
Read-Heavy vs Write-Heavy Systems: The Framework FAANG Interviewers Use
Understand why read-heavy systems need caching and replicas while write-heavy systems need sharding and queues. A complete beginner’s guide to system design tradeoffs.

What This Blog Will Cover:
Read-heavy and write-heavy system differences
How to identify system workload types
Database and caching design tradeoffs
Scaling strategies for each system type
Framework for system design interviews
Most system design interviews start with a deceptively simple question.
The interviewer describes a system. They ask you to design it.
And the very first decision you need to make, before you even touch a database or draw a single box on the whiteboard, is this:
Is this system read-heavy or write-heavy?
Get this wrong, and every decision that follows will be wrong too.
Your database choice, your caching strategy, your replication model, your indexing approach. All of it falls apart if you misidentify the workload.
Here is the thing that nobody tells you early enough.
The difference between a candidate who gets a “strong hire” and one who gets a “no hire” often comes down to this one judgment call.
Not because the concept is hard. But because most candidates skip right past it and jump into drawing boxes on a whiteboard without thinking about the nature of the traffic first.
So let’s fix that today.
What Are Read-Heavy and Write-Heavy Systems?
Let’s start with the basics and build up from there.
A read-heavy system is one where the vast majority of operations are about fetching or retrieving data.
Users are mostly looking at things, searching for things, or loading pages.
The system spends most of its time answering the question: “Give me this data.”
A write-heavy system is the opposite.
Most operations involve creating, updating, or deleting data.
The system spends most of its time answering the question: “Store this data for me.”
Now, almost every system does both reads and writes. That is obvious.
But the ratio between the two is what determines how you should architect the entire thing.
A system where 95% of requests are reads and 5% are writes needs a fundamentally different design than a system where 70% of requests are writes.
How to Identify the Workload Type
This is the part that trips people up in interviews.
How do you actually figure out if a system is read-heavy or write-heavy?
You ask yourself a simple question: What are users doing most of the time?
If users are mostly consuming content, browsing, searching, or viewing data, you are looking at a read-heavy system.
If users are mostly generating content, logging events, submitting data, or triggering updates, you are looking at a write-heavy system.
That single question will guide you correctly about 90% of the time.
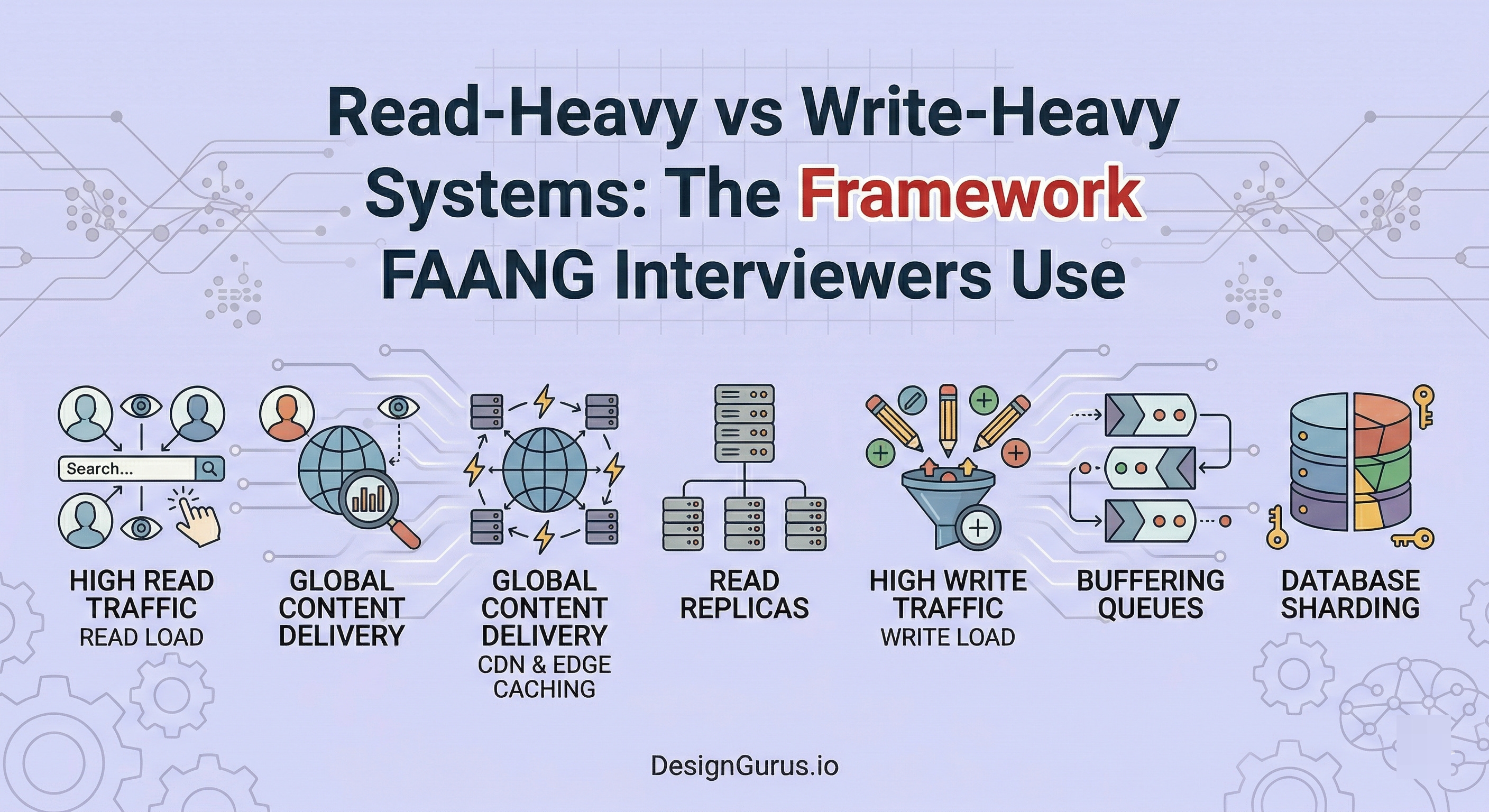
Designing for Read-Heavy Systems
When reads dominate your system, your primary enemy is latency.
Users are requesting data constantly, and they expect it fast.
If every single read request hits your database directly, the database will eventually buckle under the load.
So here is how you fight back.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.