
Hashing, Encryption, and Tokenization Explained: How Each One Protects Data Differently
Hashing, encryption, and tokenization all protect data differently. Learn how each one works, what makes them unique, and when to use which in system design.

In this post, we will cover:
How hashing protects stored passwords
Why encryption enables secure communication
What tokenization does for sensitive data
Key differences between all three
When to use which technique
Most security breaches do not happen because someone wrote bad code. They happen because someone stored sensitive data the wrong way.
Think about it. A system holds millions of credit card numbers, passwords, or personal records.
One day, an attacker gets access to the database. What happens next depends entirely on how that data was protected before the breach occurred.
This is where things get confusing for a lot of developers.
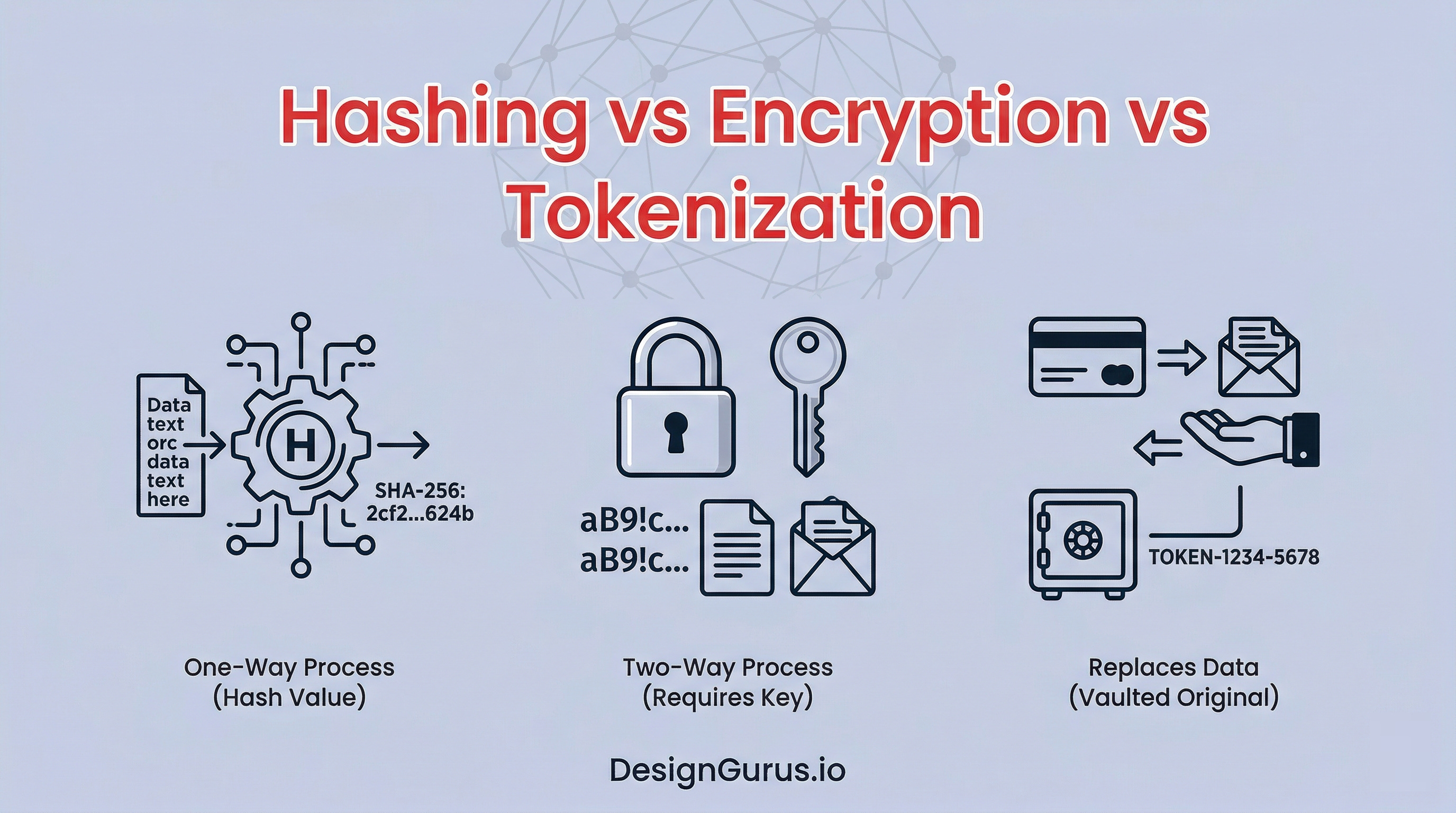
Hashing, encryption, and tokenization all deal with protecting data. They all transform readable data into something unreadable. But they do it in very different ways, for very different reasons.
And if you mix them up or use the wrong one, you could introduce serious vulnerabilities into your system.
The tricky part is that these three techniques look similar on the surface. You give them input, and they spit out something that looks like random nonsense.
But the mechanics underneath, and the guarantees they provide, are completely different.
Understanding when and why to use each one is not optional knowledge. It comes up in system design interviews, it matters when you are building real applications, and it is one of those things that separates someone who just writes code from someone who builds secure systems.
What is Hashing?
Hashing is a one-way transformation. You take some input data, run it through a hash function, and get a fixed-length output called a hash (sometimes called a digest).
The critical property here is that you cannot reverse it.
There is no way to take the hash and get back the original data.
Let me be more specific about what “one-way” means.
If you hash the word “password123”, you will get something like ef92b778.... But there is no function, no key, no algorithm that lets you start with ef92b778... and arrive back at “password123”.
The math simply does not work in that direction.
How Hashing Works Behind the Scenes
A hash function takes your input and processes it through a series of mathematical operations. These operations include bitwise shifts, modular arithmetic, and compression functions.
The input gets broken into fixed-size blocks, and each block is processed sequentially.
The output of processing one block feeds into the next.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.