
Complete Caching Guide for System Design Interviews [2026 Edition]
Master caching concepts for your next system design interview. Learn about eviction policies, distributed caching, and writing patterns plainly.


Modern software applications inevitably face severe performance bottlenecks regarding data retrieval.
When traffic scales to millions of concurrent network requests, primary databases struggle to process the massive volume of queries.
Traditional relational databases store persistent information on physical disk drives. Reading data from a physical disk requires complex electronic operations that consume significant computational time.
This inherent hardware limitation introduces high latency into the entire system architecture.
Latency is the total time delay between an initial network request and a final server response.
High latency causes slow loading screens, connection timeouts, and completely unresponsive software interfaces. If the backend architecture cannot process incoming traffic quickly, the database query queue rapidly overflows.
Once a database queue overflows, the primary servers reach maximum processor capacity and the platform crashes offline. Software engineering solves this massive retrieval bottleneck using a technical optimization called caching.
Caching fundamentally changes how and where an application stores frequently accessed structural information.
By migrating specific data from slow persistent disks to high-speed temporary memory, systems bypass the database entirely for repeated requests. This optimization is an absolute requirement for passing modern system design interviews.
What Exactly is Caching?
A cache is a specialized, high-speed data storage layer situated between the application code and the primary database. It temporarily stores a explicitly designated subset of data.
The primary goal is to serve future requests for that specific data exponentially faster than the main database can.
To understand why this is necessary, we must look at physical server hardware.
Permanent databases save data to solid-state drives or hard disk drives. Locating the correct data sector on these drives and transferring the binary code takes several milliseconds. In computer science, a single millisecond is a very long duration.
If a system must process twenty thousand queries simultaneously, a five-millisecond delay per query creates a massive backlog.
A cache actively eliminates this delay by storing data directly in Random Access Memory.
Random Access Memory is the temporary working memory installed directly on the server motherboard.
Reading structured data from this active memory takes mere nanoseconds rather than slow milliseconds.
A nanosecond is one billionth of a single second. However, this high-speed memory is strictly volatile.
If the cache server loses electrical power, all stored data is permanently erased.
