create “hot partitions,” where one partition hits limits even if the table’s total capacity seems sufficient.
This is not a minor performance issue. Hot partitions can cause throttling and elevated latency, and they can be visible as shard-level overload rather than cluster-level overload.
In interviews, hotspot awareness is a signal of maturity. It shows understanding that sharding is not only “split data and win.”
Composite Shard Keys and Why they Exist
Sometimes a single column is not enough.
A composite shard key uses multiple fields, often to increase cardinality and spread load. A common structure is (tenant_id, entity_id) in multi-tenant systems, where the goal is to ensure operations stay within one tenant’s shard most of the time.
The trade is that composite keys can complicate query patterns.
If queries frequently filter by entity_id without tenant_id, targeted routing becomes difficult.
Composite keys help distribution, but they can reduce targeting if queries do not carry the full key.
Secondary Indexes in a Sharded Database
Indexes do not disappear with sharding. They become distributed.
In many designs, each shard builds indexes for the rows it holds. That means index lookups are fast only when the query is targeted to a shard.
If the query is not targeted, each shard may need to run an index scan and the system must merge results.
Some systems shard indexes in the same way as tables, meaning an index lookup is still a shard-local operation if it uses the shard key.
This is why “query pattern first, shard key second” is a common interview message. Indexing and sharding decisions are tightly coupled.
Sharding Strategies and How Data is Placed
Range-based Sharding
Range-based sharding assigns shards based on contiguous ranges of the shard key.
For example, shard A might hold keys [0, 1,000,000), shard B holds [1,000,000, 2,000,000), and so on.
Range-based sharding has a clear upside: range queries can be efficient, because relevant data is clustered. A query for a range of keys can be routed to a smaller set of shards.
The downside is skew risk.
If new inserts always land in the latest range, the newest shard becomes hot. If certain ranges are accessed more than others, load becomes uneven.
Interviews often expect the candidate to say both: range-based sharding fits range queries, but needs active balancing and careful range planning.
Hash-based Sharding
Hash-based sharding applies a hash function to the shard key and uses the result to pick the shard.
A simple non-production formula might look like: shard_id = hash(user_id) mod N.
Hashing tends to distribute keys more evenly, which helps avoid hotspots caused by sequential keys.
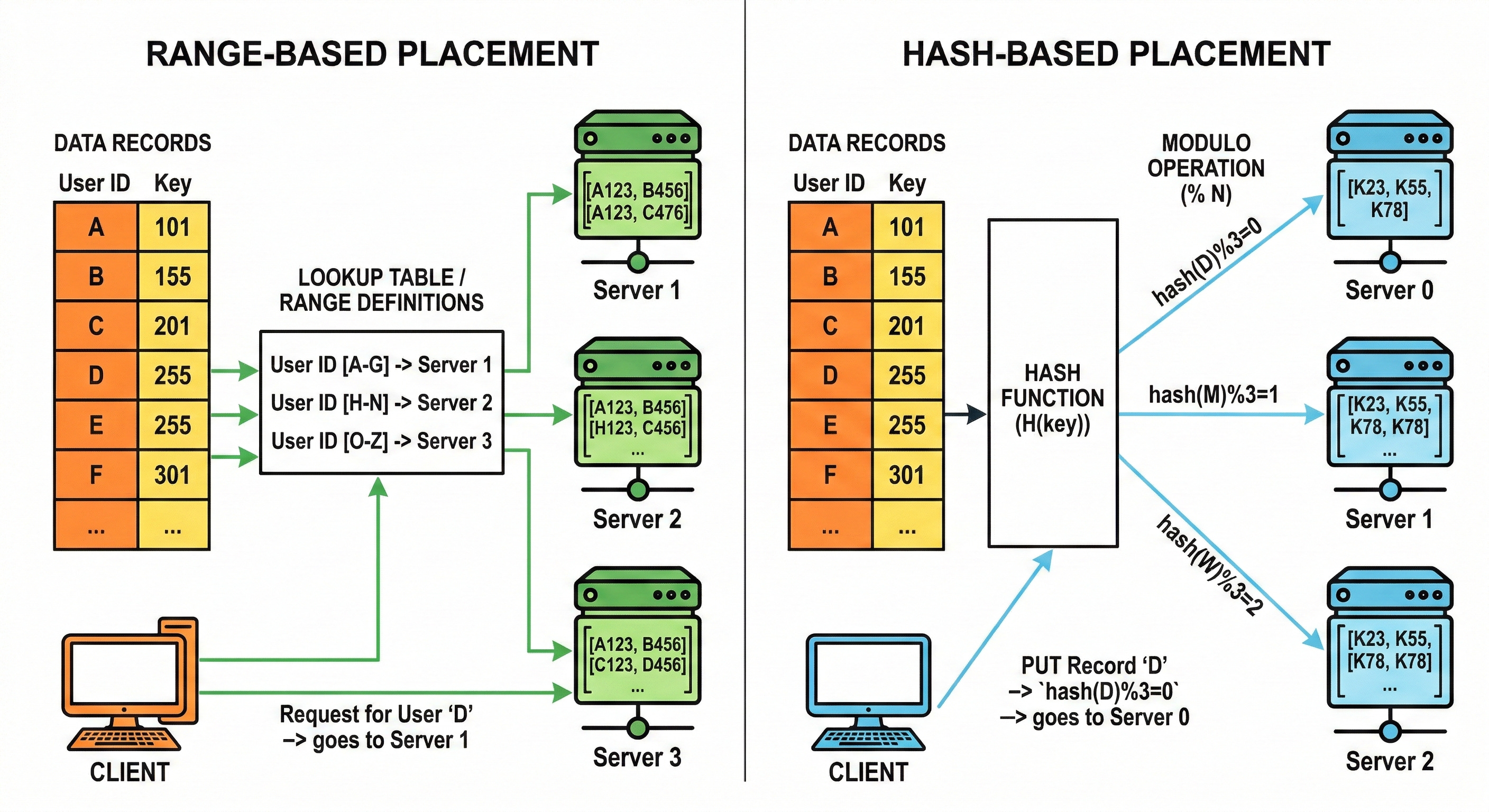
The trade is that range queries become harder, because adjacent keys do not land near each other. A range query may touch many shards.
