
Deconstructing Sharding: Consistent Hashing, Rebalancing, and Hot Keys
Unlock the secrets of backend database architecture by understanding how routing layers manage heavy network traffic and prevent server crashes.

Every growing software application eventually overwhelms its own database infrastructure.
A single database machine is strictly constrained by physical hardware limits. It only contains a specific amount of internal memory and a limited processor speed.
When network traffic surpasses these physical boundaries, the database simply stops accepting new connections.
The entire system slows down drastically and eventually crashes completely. Understanding how to bypass this physical hardware limit is a mandatory milestone for software engineers. Relying on a single machine is a guaranteed path to widespread system failure.
Engineering teams must learn how to distribute heavy computational workloads across multiple machines safely.
This is the only technical way to keep a massive application online during extreme traffic spikes. The core technical solution to this hardware limitation is called sharding.
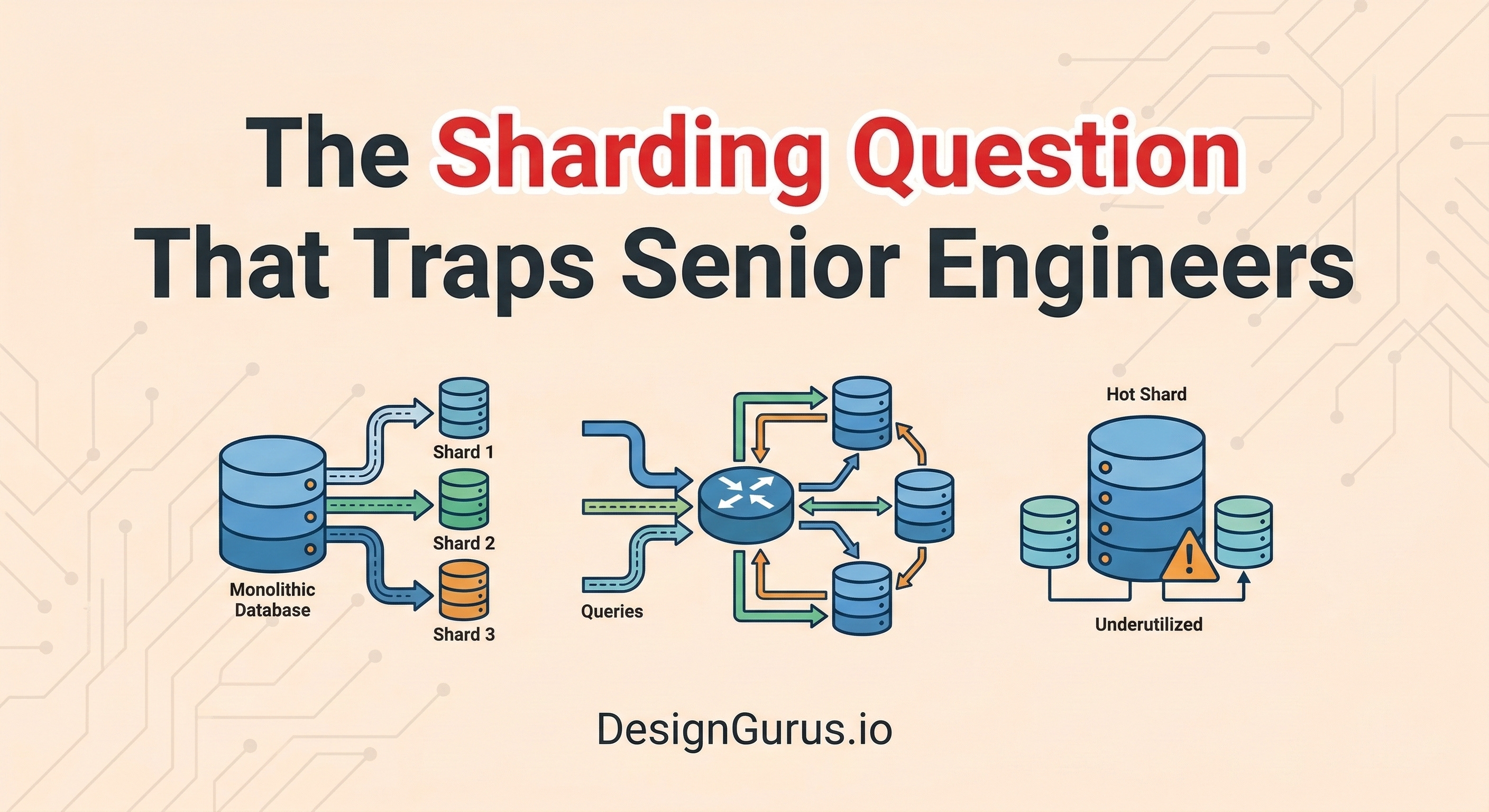
Sharding is the process of taking one massive database and breaking it apart into much smaller pieces. Each smaller piece of data is then placed on a completely separate physical server.
