
PostgreSQL vs. MongoDB vs. DynamoDB: A Technical Comparison
Stop guessing which database to use. Master the trade-offs between Relational (PostgreSQL), Document (MongoDB), & Key-Value (DynamoDB) systems. Learn about ACID transactions and Eventual Consistency.

This blog covers:
Comparing relational and non-relational models
Analyzing consistency versus availability trade-offs
Explaining vertical versus horizontal scaling
Selecting foundations for microservice architectures

Modern software systems eventually reach a critical tipping point where the volume of data exceeds the capacity of a simple storage solution.
At this juncture, the choice of a database engine shifts from a matter of preference to a matter of survival for the application.
A poor decision in the early stages of architecture can lead to insurmountable performance bottlenecks, data corruption, or expensive migration efforts years down the road.
Engineers often face the challenge of selecting between established relational systems and flexible non-relational alternatives without fully understanding the mechanical trade-offs involved.
The Core Problem: One Size Does Not Fit All
In the early days of software development, the decision was simple because the options were limited.
Today, the landscape is vast.
A database designed to execute complex mathematical reports is rarely the same database capable of handling millions of social media likes per second.
The primary friction point in system design is the trade-off between Consistency and Availability.
Consistency ensures that every user sees the exact same data at the exact same time. Availability ensures that the system stays online and accepts requests even if some parts of the network are broken. It is scientifically impossible to optimize for both perfectly in a distributed system.
To navigate this, we must examine the three most prominent contenders that define the modern backend stack: PostgreSQL, MongoDB, and DynamoDB. Each represents a distinct philosophy of data management.
PostgreSQL: The Relational Standard
PostgreSQL is a relational database management system (RDBMS). It is built on the concept of structured data and strict rules. It represents the “traditional” approach to storage, yet it remains one of the most advanced and reliable technologies available.
The Data Model: Tables and Relations
PostgreSQL organizes data into tables. You can visualize a table as a strict grid of rows and columns.
Before you can store a single byte of information, you must define a schema.
The schema is a contract. It dictates that a “Users” table must have a column for “Email” that only accepts text, and a column for “Age” that only accepts integers.
If you try to insert a user with a text-based age, the database rejects the operation.
This strictness is the greatest strength of PostgreSQL. It guarantees data integrity. You never have to worry about your code crashing because it expected a number but found a word.
Furthermore, PostgreSQL excels at relationships.
In a typical application, you might have Users, Orders, and Products. PostgreSQL allows you to store these in separate tables and link them together using unique IDs (Foreign Keys).
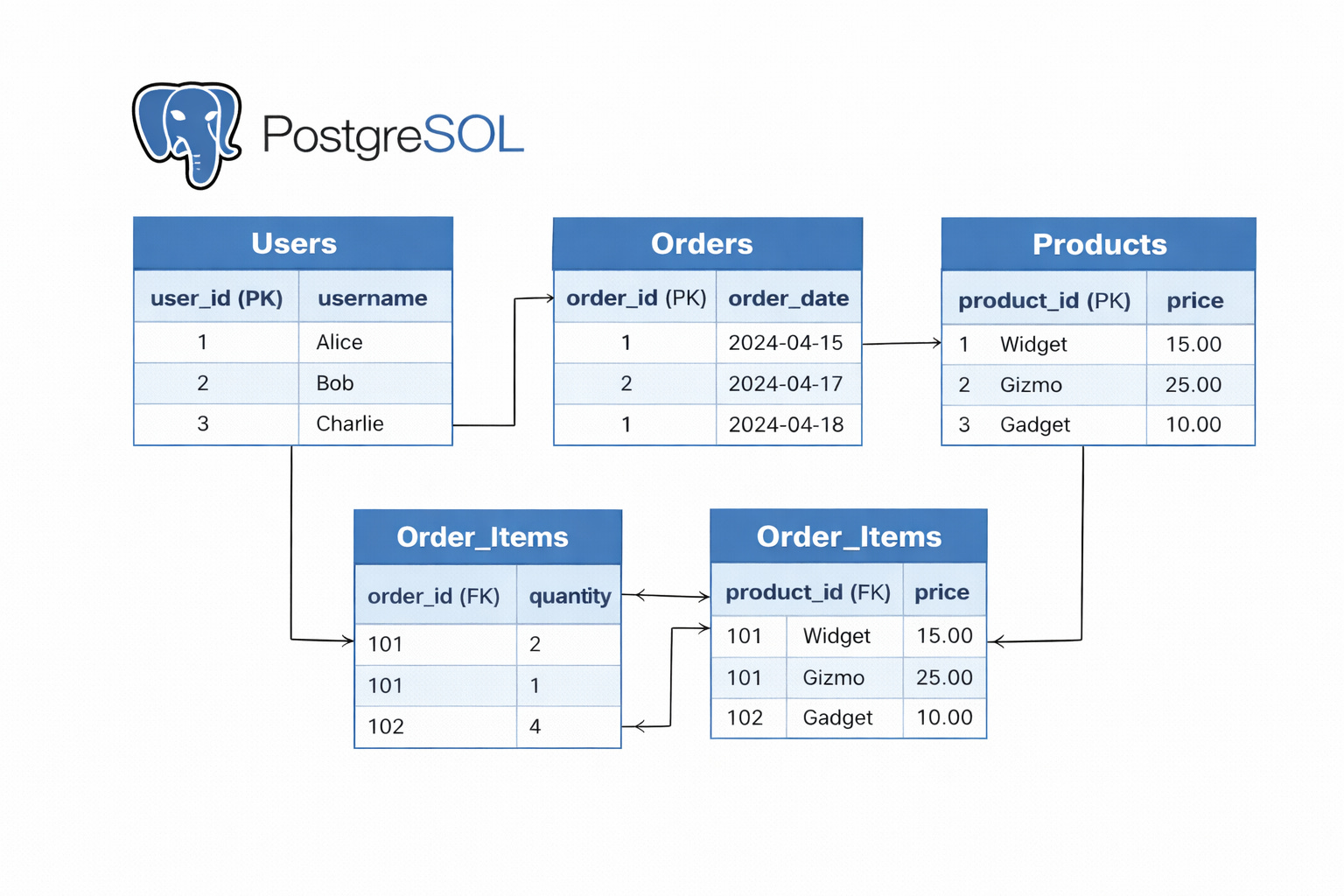
When you need to view a user’s history, you use SQL (Structured Query Language) to execute a “JOIN.” This command stitches the data from multiple tables together into a single view.
ACID Transactions
The defining feature of PostgreSQL is its adherence to ACID properties. This is critical for applications like banking or inventory management.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.