
Crack the Toughest System Design Interviews with These 30 Advanced Concepts
Don't just design a URL shortener. Master the 30 advanced concepts needed for top-tier tech interviews.


The landscape of technical interviewing has shifted effectively over the last few years. There was a time when drawing a load balancer and a relational database on a whiteboard was enough to pass a system design round.
That era is largely over.
Top-tier technology companies now expect candidates to demonstrate a deep understanding of distributed systems.
They look for engineers who understand failure modes, data consistency challenges, and the intricate trade-offs involved in scaling applications.
Achieving this level of proficiency requires more than memorizing common buzzwords. It requires a mastery of advanced concepts and the ability to apply them in correct scenarios.
A candidate must know not just what a tool is, but exactly when it fails and when to use an alternative.
This guide covers thirty critical concepts that frequently appear in high-level system design discussions. It is structured to help you build a mental framework for making architectural decisions.
1. Ensuring Data Integrity and Verification
Data corruption or loss is unacceptable in large-scale systems.
Engineers need efficient ways to verify that data is consistent across different nodes without transferring massive files over the network.
Reading from a disk is slow; reading from memory is fast. Advanced data structures help bridge this gap.
Bloom Filters
A Bloom Filter is a probabilistic data structure used to test whether an element is a member of a set. It is highly space-efficient but has a specific limitation: it can tell you if an item is definitely not in the set or might be in the set.
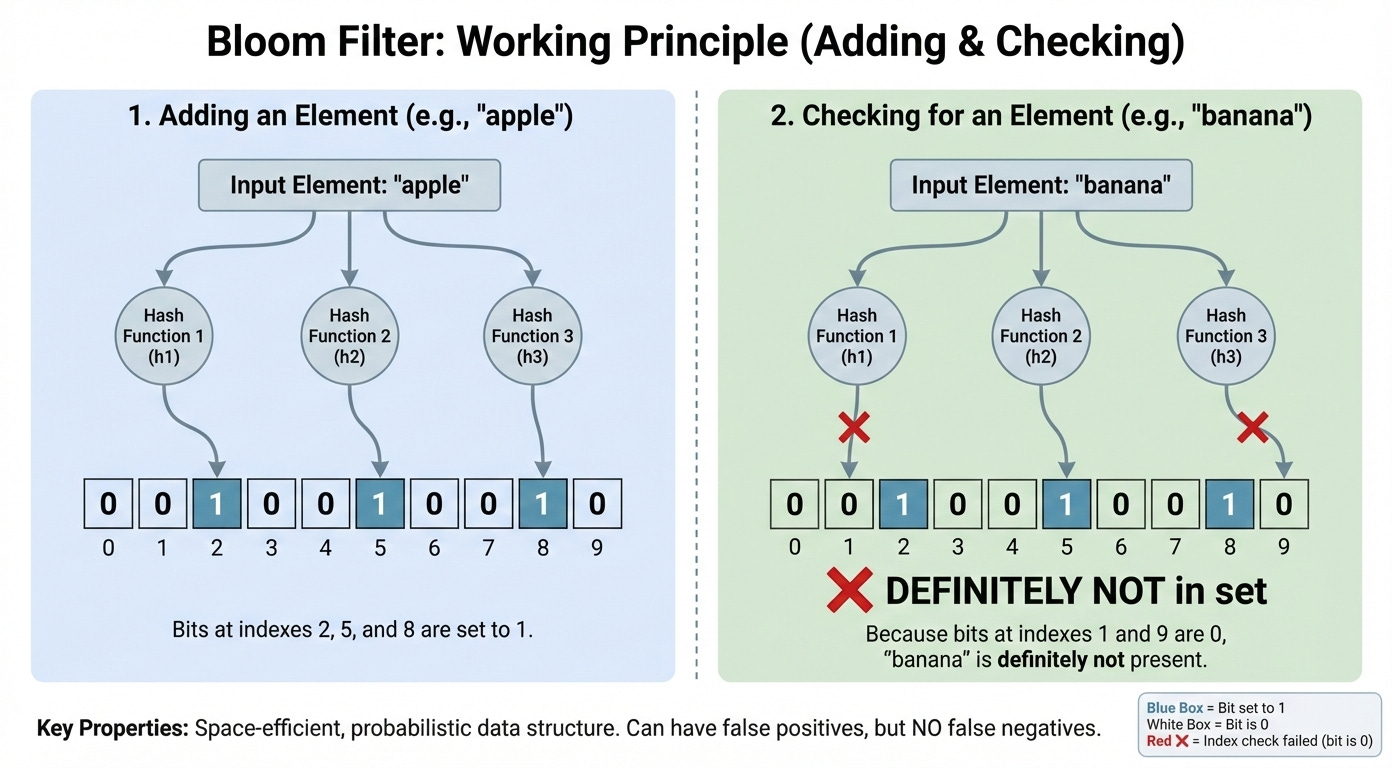
How It Works
The structure uses a large bit array and multiple hash functions. When an item is added, it is hashed by these functions, and the corresponding bits in the array are set to 1.