Instead of one giant server holding ten million data records, ten smaller servers might hold one million records each. When a new network request arrives, the backend architecture must mathematically determine which exact server holds the required information.
This automated routing process keeps the application running smoothly without overloading any single machine.
The Breaking Point of Single Servers
When a database runs out of resources, engineers often try to upgrade the physical machine first. They migrate the database to a much more expensive server with a faster processor and larger memory modules.
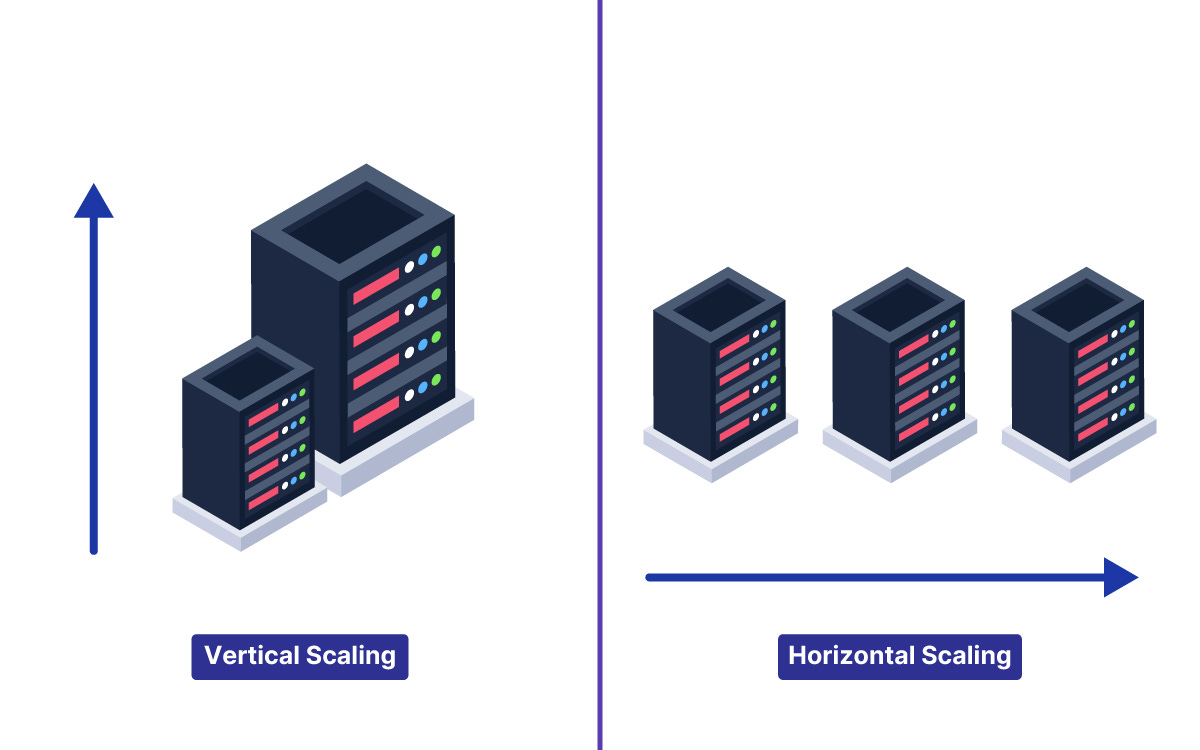
This hardware upgrading process is known as vertical scaling.
Vertical scaling is highly appealing because the underlying software code does not need to change at all.
However, vertical scaling has a severe and unbreakable mathematical limit.
Hardware components can only become so fast before they hit the absolute boundaries of physics. Even the most powerful enterprise servers in the world have a strict maximum capacity.
Furthermore, top-tier enterprise hardware becomes unbelievably expensive very quickly.
Because vertical scaling eventually becomes impossible, engineers must shift their architectural strategy completely.
Instead of purchasing one massive supercomputer, they connect dozens of standard servers together over a network. This alternative approach is called horizontal scaling.
Scaling horizontally is incredibly powerful because there is practically no theoretical limit to how many servers can be added.
The true engineering challenge lies in making all these independent servers work together seamlessly. The application must view this massive cluster of separate servers as one single unified database.
Defining the Core Partitioning Concept
When applying horizontal scaling to a database, the system needs a strict set of rules to route data. The system must decide exactly where every single piece of data belongs.
The database relies on a specific data column to make this crucial routing decision. This chosen column is called the partition key.
A partition key is a unique identifier attached to every single data record. Every time the application saves or requests data, it examines this specific partition key. The backend routing layer uses the key to figure out the exact destination server.
Engineers must choose a mathematical strategy to map these partition keys to physical servers. This chosen strategy is called a partitioning strategy.
If the engineering team chooses the wrong strategy, the entire cluster will collapse under heavy network load.
A poor strategy will accidentally force one single server to handle all the incoming traffic.
Meanwhile, the other servers in the cluster will sit completely empty and idle.
