
SQL vs. NoSQL: The Definitive Decision Tree for System Design
Stop guessing which database to use. Master the trade-offs between SQL and NoSQL using our 4-step decision tree. Learn when to prioritize ACID over BASE and understand Horizontal Sharding.

Data persistence acts as the backbone of every software application.
While code defines the logic and behavior of a system, the database defines its memory.
If the storage layer is architected poorly, the application will eventually hit a wall. It might suffer from slow retrieval times, data integrity corruption, or an inability to handle increased traffic loads.
The modern developer faces a critical fork in the road at the very beginning of the system design process.
They must choose between the structured reliability of SQL (Relational) databases and the flexible scalability of NoSQL (Non-Relational) databases. This choice is often permanent.
Migrating data from one paradigm to the other in a live production environment is notoriously difficult and risky.
Therefore, the decision must be based on engineering logic rather than trends or personal preference.
This guide provides a structural framework for making that decision. It moves beyond simple definitions and offers a decision tree to help you navigate the trade-offs of system architecture.
Key Takeaways
Architectural Choice: Select SQL for structured, stable data requiring strict ACID consistency, and NoSQL for dynamic, unstructured data requiring flexible schemas.
Scalability Logic: SQL databases are optimized for Vertical Scaling (hardware upgrades), suitable for read-heavy loads, while NoSQL is built for Horizontal Scaling (sharding) to handle massive write-heavy traffic.
Query Complexity: Choose SQL when the system requires complex JOIN operations across multiple tables; choose NoSQL for self-contained data models that prioritize retrieval speed over relationship mapping.
Consistency vs. Availability: SQL favors strong consistency (immediate updates) for financial or critical data, whereas NoSQL favors eventual consistency (speed) for real-time feeds and logging.
Polyglot Persistence: Modern distributed systems should combine both paradigms, using SQL for transactional integrity and NoSQL for high-speed caching or analytics within the same architecture.
Let’s get started.
Part 1: The Core Contenders
Before analyzing the decision logic, it is necessary to understand the mechanical differences between the two technologies.
They differ not just in syntax, but in how they physically organize bytes on a disk.
SQL: The Relational Model
SQL stands for Structured Query Language. These databases rely on the Relational Model.
Data is organized into tables, which are grids composed of rows and columns.
The Schema: The defining characteristic of a SQL database is the schema.
A schema is a strict definition of the data structure. It acts as a contract between the application and the database.
You must define that a “User” consists of a “Name” (string), an “Age” (integer), and an “Email” (string).
The database will enforce this. It will reject any data that does not fit this shape.
ACID Compliance: SQL databases prioritize data integrity above all else. They adhere to a set of properties known as ACID:
Atomicity: Transactions are all-or-nothing. If a complex operation fails halfway through, the database rolls back to the previous safe state.
Consistency: Data is written only if it follows all defined rules and constraints.
Isolation: Multiple users can read and write simultaneously without seeing each other’s partial work.
Durability: Once the database confirms a save, the data is safe on the disk, even if the power fails one millisecond later.
Scaling: SQL databases typically scale Vertically. To handle more traffic, you must upgrade the single server hosting the database. You add more CPU, more RAM, or faster SSDs.
NoSQL: The Distributed Model
NoSQL databases emerged to solve specific problems that relational databases struggled with, particularly concerning massive scale and unstructured data.
Dynamic Schema: NoSQL databases are often Schema-less. You do not need to pre-define the structure. You can simply write a data object to the database.
One record might have three fields, and the next might have fifty.
