
Database Sharding 101: Range vs Hash vs Geo – Pros, Cons & Use Cases
Discover how database sharding boosts scalability. It explains range, hash, and geo sharding strategies and how each one partitions data to handle massive scale.

This blog demystifies database sharding and why it’s a game-changer for scaling. It explores major sharding strategies (range, hash, and geo) with their pros, cons, and real-world challenges of managing a sharded database.
Imagine your application’s user base explodes overnight – great for business, but now every query slows to a crawl as the single database server struggles to keep up.
This is where database sharding comes to the rescue.
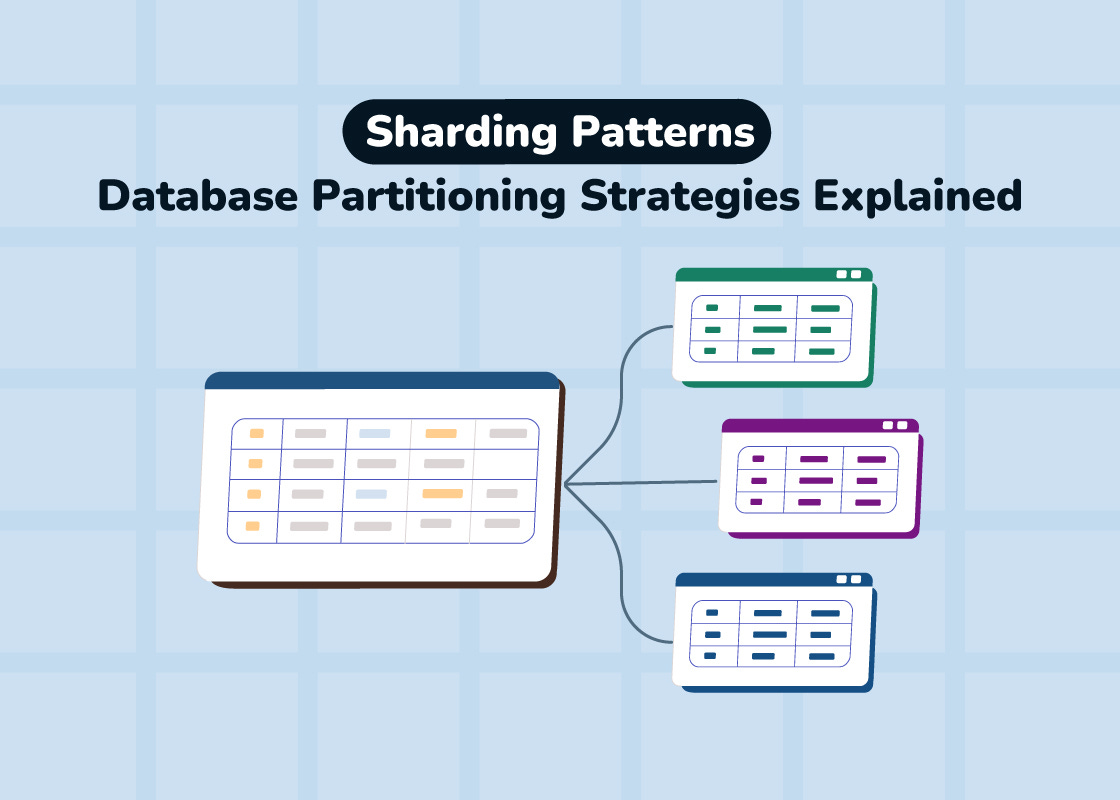
Sharding means splitting one large database into several smaller ones (called shards) and spreading them across multiple servers.
This horizontal “scale-out” approach lets many machines share the workload.
Sharding isn’t one-size-fits-all – there are different ways to partition data, and choosing the right pattern is crucial.
Let’s break down three common sharding strategies – range-based, hash-based, and geo-based sharding – to see how they work and when to use each.
We’ll also touch on the operational complexities that come with running a sharded database.
Range-Based Sharding (Range Partitioning)
Range sharding splits the dataset based on contiguous ranges of a shard key’s values.
Each shard is responsible for a specific slice of the data.
For example, if we shard by the first letter of a customer’s name, customers whose names start with A–I go to one shard, J–S to the next, and T–Z to another.
Pros
This strategy is straightforward and great for range queries – if you request all records in a certain span (say, all orders in January), that data is likely on one shard, making the query efficient.
