
System Design Interview: The 7 Microservices Patterns You Must Know
A comprehensive guide to microservices architecture. Learn the essential microservices patterns like API Gateway, Circuit Breaker, SAGAs, and Service discovery.

Software systems have a natural tendency to grow in complexity over time.
A codebase that starts small and manageable often expands into a massive collection of code that is difficult to understand and risky to modify.
When a single program handles every business logic, database operation, and user interaction, it becomes what is known technically as a monolithic architecture.
While this approach works well for small teams and simple products, it creates significant bottlenecks as the software scales.
Large organizations and high-traffic applications eventually reach a point where the monolith slows down development.
To solve this, engineers break the single massive application into smaller, independent units called microservices. Each unit focuses on doing one specific task very well.
However, moving from one big block of code to many small distributed parts introduces new challenges. These challenges include how these parts communicate, how they handle data, and what happens when one part fails.
System design patterns provide proven solutions to these specific engineering problems.
Key Takeaways
Microservices decouple complex software into small and independent services to improve scalability and maintainability.
The API Gateway pattern acts as a single entry point to manage traffic and route requests to the correct internal services.
Service Discovery allows applications to automatically find network locations of dynamic services without hard-coding addresses.
The Database per Service pattern ensures loose coupling by giving each microservice ownership of its own data storage.
Circuit Breakers prevent catastrophic system failures by stopping requests to a service that is currently malfunctioning.
The API Gateway Pattern
When a client application, such as a mobile app or a web browser, needs to communicate with a microservices system, it faces a logistical challenge.
If an application is split into fifty different services, the client should not need to know the address and details of all fifty services.
Allowing a client to talk directly to every internal service creates a security risk and makes the client code incredibly complex.
The API Gateway pattern solves this by placing a specialized server between the client and the internal microservices. This server acts as the single entry point for all traffic coming from the outside world.
When a client makes a request, it sends it to the API Gateway.
The Gateway analyzes the request and routes it to the appropriate specific service inside the system.
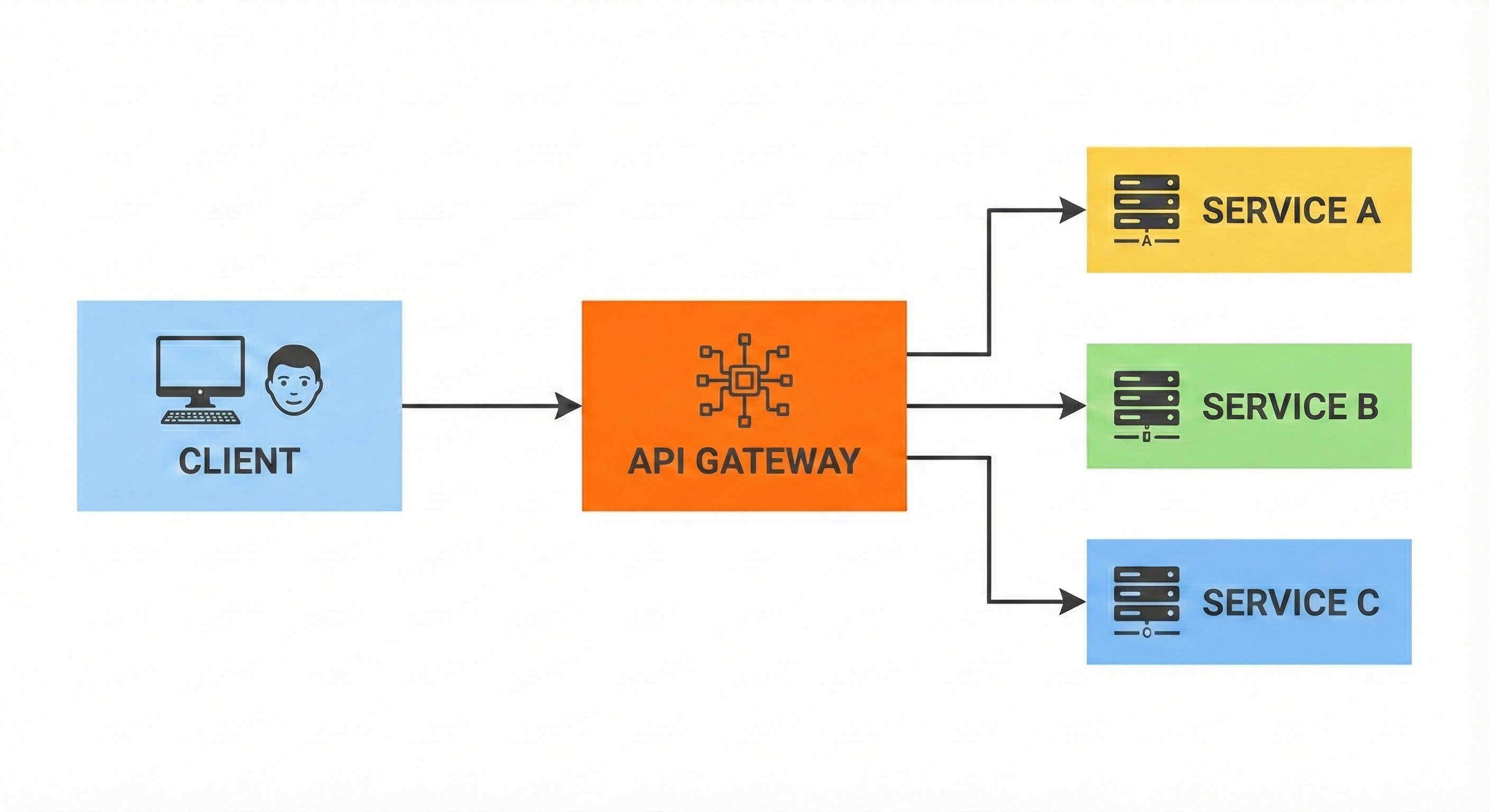