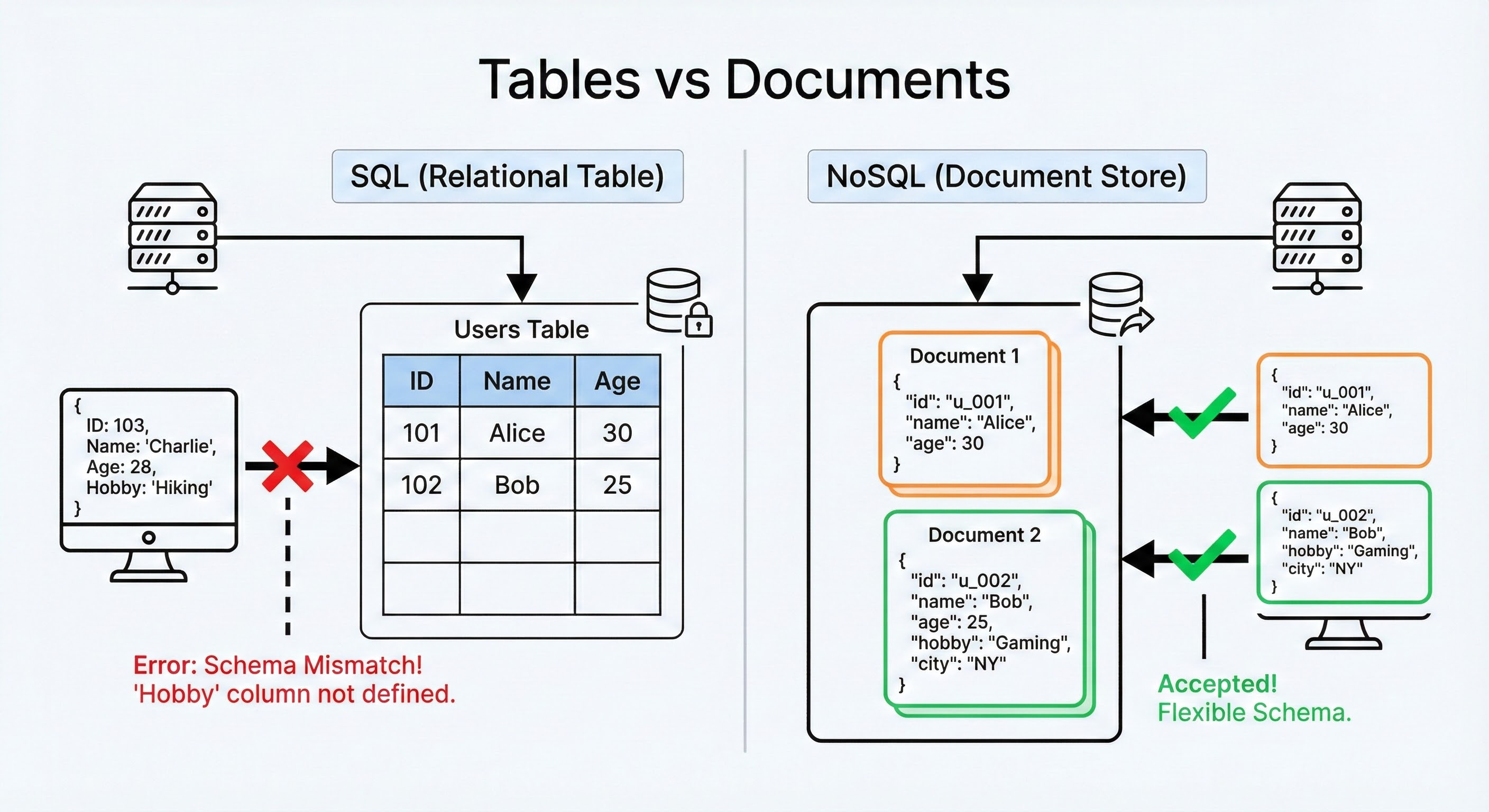
The database accepts the data as it is. This pushes the responsibility of data validation to the application code.
BASE Model: To achieve higher performance and scale, many NoSQL databases relax the strict consistency rules of SQL. They follow the BASE model:
Basically Available: The system ensures availability for incoming requests.
Soft State: The state of the system might change over time without input (due to synchronization).
Eventual Consistency: If the system receives no new updates, eventually all nodes will return the same data.
Scaling: NoSQL databases are designed to scale Horizontally. To handle more traffic, you do not buy a bigger computer. Instead, you add more computers to the cluster. The database automatically splits the data (sharding) across these multiple machines.
Part 2: The Decision Tree
When you are designing a system, do not guess.
Walk through the following logical branches to arrive at the correct architectural choice.
Branch 1: The Data Structure Analysis
The first and most critical question concerns the shape of the data itself.