To check if an item exists, the system hashes it again. If all corresponding bits are 1, the item might be there. If any bit is 0, the item is definitely not there.
Merkle Trees
A Merkle Tree is a binary tree where every leaf node is labeled with the cryptographic hash of a data block. Every non-leaf node is labeled with the hash of the labels of its child nodes.
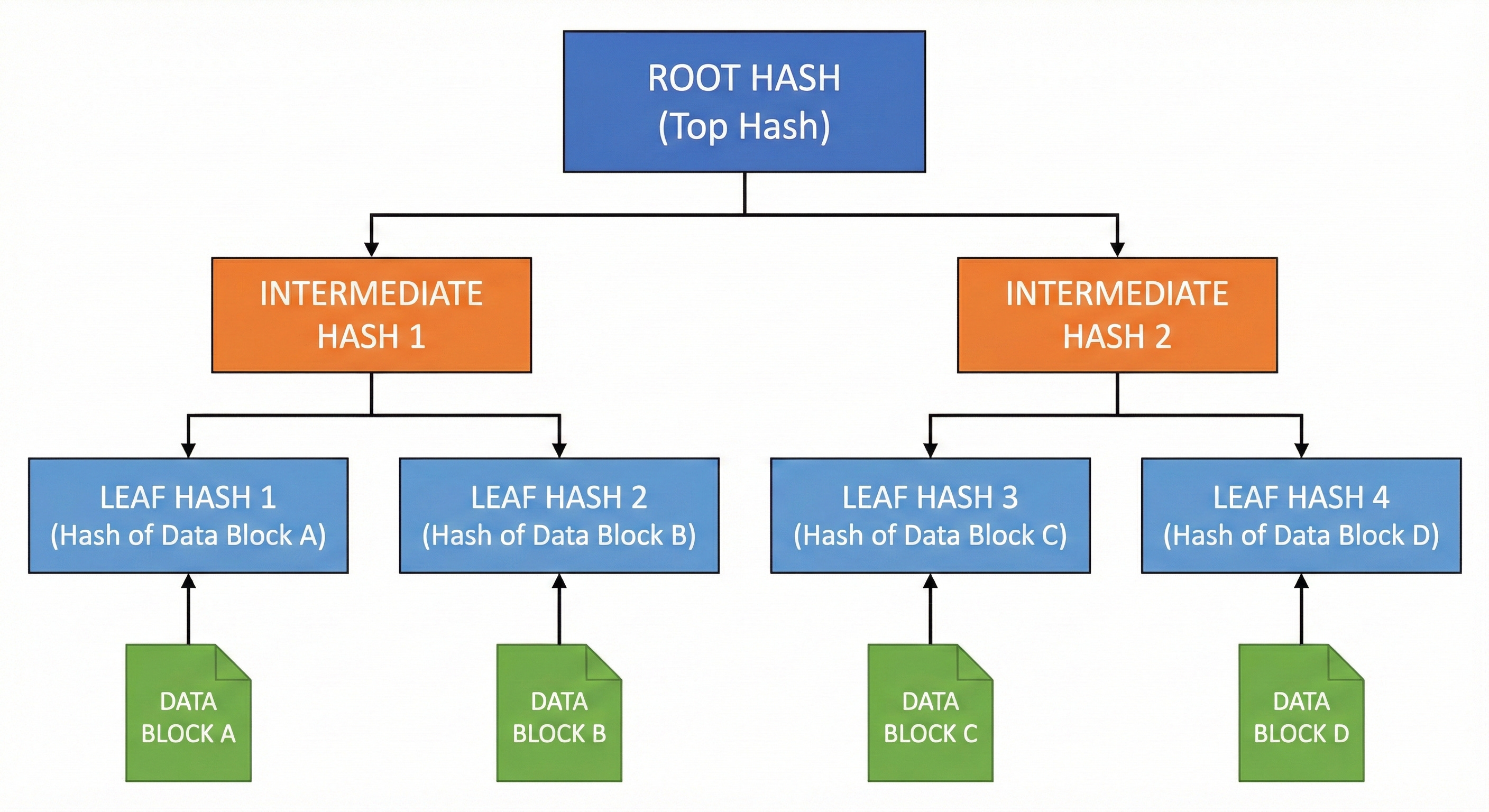
How It Works
When two systems need to compare data, they compare the root hash of the tree. If the root hashes match, the data is identical.
If they do not match, the systems compare the children of the root.
This process continues down the tree until the specific mismatched data block is identified.
This allows for efficient synchronization because only the modified data blocks need to be transmitted, rather than the entire dataset.
Decision Logic: Verification Strategy
IF you need to sync large datasets between distributed databases THEN use Merkle Trees.
IF you need to check for existence (e.g., username availability) without querying a disk THEN use Bloom Filters.
IF you need to count unique visitors on a site with billions of hits THEN use HyperLogLog.
Other Key Concepts
HyperLogLog: A probabilistic algorithm used to count unique items (cardinality) in a massive dataset with very little memory.
Count-Min Sketch: A structure used to estimate the frequency of events in a stream of data.
Checksums: Simple values calculated from a data block to detect errors during transmission.
Check out 50 System Design concepts.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.