A perfect strategy ensures that every server stores the exact same amount of data and processes the exact same amount of work.
Analyzing Range-Based Partitioning
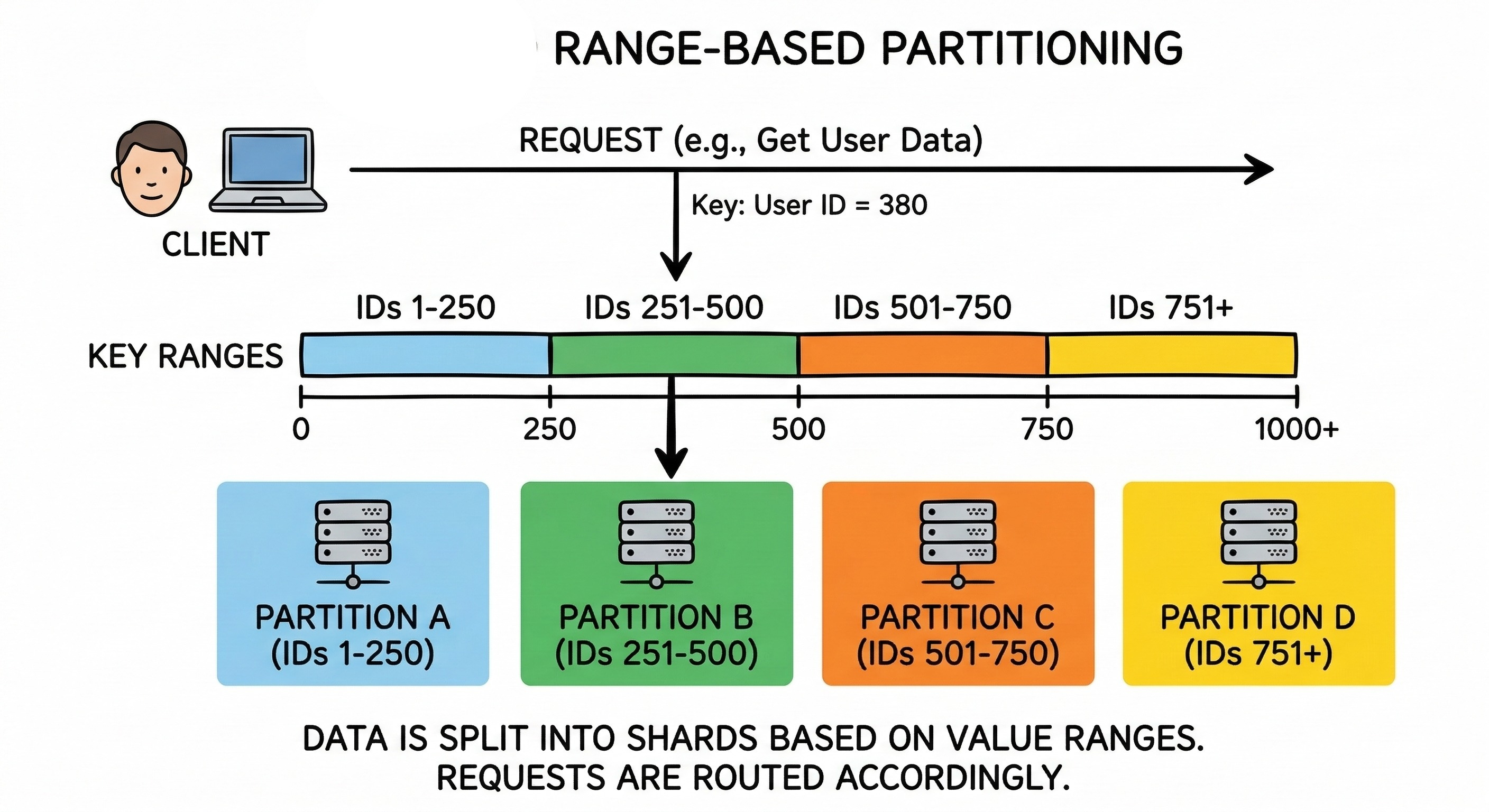
The most basic way to divide data is by creating sequential numerical boundaries. This simple strategy is formally known as range partitioning.
In this approach, engineers assign a specific minimum and maximum value to every individual server in the database cluster.
If an application manages numerical data records, the system can divide them very cleanly.
The first server might store all identification numbers from one to one million. The second server might store all identification numbers from one million and one to two million. The third server handles the next sequential block of one million numbers.
This organized strategy makes searching for data incredibly fast and efficient. The routing layer immediately knows exactly which server holds the required information without doing any complex math.
If the application needs to read a sequential list of records, it can pull them all from a single server instantly.
The Danger of Sequential Writes
Despite the fast read speeds, range partitioning hides a catastrophic architectural flaw. Data is almost never created or accessed perfectly evenly over time.
A major technical issue arises when databases use sequential numbers or timestamps as their partition keys.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.