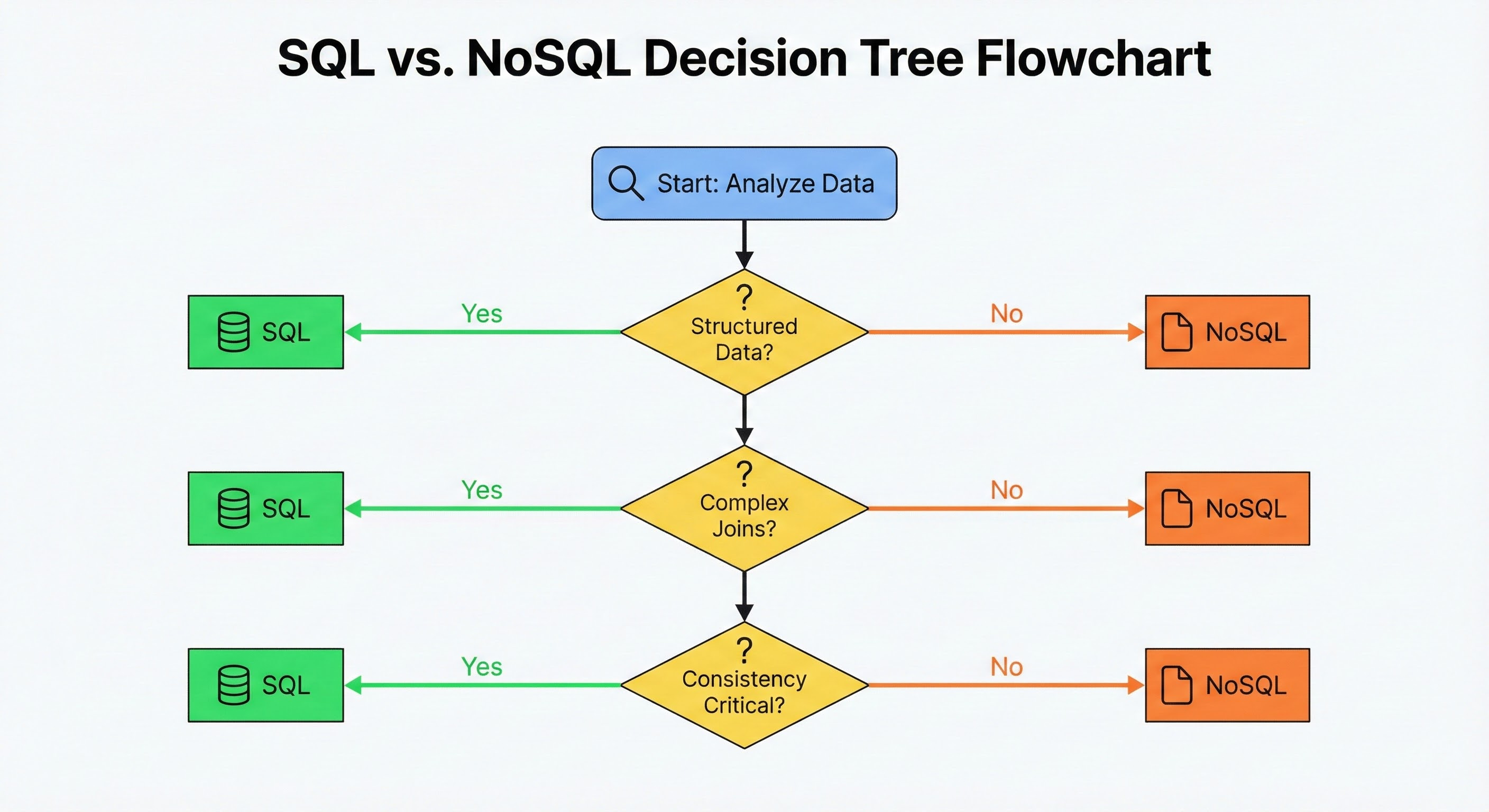
Question: Is your data structured and stable?
If your data fits neatly into rows and columns, and if the structure is unlikely to change frequently, SQL is the default choice.
“Structured” means every item has the same attributes.
For example, a system recording standardized logs where every log has a timestamp, a severity level, and a message ID is highly structured.
If your data is unstructured, semi-structured, or deeply nested, NoSQL is the superior choice.
“Unstructured” means the data varies significantly between records.
A product catalog is a prime example.
A “Laptop” product has attributes like “CPU” and “RAM,” while a “Shirt” product has “Size” and “Color.” Forcing these two different items into the same SQL table would result in a messy design with many empty columns.
A NoSQL Document store handles this variance naturally.
Decision:
Rigid, predictable data -> SQL
Variable, nested, or evolving data -> NoSQL
Branch 2: The Relationship Analysis
System design often revolves around how different data entities interact.
Question: Do you need to join data from multiple tables?
The superpower of SQL is the JOIN operation. It allows you to query relationships efficiently.
