
Why Starting with Microservices Can Be Your Biggest Architectural Mistake
Learn why starting with microservices is often a mistake and why the “Monolith First” approach is the secret to faster, simpler software development.


In the world of software engineering, we have a habit of worshipping complexity.
We look at system architecture diagrams from Netflix, Uber, or Amazon, and we see thousands of tiny services talking to each other.
It looks impressive. It looks “professional.”
It is natural to think, “If I want to build good software, I should build it like Google does.”
This is one of the most common and most painful mistakes you can make.
When you try to copy the architecture of a trillion-dollar company for your startup or side project, you aren’t setting yourself up for success. You are setting yourself up for a nightmare of complexity that will kill your project before it even gets off the ground.
What works for a team of 5,000 engineers is often poison for a team of five.
Let’s talk about why Microservices are usually the wrong choice for beginners, and why the Monolith is actually your secret weapon.
What is a Monolith?
Before we bash microservices, let’s define the alternative.
A Monolith is an application where all your code lives in one place.
Think of it as a single giant folder on your computer.
Inside this folder, you have everything your app needs to run:
The code for logging users in.
The code for processing payments.
The code for sending emails.
The code for searching products.
When you run the app, it runs as one single process on a server. When you talk to the database, you usually talk to one big database.
This sounds “old school,” but it has a massive superpower: Simplicity.
When you want to find a bug, you look in one place.
When you want to update the app, you upload one file. When function A calls function B, it happens instantly because they are in the same memory space.
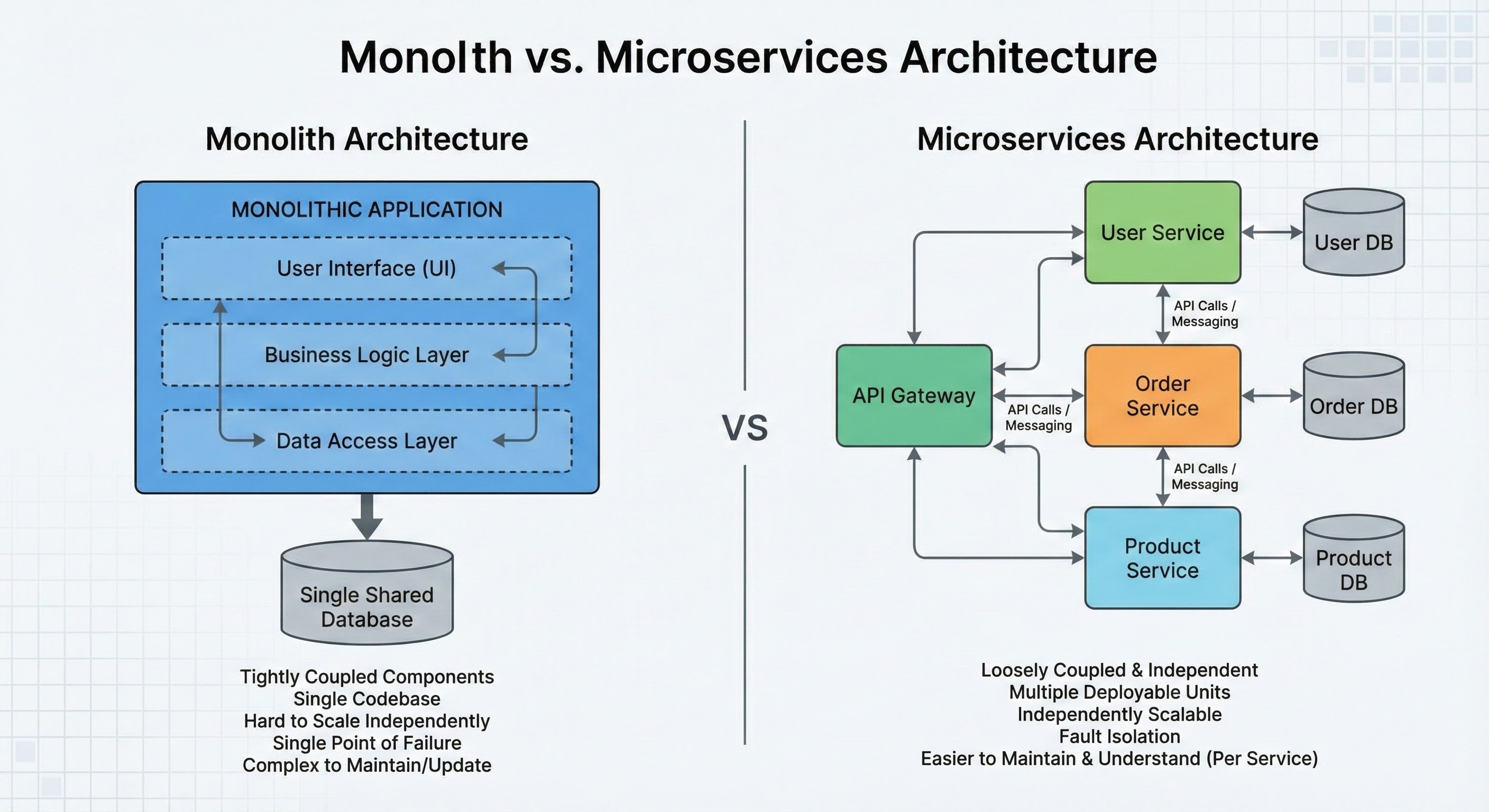
The Microservices Trap
Microservices are the opposite.
