
The Core Technical Principles of Distributed Software Systems
Learn the unwritten rules of system design discussions. This beginner guide covers software architecture, data scaling, and fault tolerance.

This blog will explore:
Uncover hidden architectural expectations.
Learn massive horizontal scaling.
Prevent catastrophic server crashes.
Navigate strict technical tradeoffs.

Building software for a single computer is vastly different from engineering a platform that handles millions of simultaneous actions.
The overarching technical problem is that systems fundamentally break when network traffic suddenly spikes. Without proper architectural planning, databases lock up, servers run out of memory, and the entire platform completely goes offline.
This catastrophic digital failure represents the exact problem that system design discussions aim to solve.
These high-level meetings exist to predict and prevent digital collapse before any actual code is written. Understanding the unwritten rules of these discussions separates fragile applications from highly resilient platforms. It is critical to grasp these foundational concepts to engineer software that scales flawlessly.
Rule One: Define The Mathematical Boundaries
Functional Versus Non-Functional Requirements
Junior developers often select databases immediately when given new projects.
The first unwritten rule is to avoid technical choices until the boundaries are firmly set. Engineers must define the operational limitations of the planned software.
We divide these strict boundaries into two distinct categories to organize the planning phase.
The initial category focuses strictly on the functional requirements of the software architecture. These requirements explicitly define the precise technical actions the application must be able to perform successfully.
A functional requirement dictates that a system must accept a text payload and securely store it. It essentially outlines the absolute baseline behaviors required for the core software to operate correctly.
The second category encompasses the non-functional requirements, which dictate how well the system performs under extreme stress. These requirements involve strict mathematical calculations regarding processing speed and concurrent network connections.
Engineers must calculate exactly how many network requests the application will realistically receive every single second.
Without establishing these precise mathematical constraints, designing a functional and stable architecture is literally impossible.
What Happens Behind The Scenes
A database configured to handle ten operations per second will instantly melt down when forced to process ten thousand operations. Determining these exact mathematical limits early ensures the engineering team selects the correct technical components.
If the system must handle massive video files, engineers will build a fundamentally different storage architecture than if it handles tiny text messages. Setting these boundaries prevents the team from building a fragile system that collapses under heavy load.
Rule Two: Eliminate Every Single Point Of Failure
The Certainty Of Hardware Destruction
Hardware components in massive data centers break down continuously and without any warning.
The next unwritten rule is that engineers must design the entire architecture under the strict assumption that every individual component will eventually break. An architecture is only considered successful if it can survive physical hardware destruction without going offline.
Beginners frequently design software systems that rely entirely on one single server or one central database to process everything.
This highly fragile design pattern introduces a dangerous single point of failure into the digital ecosystem.
A single point of failure is any piece of hardware that will bring down the entire application if it breaks. Professional system design strictly forbids creating these vulnerabilities anywhere within the technical architecture.
Implementing Strict System Redundancy
To completely eliminate these dangerous vulnerabilities, engineers implement a critical technical strategy called redundancy.
Redundancy involves deploying multiple duplicate versions of every single hardware and software component within the network system.
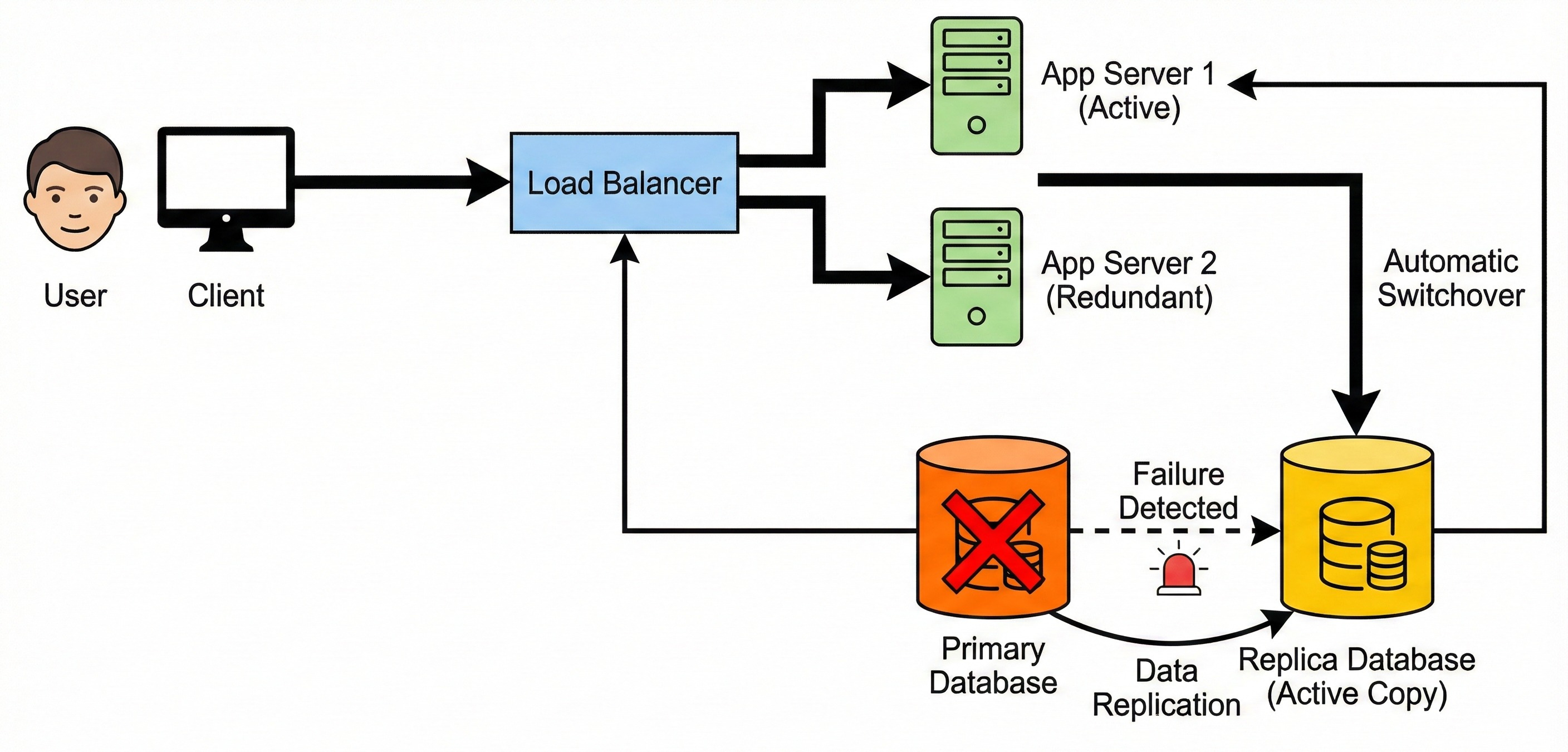
Instead of relying on one active application server, the highly resilient architecture utilizes five identical servers running simultaneously.
Behind the scenes, this duplicate server setup guarantees continuous system operation during unexpected hardware disasters.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.