
System Design Deep Dive: Architecting Idempotent APIs
Learn how to architect idempotent APIs to ensure safe network retries and prevent duplicate transactions in distributed software systems.

Building reliable software over unpredictable networks presents a massive architectural challenge. Any hardware component can fail unexpectedly during data transmission.
A network router might drop a connection right before a success confirmation reaches the client application. This leaves the entire distributed system in a state of technical uncertainty.
Automated retries are the standard programmatic response to these network timeouts. However, blindly retrying network requests can cause catastrophic duplicate processing within backend databases.
Processing the exact same financial deduction twice destroys data integrity and system trust.
Designing an architecture that safely handles these automated retries is a strict engineering requirement.
The Danger of Network Uncertainty
To understand why automatic retries are dangerous, we must examine how servers handle data.
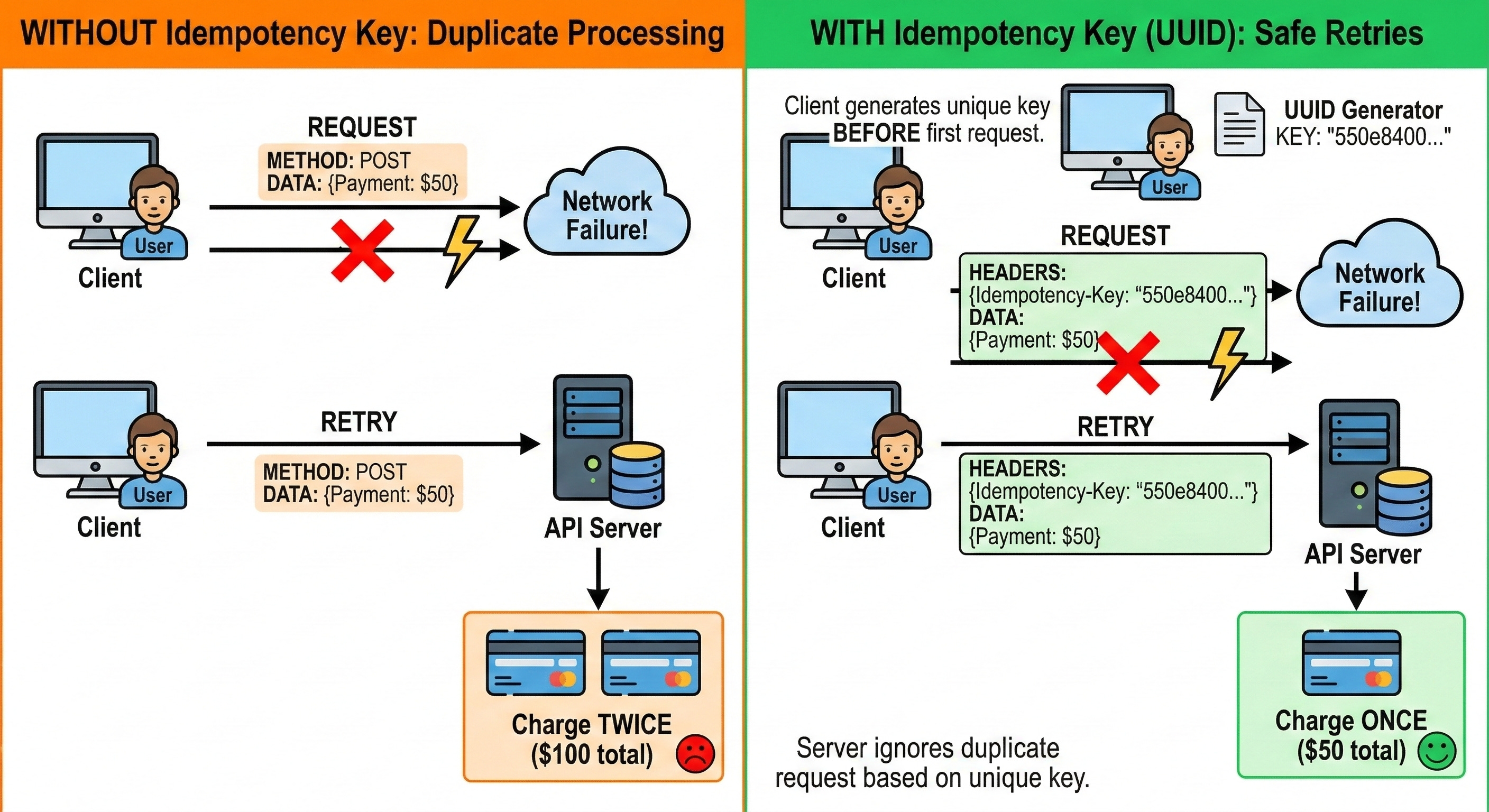
When a client application sends a data payload over the internet, it expects a definitive response. The network connection might break while the server is sending that response back. The client application assumes the entire process failed and sends the request again.
A poorly designed backend server will process this retry as a brand new command.
In a payment gateway, this means the server deducts funds from an account a second time. The system needs a specific way to separate safe initial requests from dangerous automated retries.
This separation ensures that the database precisely reflects the true intent of the original client application.
Defining the Core Concept
To solve this critical flaw, software engineers implement a foundational concept called idempotency.
In computer science, an operation is idempotent if executing it multiple times produces the exact same final result as executing it just once.