Instead of one big app, you break your features into tiny, separate apps.
You might have:
A User Service that only handles logins.
A Payment Service that only talks to Stripe or PayPal.
A Notification Service that only sends emails.
These services do not live together.
They run on different servers. They might even be written in different programming languages.
The User Service might be in Python, while the Payment Service is in Java.
On paper, this sounds great.
It sounds clean.
But in practice, especially for a new project, it introduces three nightmares that junior developers often do not expect.
Nightmare 1: The Network is Unreliable
In a monolith, if function A calls function B, it works 100% of the time unless your computer crashes. It is a simple function call.
In microservices, the User Service has to send a message over the internet to the Payment Service to ask for data.
The network is slow and it breaks.
What happens if the Payment Service is offline?
What happens if the internet cable is loose?
What happens if the request times out?
Now you have to write extra code to handle “retries.”
You have to write code to handle “timeouts.”
You have to guess if the payment failed or if just the message failed.
You have turned a simple function call into a complex distributed systems problem. You spend less time building features and more time fixing network issues.
Nightmare 2: The Data Problem
In a monolith, you have one database. This is a luxury.
If you want to find “All users who bought a Blue Shirt,” you write a simple SQL query.
You join the Users table with the Orders table. It is easy.
In microservices, the User Service has its own database.
The Order Service has a completely different database. You cannot join tables across different databases.
So how do you get that data?
First, you ask the Order Service for all orders with “Blue Shirt.”
It gives you a list of User IDs (like user_123, user_456).
Then, you have to go to the User Service and ask for the details for user_123, user_456, and so on.
You have to do the “join” inside your code, manually. It is slow, it is hard to code, and it is prone to bugs.
Nightmare 3: Operational Complexity
This is the one that burns out small teams.
With a monolith, you have one thing to deploy. You set up one server (or a few copies of it), and you are done.
With microservices, if you have 10 services, you have 10 things to deploy.
You need 10 build pipelines.
You need to monitor 10 different servers.
You need to check logs in 10 different places to trace a single error.
If you are a team of 5 people, do you really want to manage infrastructure for 20 different services?
You will spend all your day acting as a DevOps engineer instead of a product developer.
The Boundary Problem
There is a subtler reason why starting with microservices is dangerous. It is about knowledge.
When you start a new project, you do not know how the system should be split.
You might think, “I need a User Service and an Order Service.”
But six months later, you realize that Users and Orders are so tightly linked that they effectively act like one thing. Every time you change the User code, you break the Order code.
If you have already split them into microservices, fixing this is incredibly hard. You have to merge two separate deployed systems.
Refactoring a monolith is easy.
You just move files into different folders.
Refactoring microservices is hard.
You have to change API contracts, migrate databases, and coordinate deployments.
By starting with a monolith, you give yourself the freedom to learn what your system actually needs before you lock yourself into a rigid structure.
The Modular Monolith: A Middle Ground
So, does this mean you write messy spaghetti code?
No.
You should aim for a Modular Monolith.
This means you write your code in one big codebase, but you organize it beautifully inside. You create clear folders (modules) for your features.
