
The Developer’s Guide to LLMs: From Magic to Math
Master the fundamentals of building with AI. A technical guide on how to integrate LLMs into your system design, covering latency, state, and cost.


If you have been coding for more than a few years, you remember the bad old days of chatbots.
You probably built one. It was a rite of passage.
You wrote a giant list of if-else statements.
If the user typed “shipping,” you showed the shipping status. If they typed “where is my package,” you showed the shipping status.
But if they made a typo or used a slang word you did not anticipate, your bot broke. It would reply with that frustrating default message: “I’m sorry, I didn’t catch that.”
It felt brittle. It felt like you were trying to hard-code human conversation, which is impossible because human conversation is messy and unpredictable.
Then, almost overnight, everything changed.
We now have software that can write poetry, debug complex SQL queries, and summarize legal documents. It handles typos effortlessly. It understands context. It feels less like a computer program and more like a person.
For a Junior Developer or a complete beginner, this shift can feel overwhelming.
You might feel like the ground is shifting under your feet. You spent years learning strict logic, boolean algebra, and deterministic algorithms.
Now, the most important technology in the world seems to operate on fuzzy logic and probability.
This post is here to tell you that it is not magic. It is just a different kind of math.
If you want to build the next generation of apps, you need to understand what is happening under the hood.
We are going to strip away the hype and look at the engine.
The Core Concept: The Fancy Autocomplete
Let’s start with the absolute most important thing you need to understand.
A Large Language Model (LLM) is a prediction engine.
That is it.
It does not have a database of facts hidden inside it.
It does not “know” the capital of France in the way a SQL database knows a row in a table. It does not have consciousness.
It is simply playing a game of “guess the next word.”
Think about the autocomplete bar on your phone. You type “I am going to the,” and your phone suggests “store,” “park,” or “movies.” It makes these suggestions because it has seen you type these sentences before. It knows that, statistically, “store” is a likely follow-up.
An LLM is the same concept, but scaled up to a massive level.
It has read the entire public internet. It has read Wikipedia, Reddit, GitHub, and thousands of books. Because it has seen so much text, it has built a complex statistical map of how words fit together.
When you ask it a question, it is not looking up an answer. It is calculating the probability of the next word.
Input: “The capital of France is”
Model’s Calculation:
“Paris”: 99.1% probability
“Lyon”: 0.5% probability
“Burger”: 0.00001% probability
It picks “Paris” because that is the pattern it has learned.
This explains why LLMs can “hallucinate” (make things up).
If you ask it for a biography of a fake person, it will not tell you “I don’t know.”
Instead, it will write a biography that looks real. It will predict words that usually appear in biographies, like “born in,” “graduated from,” and “awards.”
The sentences will be grammatically perfect, but the facts will be total fiction.
The model is fulfilling its only goal: predicting the next likely word.
The Vocabulary: Tokens
As a developer, you know that computers cannot read English. They can only process numbers.
Before an LLM can read your prompt, we have to translate it.
We chop your text into small chunks called tokens.
You might assume a token is just a word. Sometimes it is.
The word “apple” is one token. But complex words are often split into multiple tokens.
The word “implementation” might be split into “implement” and “ation.”
Even spaces and punctuation marks count as tokens.
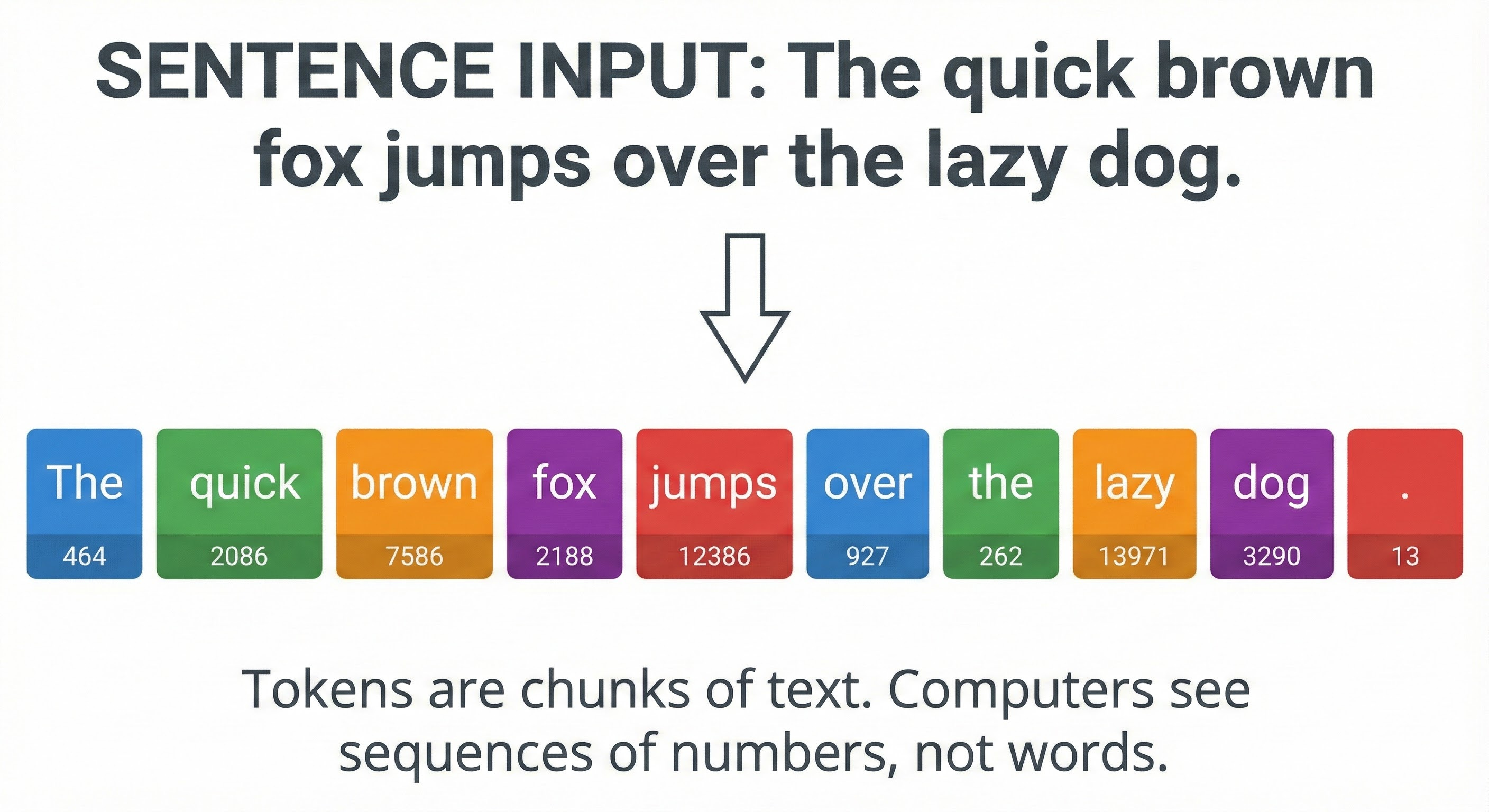
A good rule of thumb for your system design calculations is that 1,000 tokens is roughly equal to 750 words.
When you use an API from OpenAI or Anthropic, you are billed by the token. This is why concise prompting is actually a cost-saving measure in large-scale architecture.
How It Understands Meaning: Embeddings
Once we have our tokens, we convert them into a list of numbers.
But how does the computer understand that “King” is related to “Prince”?
We use a concept called Embeddings.
