
System Design Deep Dive: How Databases Survive Power Failures
Understand the core mechanism that enforces ACID properties. A technical breakdown of how WAL handles crash recovery and atomicity.


The most fundamental responsibility of a data storage system is to ensure that acknowledged data is never lost.
When a database confirms to an application that a transaction is complete, that data must persist. It must survive power outages, operating system crashes, and hardware resets.
However, achieving this persistence presents a difficult engineering challenge due to the physical limitations of computer hardware.
System architects face a conflict between performance and reliability.
Memory (RAM) is fast but volatile; it loses all information when power is cut. Storage drives (HDDs and SSDs) are persistent but significantly slower than memory.
Designing a system that is both responsive enough to handle thousands of requests per second and reliable enough to never lose data requires a specific architectural pattern.
This pattern is known as Write Ahead Logging (WAL).
It serves as the standard solution for maintaining data integrity in almost all modern relational databases and distributed storage engines.
The Conflict Between Latency and Persistence
To understand the necessity of Write Ahead Logging, one must first understand the cost of writing to a disk.
In a standard database, data is organized logically using structures like B-Trees or hash indexes. These structures help the system read data quickly, but they scatter information across the physical storage drive.
A single user profile might be stored at address X, while the index pointing to that profile is stored at address Y, and the transaction history is at address Z.
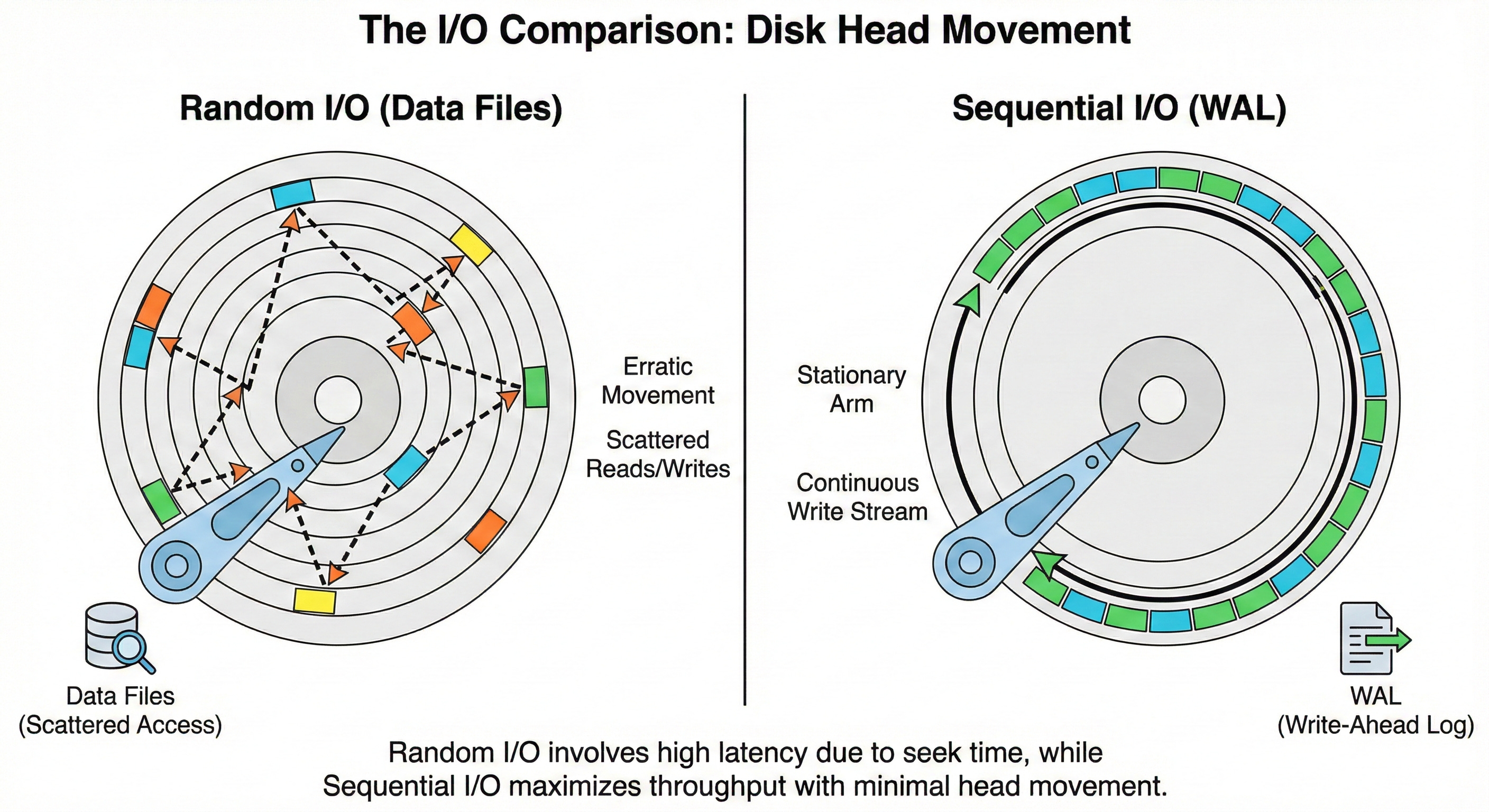
Updating this information requires Random I/O.
The storage device must physically move its read/write head or address different internal memory blocks to update these distinct locations. This process incurs high latency.
If a database forced the disk to perform these random writes for every single incoming transaction before sending a success response, the system would become incredibly slow.
The alternative is to make changes only in the fast, volatile RAM and write them to the disk later.
This provides excellent performance but introduces a critical failure mode.
If the power fails after the change is made in RAM but before it is written to the disk, the data is lost irrevocably.
Write Ahead Logging resolves this tension. It allows the system to utilize the speed of RAM while providing the durability guarantee of a disk.
The Core Concept
The protocol of Write Ahead Logging is defined by a single, inviolable rule: No modification is applied to the main data files until it has been written to a log file on persistent storage.
The system separates the intent to change data from the actual application of that change.
When a request is received, the database does not immediately modify the complex data structures scattered across the drive.
Instead, it creates a compact record of the operation. This record is appended to the end of a log file.
This log file utilizes Sequential I/O.
Because the system is simply adding data to the end of the file, the disk does not need to perform expensive seek operations. It streams the data to the storage medium efficiently.
Once this log entry is safely stored on the persistent disk, the transaction is considered durable.
The system can then update the data in memory and acknowledge the request as successful.
The actual synchronization of the modified memory to the main data files happens later, in the background.
The Anatomy of a Log Record
A Write Ahead Log is not a human-readable text file. It is a highly optimized binary stream.
Each entry in the log contains specific metadata required to reconstruct the database state.