The initial request successfully changes the state of the backend database. Any subsequent duplicate requests are safely caught and ignored by the server.
When a system is completely idempotent, client applications can safely retry failed requests infinitely. The server takes full responsibility for recognizing duplicate data.
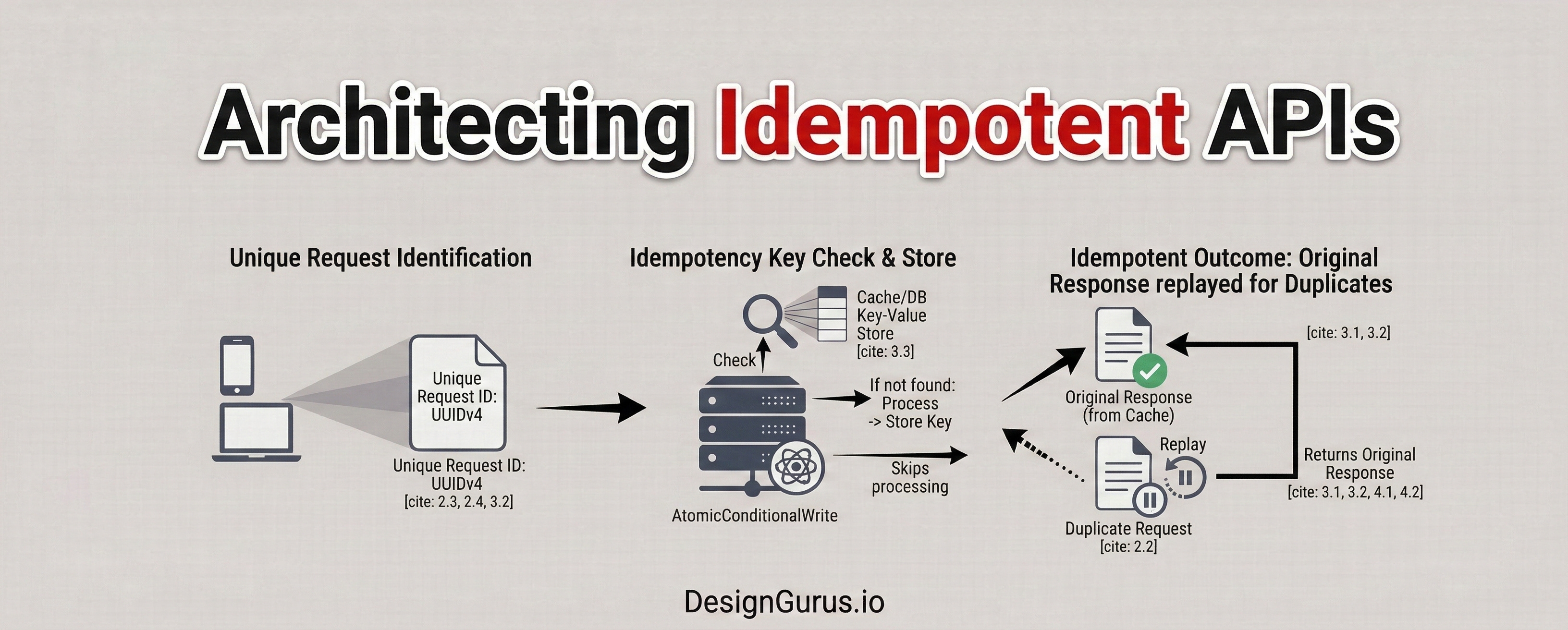
If the server sees a network request it has already processed, it skips the execution logic entirely. The server simply fetches the original success response and returns it to the client application.
This design pattern completely eliminates the risk of duplicate database entries. It shifts the burden of safety from the chaotic network to the intelligent server.
The client application does not need complex logic to determine if a transaction actually succeeded. The client simply retries the request until it receives a clear response.
Safe and Unsafe Network Operations
Certain network operations are naturally idempotent by their default design. Operations that simply read data from a database are inherently safe.
If a client application sends an HTTP GET request to view a user profile twenty times, the database remains unchanged. Retrying a read operation during a network failure carries absolutely no risk.
Operations that modify database records behave completely differently.
An HTTP POST request typically creates a new resource or appends data to a system. In a financial ledger, appending a transaction multiple times creates duplicate entries. Engineers must manually build idempotency into POST requests to ensure strict data safety.
The Mechanics Behind Safe Retries
Building an idempotent payment gateway requires specific architectural components. The system cannot rely on the payload data itself to identify duplicates.
Two completely separate transactions might legitimately contain the exact same financial values. The system needs a specialized tracking mechanism to identify exact duplicate requests.
Introducing the Idempotency Key
The entire architecture revolves around a unique string of characters called an Idempotency Key.
This key is a specialized digital label that travels alongside the data payload. The client application is strictly responsible for generating this unique key. The client application must generate the key before attempting the very first network request.
Software engineers overwhelmingly use a UUID for this specific task.
A UUID is a Universally Unique Identifier. It is a standardized algorithmic label that provides mathematical uniqueness. A client application can generate millions of these identifiers without ever creating a duplicate.
The client application injects this generated key into the hidden headers of the outgoing network request. A header is a designated section of metadata that accompanies the main data payload.
If the network connection fails, the client application must retry the request.
Crucially, the client application must attach the exact same key to the retry request.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.