Hash-based sharding is commonly the default choice in interviews when query patterns are mostly point lookups by ID and the primary risk is uneven load.
Consistent Hashing and Why it is Still Relevant in 2026
Plain hashing with mod N has a big operational problem: when N changes, most keys remap, so most data must move.
Consistent hashing was created to reduce that remapping problem when nodes are added or removed. It aims for balanced placement while keeping the amount of moved data relatively small compared to naive modulo hashing.
Keys and shards are mapped into the same hash space. Each key is assigned to the next shard position in that space.
When a shard is added, only a portion of keys move to the new shard instead of most keys moving.
This matters because rebalancing is one of the hardest parts of running a sharded database. Minimizing moved data reduces migration time, reduces risk, and reduces the amount of background load introduced by rebalancing.
Consistent hashing is also not “done” as a topic. Research and engineering work continues to improve balance, memory usage, and reassignment properties of consistent hashing variants.
Directory-based Sharding
Directory-based sharding uses a lookup structure that maps a key to a shard.
Instead of requiring “compute shard from key,” the system first asks a directory service: “Where is key X stored?”
The biggest benefit is flexibility. Keys can be remapped without changing the hashing scheme, and different tenants or key ranges can be moved independently.
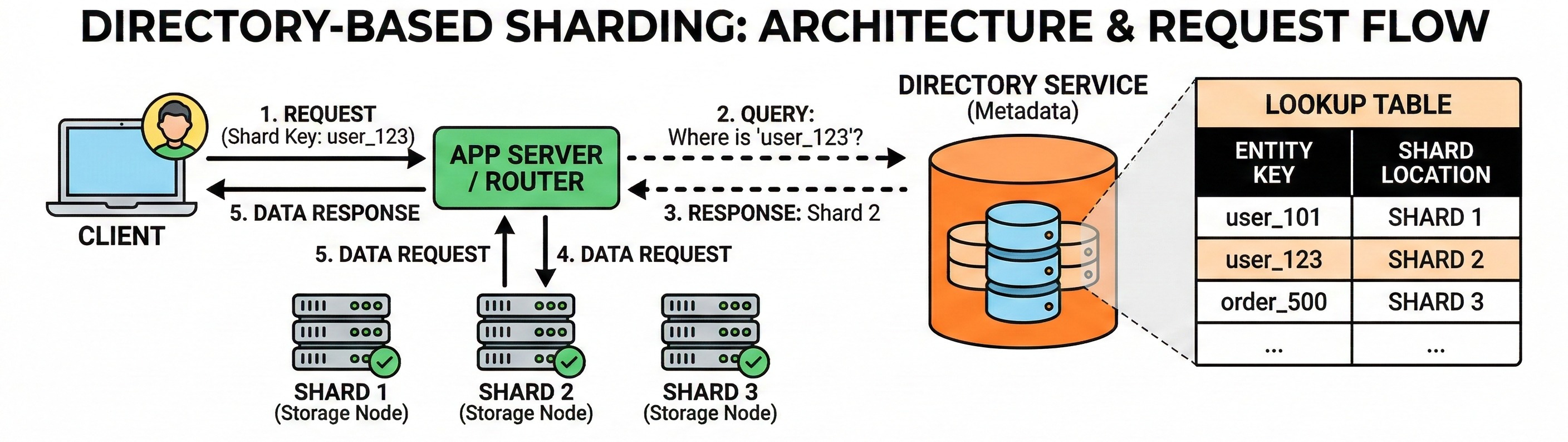
The biggest cost is that the directory becomes part of the critical path. It adds extra latency and becomes a dependency for routing. It also needs strong correctness properties, because wrong mapping means reading or writing the wrong shard.
An interview-ready summary is: directory-based sharding trades performance and simplicity for flexibility.
Hybrid Strategies are Normal
Real systems often combine strategies.