/src/users/src/orders/src/payments
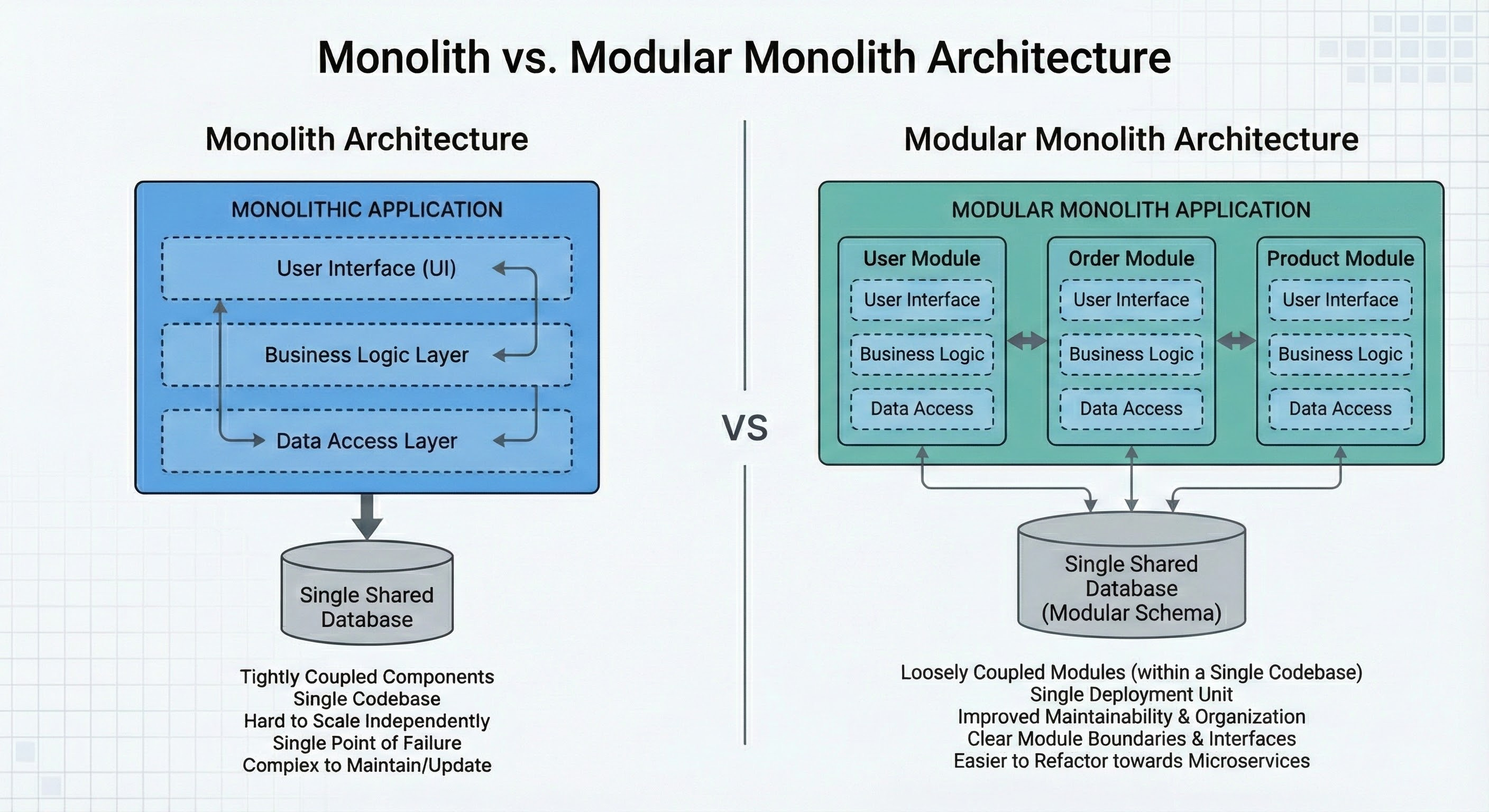
You make a rule: The code in orders should only talk to users through a clean public interface.
You pretend they are separate services, but you keep them in the same runtime.
This gives you the mental clarity of microservices without the operational headache.
If your app becomes wildly successful and hits 10 million users, you can simply take the /src/payments folder and move it to a new server.
You have already drawn the boundaries. But you waited until you actually needed to do it.
When Should You Use Microservices?
Microservices are not bad. They are just a solution to a specific problem: Scaling Teams.
You should consider moving to microservices when:
Your team is too big. If you have 100 developers working on one codebase, they might step on each other’s toes. Breaking the app allows Team A to work on Payments without worrying about Team B breaking the Login page.
You have different scaling needs. Maybe your Image Processing feature uses a massive amount of CPU, but your Login feature barely uses any. It makes sense to put Image Processing on a monster server and keep Login on a cheap server.
You need technology diversity. Maybe one specific feature works much better in C++ than JavaScript.
If you are a startup with 5 developers, or a student building a portfolio project, none of these apply to you.
Conclusion
System design is about trade-offs.
There is no “best” architecture, only the architecture that fits your current constraints.
For early-stage projects, your biggest constraint is time. You need to move fast. You need to iterate.
Microservices add friction. They slow you down with complexity that you do not need yet.
Key Takeaways:
Start Simple: Always default to a Monolith.
One Database: Keep your data in one place so you can use SQL joins.
Organize Code: Use folders and modules to keep code clean, not separate servers.
Don’t Optimize Prematurely: Do not solve scaling problems you do not have yet.
Wait for the Pain: Only switch to microservices when the pain of managing the monolith becomes greater than the pain of managing distributed systems.
Build the monolith first.
Linus was right on monolithic architectures being, generally, more useful to the end consumer and/or easier and simple to make, I believe the only *really* popular microkernel nowadays is Apple's Darwin, but even so, it has an entire freebsd userland/utils/whatever in one process, so... not really a microkernel, is it? kek
Shouldn't the decision also depend on the scale of the project. Like if the application has to handle million of users then microservices wouldn't be a better choice?