
System Design Deep Dive: UUIDs vs. Snowflake IDs in B+ Trees
Random primary keys cause cache thrashing and wasted storage. Discover the architectural reasons to switch to sortable unique identifiers.


Choosing a Primary Key is one of the foundational decisions in system design. It happens early in the development lifecycle and often before the application logic is fully fleshed out.
In many modern development environments, the default choice has shifted away from simple integers to the UUID (Universally Unique Identifier).
The reasoning behind this shift is sound regarding distributed systems.
As applications scale horizontally across multiple servers, relying on a single database to issue auto-incrementing numbers becomes a bottleneck. It also introduces a single point of failure.
UUIDs allow application servers to generate unique identifiers independently. They require zero coordination with the database or other nodes. This decoupling is highly attractive for developers building microservices or distributed architectures.
However, this convenience comes with a significant and often overlooked cost.
While UUIDs solve the problem of unique generation, they introduce a severe performance penalty on the storage layer of relational databases. This penalty manifests as Database Fragmentation.
When you use a standard random UUID as a Primary Key, you are fighting against the architectural design of the database index.
In this post, we will explore the mechanical reasons why random IDs degrade write performance. We will also examine the internal structure of B+ Trees, the concept of Page Splitting, and why industry-standard solutions like Twitter Snowflake offer a superior alternative.
The Mechanics of the B+ Tree Index
To understand why randomness is problematic, we must first understand how relational databases store data.
Systems like MySQL (specifically the InnoDB engine) and PostgreSQL do not simply append new rows to the end of a file.
If they did, retrieving a specific record would require scanning the entire file.
This is inefficient for large datasets.
Instead, these databases use a data structure called a B+ Tree to manage the Primary Key index.
A B+ Tree is a balanced tree structure that keeps data sorted. It allows for efficient retrieval, insertion, and deletion operations.
The most critical aspect of the B+ Tree in this context is the Clustered Index.
In a Clustered Index, the physical storage of the table data is organized by the Primary Key. The rows are stored on the disk in the same order as the keys.
If you have a Primary Key of 1, 2, and 3, the database stores the row for ID 1 physically next to the row for ID 2.
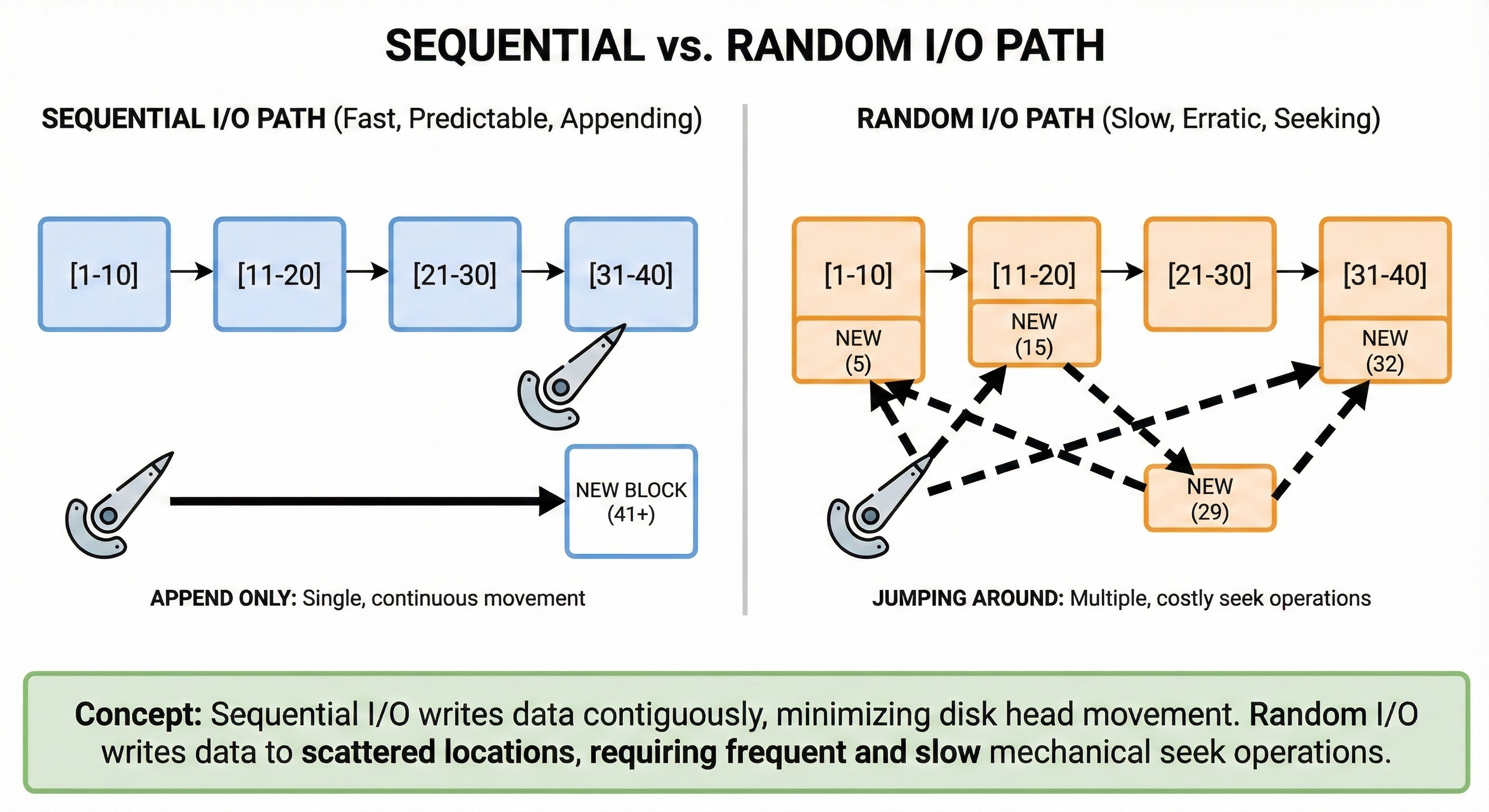
The Concept of Database Pages
The B+ Tree does not manage individual rows one by one.
Instead, it manages fixed-size units of storage called Pages (sometimes referred to as Blocks). A typical Page size in many database systems is 16KB.
