
Caching for System Design: When to Use Redis as a Primary Database vs. a Cache
Stop treating Redis as just a cache. Discover how Sorted Sets and Streams make it a viable primary database.


Speed defines the success of modern software architecture. Applications must retrieve data in milliseconds to function correctly.
Traditional databases store information on hard disks or solid-state drives.
While these devices are reliable, they introduce latency because the system must physically or electronically locate data on a storage medium. This physical limitation creates a bottleneck for high-performance applications. Engineers solve this by using systems that store data directly in Random Access Memory (RAM).
Redis is the standard technology for this approach. It eliminates the delay caused by disk storage, allowing for near-instant data retrieval. However, it is capable of serving as more than just a temporary optimization layer.
Understanding the Core Architecture
To understand the decision between using Redis as a cache or a primary database, one must first understand how it handles data storage compared to traditional systems.
Most databases are disk-based.
When a user writes data, the database writes it to the hard drive. This ensures that if the power fails, the data remains safe.
The trade-off is speed. Writing to a disk is slow compared to the processing speed of the Central Processing Unit (CPU). The CPU works in nanoseconds, while the disk works in milliseconds. This difference creates a waiting period for the processor.
Redis is an In-Memory store. It keeps the entire dataset in RAM. The CPU can access RAM directly and instantly.
This architecture makes Redis significantly faster than disk-based alternatives. It can handle millions of operations per second because it eliminates the need to travel back and forth to the hard disk for every request.
However, RAM is volatile. By default, if the server restarts or loses power, all data stored in RAM is erased. This characteristic traditionally limits Redis to being used as a cache.
The Default Mode: Using Redis as a Cache
In a standard distributed system, a cache acts as a temporary data layer. It sits between the application and the primary disk-based database. This is the safest way to utilize memory storage because it does not risk data loss.
The Look-Aside Pattern
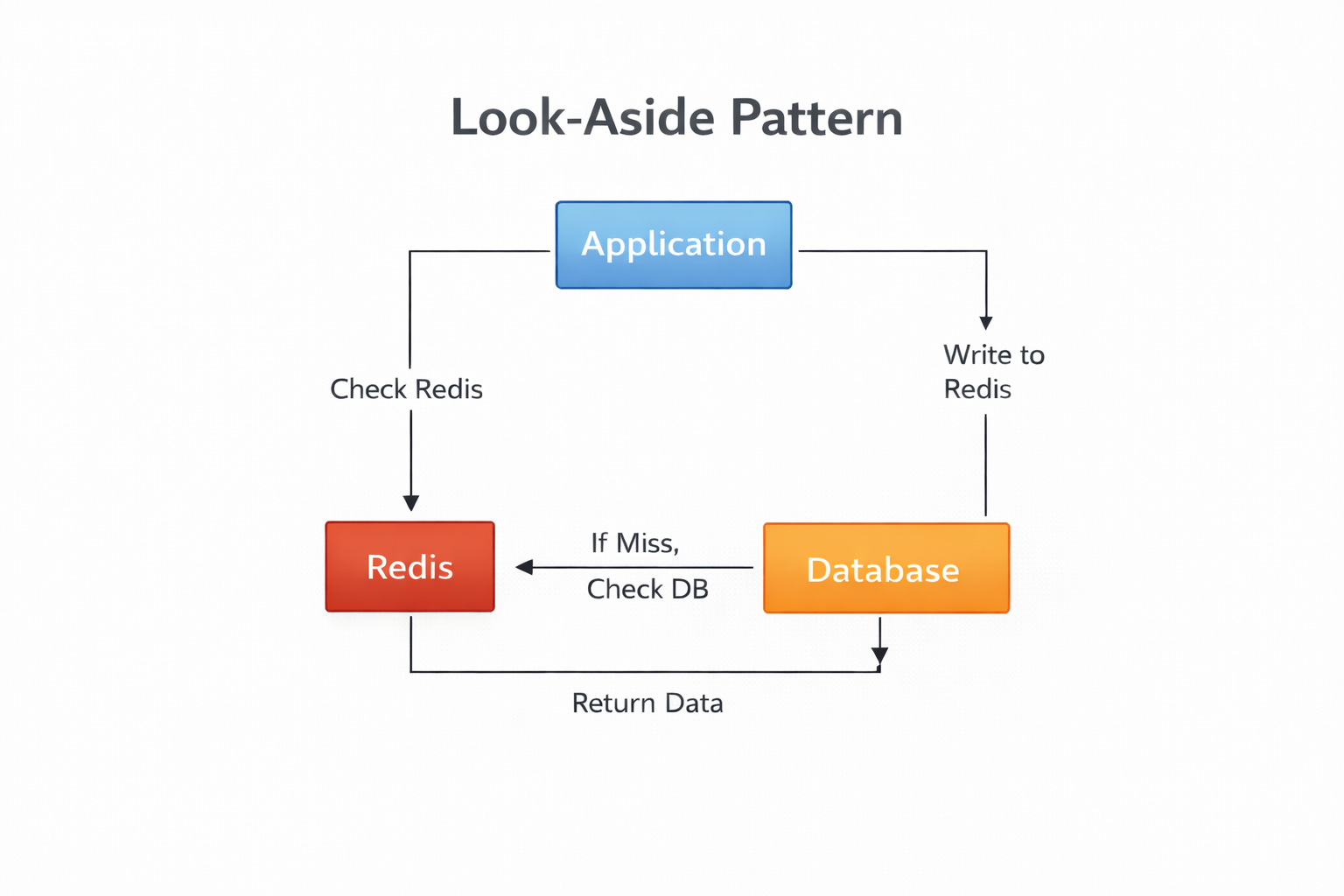
The most common configuration is the Look-Aside pattern. The process works as follows:
The application receives a request for a specific data key.
It checks Redis first.
If the data exists, it is returned immediately. This is a Cache Hit.
If the data does not exist, the application queries the persistent disk database. This is a Cache Miss.
The application retrieves the data, returns it to the user, and writes a copy to Redis for future requests.
Why This Works
This setup treats Redis as disposable. The “source of truth” is the disk database. If the Redis server crashes and loses all memory, the application remains functional. It simply experiences a temporary slowdown as it retrieves data from the disk again.
Designing for a cache is straightforward because data durability is not a requirement.
The system only needs to manage Eviction Policies, which decide what old data to delete when the memory becomes full to make room for new data.
The Shift: Redis as a Primary Database
Redis can function as a primary database when specific features are enabled.
A primary database acts as the single source of truth for the application. There is no secondary disk database behind it. The application writes directly to Redis and reads directly from Redis.
For this to be safe, the system must solve the problem of volatility. The data in RAM must be preserved even if the server restarts. Redis achieves this through Persistence.
Persistence is the mechanism of saving in-memory data to the hard disk.
Redis provides two distinct methods to handle this.