
How to Design a Rate Limiter: 3 Algorithms Every Backend Engineer Should Know
Learn how to design a rate limiter using Fixed Window, Token Bucket, and Leaky Bucket algorithms. Covers the edge case boundary problem, lazy refilling, race conditions, & atomic Lua scripts in Redis.


In the domain of backend engineering, system stability is just as important as feature development.
When you design an API, you define how it behaves under normal circumstances. However, production environments are rarely normal. They are unpredictable.
A sudden surge in user activity, a misconfigured script from a client, or a malicious attempt to overwhelm your servers can lead to catastrophic failure.
When a server receives more requests than it can process, it does not just slow down. It often crashes.
Database connections get exhausted, memory fills up, and the service becomes unavailable for every single user.
To prevent this scenario, we use a component called a Rate Limiter.
A rate limiter is a defensive mechanism that sits between the incoming traffic and your core application logic. It enforces a strict limit on how many requests a user can make within a specific time period.
If the user stays within the limit, their requests are processed.
If they exceed the limit, the requests are rejected immediately, saving your server’s resources for legitimate traffic.
It is not just about protection. It is about understanding distributed state, concurrency, and algorithmic efficiency.
This is why “Design a Rate Limiter” is one of the most common questions in System Design Interviews.
In this guide, we will move beyond the surface level.
We will explore the mathematical logic behind the three most common algorithms: Fixed Window, Token Bucket, and Leaky Bucket.
We will also discuss exactly how to implement them using Redis, focusing on the technical challenges of distributed counting.
The Technical Goal
Before we look at the algorithms, we must define the problem clearly.
We need a system that tracks the activity of a specific identifier (like a User ID or an IP Address). We need to count their requests over time.
Most importantly, this counting must be fast.
If an API request takes 100 milliseconds to process, we cannot afford to add another 100 milliseconds just to check if the user is allowed to make the request. The check must be near-instantaneous.
This is why we use Redis.
Redis is an in-memory key-value store.
Unlike a traditional database that writes to a hard disk, Redis keeps data in RAM. This allows it to read and update counters in microseconds. It is the industry standard tool for this specific problem.
Algorithm 1: The Fixed Window Counter
The Fixed Window algorithm is the foundational concept of rate limiting. It is the simplest to understand and the easiest to implement.
The Core Logic
The algorithm divides time into discrete, non-overlapping units called “windows.” A window could be one minute, one hour, or one day.
For every user, we maintain a counter that corresponds to the current window.
Identify the Window: When a request arrives, the system calculates the current time window. For example, if the time is 10:30:15 and the window size is 1 minute, the window identifier is
10:30.Check Counter: We look up the counter for this user and this specific window.
Increment and Decide:
If the counter does not exist, we create it and set it to 1.
If the counter exists and is below the limit, we increment it by 1 and allow the request.
If the counter has reached the limit, we reject the request.
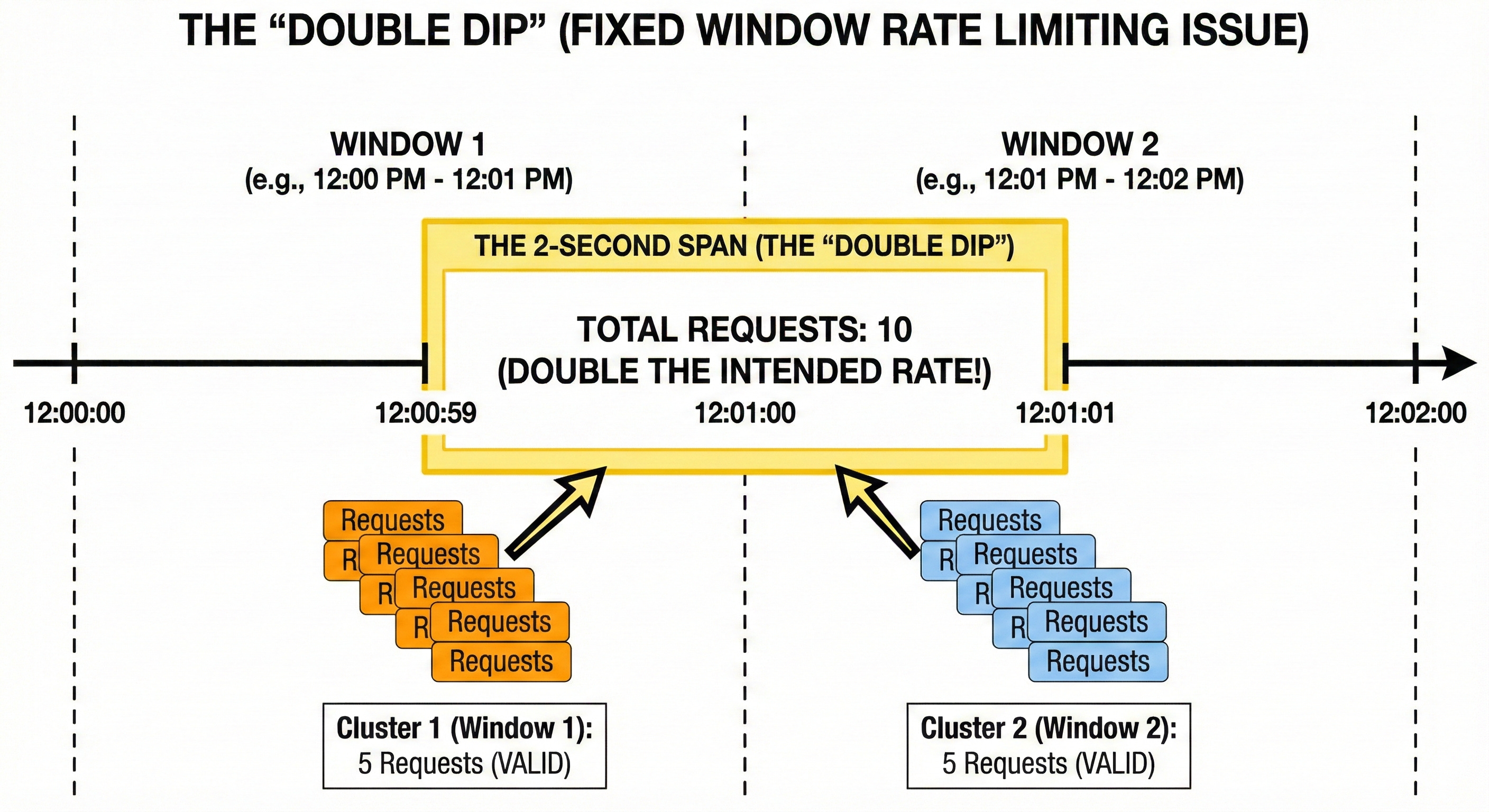
When the clock moves to 10:31:00, the system generates a new key for the 10:31 window. The counter starts fresh at zero. The old data effectively expires.
Redis Implementation
In Redis, this is extremely efficient. We can utilize the INCR (Increment) command.