Because of this volatility, a cache is never used as the permanent source of truth for critical information. It exists purely as a temporary performance layer. Furthermore, memory hardware is significantly more expensive than standard disk storage.
Therefore, cache servers possess strictly limited storage capacities and cannot hold the entire database.
How Caching Works Behind the Scenes
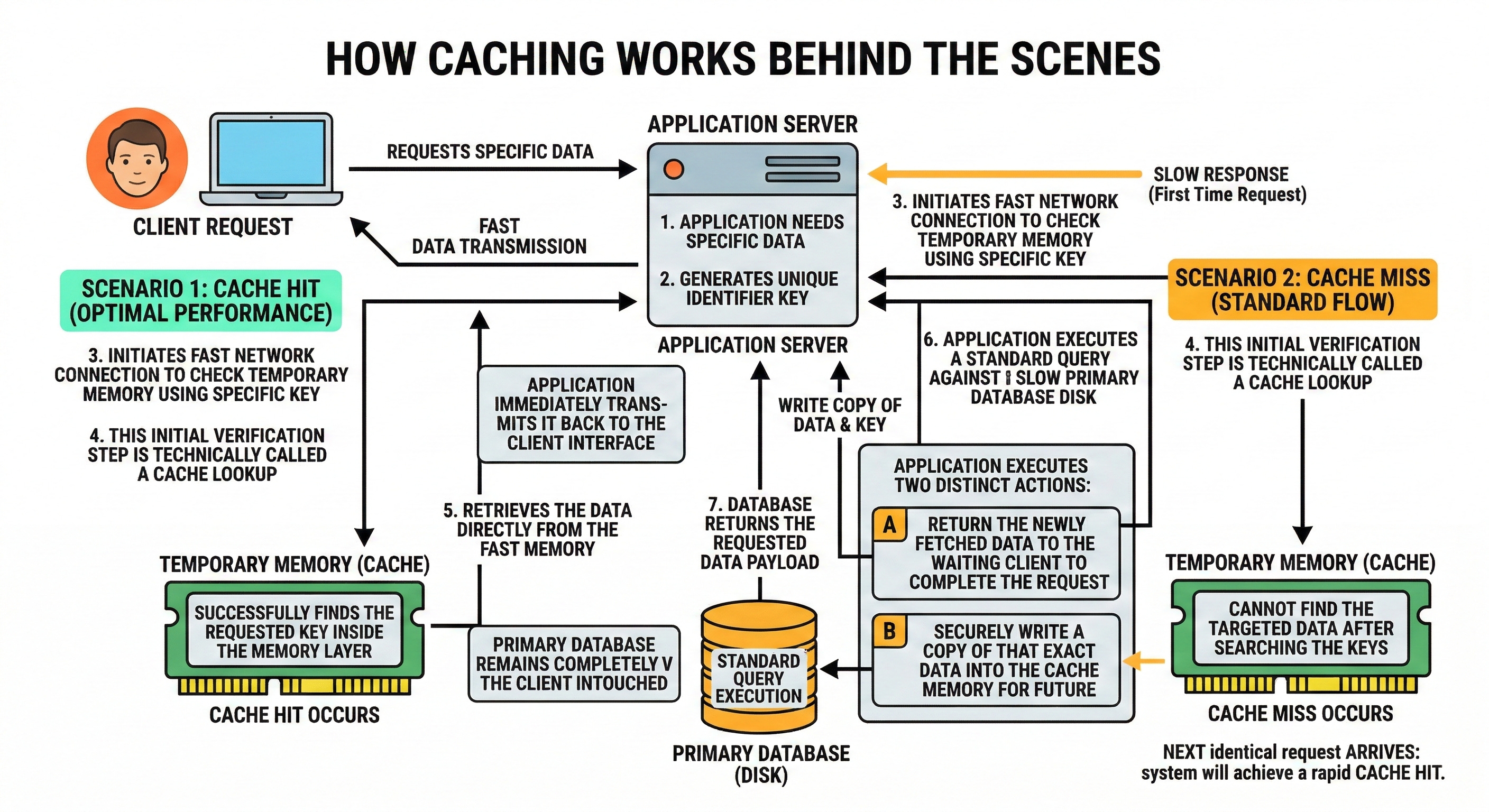
To build scalable architecture, you must understand the exact logical flow of a cached data request. When an application needs a specific piece of data, it generates a unique identifier key.
The application first initiates a fast network connection to check the temporary memory using this specific key. This initial verification step is technically called a cache lookup.
If the application successfully finds the requested key inside the memory layer, a cache hit occurs.
A cache hit is the optimal system scenario for maximizing overall performance. The application retrieves the data directly from the fast memory and immediately transmits it back to the client interface.
The primary database remains completely untouched during this entire transaction.
However, the specific data requested might not currently reside in the limited memory.
If the application searches the keys and cannot find the targeted data, a cache miss occurs. When a cache miss happens, the application must execute a standard query against the slow primary database disk.
Once the slow database returns the requested data payload, the application executes two distinct actions.
First, it returns the newly fetched data to the waiting client to complete the request.
Second, it securely writes a copy of that exact data into the cache memory for future use. The next time the identical request arrives, the system will achieve a rapid cache hit.
Where Can We Place a Cache?
In a massive distributed system, a cache does not exist in just one single central location. Engineers implement temporary memory storage at multiple different layers of the network architecture. Catching a request closer to the end user results in the fastest possible response time.
Client-Side Caching
The absolute fastest network request is the one that never actually leaves the device. Client-side caching occurs directly inside the web browser or mobile application of the user.
When a client application downloads static files like interface images or structural scripts, it saves a copy locally.
When the user navigates to a new page, the application loads these specific files directly from the local device storage. This entirely eliminates the need to establish a new network connection with the backend servers. It saves massive amounts of central server bandwidth and makes the interface load instantly.
Content Delivery Networks
A Content Delivery Network is a globally distributed network of specialized proxy servers. These servers are physically located in various geographic regions around the world.