This pattern provides several benefits beyond simple routing. It can handle cross-cutting concerns that every service needs but should not implement individually.
For example, the Gateway can verify the identity of the user. It checks if the user has permission to access the system before the request ever reaches the internal services. This means the internal services can focus purely on business logic rather than security protocols.
Another function of the API Gateway is protocol translation. Internal services might use a fast, lightweight communication method that is not friendly for web browsers.
The Gateway can accept a standard web request (HTTP) from the client and convert it into the internal format required by the backend services. This hides the complexity of the internal architecture from the outside world.
If the internal structure changes, the client does not need to know, because the Gateway masks those changes.
The Service Discovery Pattern
In a monolithic application, different modules call each other simply by invoking a function within the same memory space.
In a microservices architecture, services communicate over a network.
To do this, Service A needs to know the network address (IP address and port) of Service B.
In traditional hosting, these addresses were static. Engineers could write the IP address of a server into a configuration file, and it would rarely change.
In modern cloud environments, this is no longer true.
Services are dynamic. They start up and shut down automatically based on traffic demand.
A service might move from one server to another purely to optimize resource usage. This means the network address of a service is constantly changing.
The Service Discovery pattern addresses this dynamic nature. It introduces a component often called a Service Registry. This registry acts as a live database of all available service instances and their current locations.
There are two main ways this works: Client-Side Discovery and Server-Side Discovery.
In Client-Side Discovery, when Service A wants to call Service B, it first queries the Service Registry to ask for the location of Service B.
The registry returns the current address. Service A then uses that address to make the call. This is efficient but requires every service to have logic to talk to the registry.
In Server-Side Discovery, Service A just makes a call to a load balancer.
The load balancer queries the Service Registry and forwards the traffic to the correct instance of Service B. This is simpler for the developer because the network complexity is handled by the infrastructure, not the code.

The Database per Service Pattern
One of the most difficult decisions in system design is how to manage data.
In a monolith, it is standard to have one massive database that contains tables for every part of the application. This makes it easy to join data from different tables, but it creates tight coupling.