
Read Replicas Explained: How Databases Scale to Millions of Reads
Learn how read replicas solve database bottlenecks by separating read and write operations. Covers write-ahead logs, sync vs async replication, replication lag fixes, proxy routing, and failover.


Software applications face severe performance bottlenecks when network traffic scales upward.
A single central database server typically processes every incoming data request.
When query volume spikes significantly, this central server must work extremely hard. It must process data creation and data retrieval operations simultaneously.
The system memory eventually fills up completely. The processor usage spikes to its absolute maximum capacity. This hardware exhaustion inevitably leads to slow application response times. It can even cause complete system crashes during peak traffic hours.
Addressing this specific database bottleneck is a highly critical skill in modern software engineering.
Understanding how to distribute database workloads separates basic applications from highly scalable distributed systems.
The Core Problem With A Single Database
Every database server has strict physical limits regarding processing power and memory.
A single database is responsible for executing two fundamentally different types of operations. It must handle write operations, which involve storing new data or updating existing records. It must also handle read operations, which involve searching for and returning requested data.
In most software applications, read operations heavily outnumber write operations.
An application might process one single write operation to save a new data record.
Immediately after, it might process thousands of read operations to display that exact same record to other clients. This creates a massive imbalance in the database workload.
The database spends the vast majority of its computing resources simply fetching data that already exists.
When thousands of read requests hit the database at the exact same time, the server forms a queue. Incoming write operations are forced to wait.
The server must finish processing the massive backlog of read operations first before it can save new data.
This queue causes the entire application to feel incredibly slow. Software developers must find a way to split this workload so the database can function efficiently.
What Are Read Replicas?
Read Replicas offer a direct architectural solution to the single database bottleneck.
A read replica is an exact copy of the main database server. System designers use this to separate write operations from read operations.
Developers define two distinct types of database servers.
The Primary Node is the main database server. This node accepts all new data and handles all write operations exclusively.
The Replica Node is the secondary database server. It contains a full copy of the data and handles read operations. By sending read requests to replica nodes, the primary node is freed up completely.
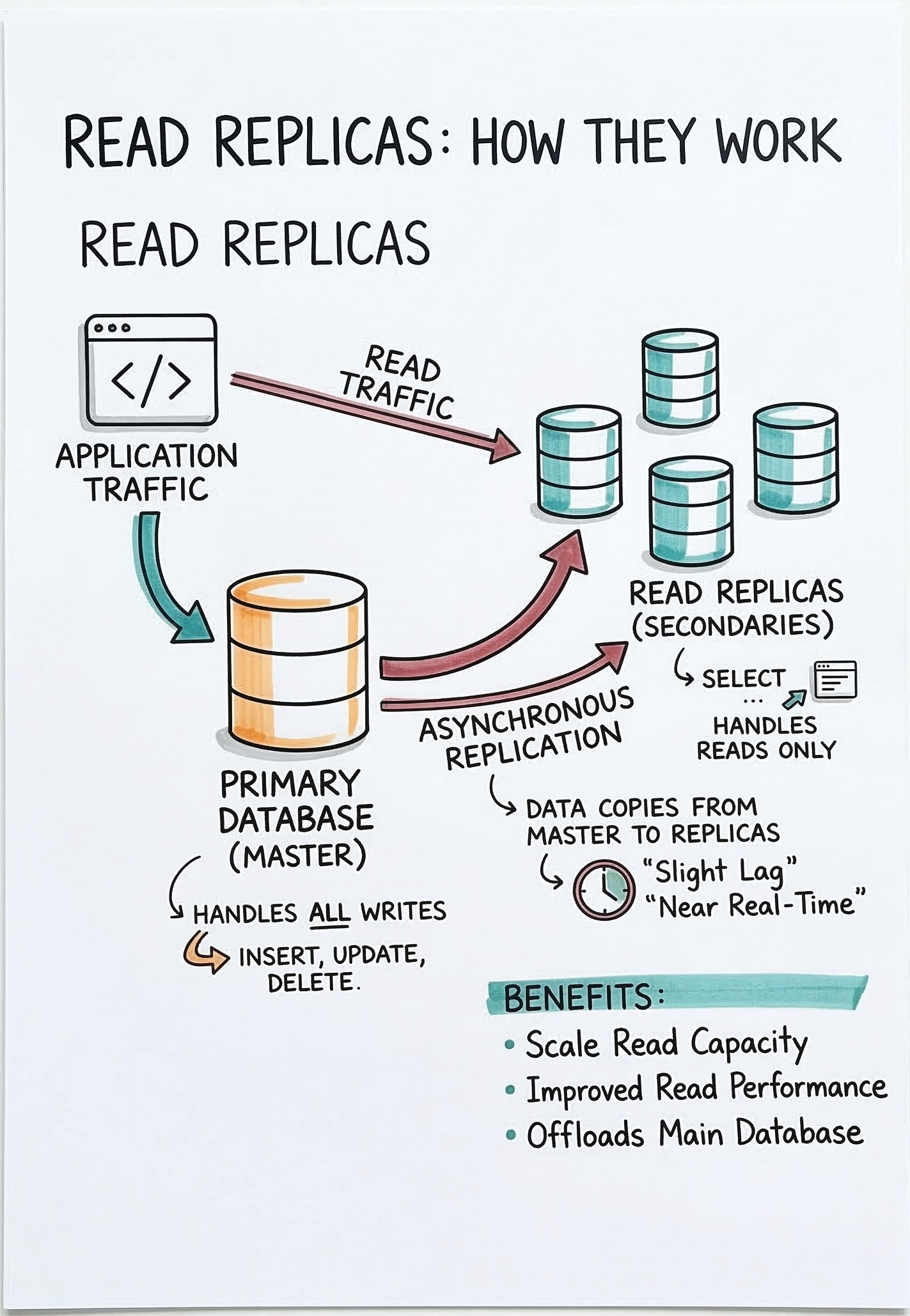
The primary node can dedicate its computing resources to saving new data quickly.
If application traffic grows, developers add more replica nodes to the network. This handles extra read requests gracefully.
How Data Gets Copied Behind The Scenes
Creating a copy of a database sounds simple in theory.
Keeping multiple database servers perfectly synchronized requires highly specific technical mechanisms.
When an application sends a write request to the primary node, that new data must travel to the replica nodes.
This section examines how this internal data transfer actually happens.
The Write Ahead Log
Databases use a special internal file called a Write Ahead Log.
Before the primary node permanently saves any new data to its main storage, it records the exact details of the change into this log file.
The log acts as a sequential and chronological record of every single change ever made to the database.