
The Complete System Design Roadmap for 2026
The Definitive System Design Roadmap for 2026, Built to Take You From Fundamentals Through Distributed Systems and Into the AI Era


System design is one of the broadest subjects in software engineering. It spans networking, databases, distributed systems, reliability engineering, and now machine learning infrastructure.
The sheer size of the field is what makes it intimidating.
A person who wants to learn it faces hundreds of disconnected topics with no obvious starting point and no clear order.
Most people respond by learning in fragments. They read about caching one week, watch a video on microservices the next, and skim an article on the CAP theorem after that.
This produces a collection of isolated facts that never combine into real understanding, because system design knowledge is deeply layered.
The advanced topics only make sense once the building blocks are clear, and the building blocks only make sense once the fundamentals are solid.
A roadmap fixes this by putting the learning in the right sequence. Each stage builds on the one before it, so knowledge accumulates instead of scattering.
A roadmap also makes the size of the field manageable, turning an overwhelming subject into a series of concrete steps.
This matters more in 2026 than ever, because the field has expanded to include AI systems, real-time architectures, and cost-aware design on top of the classical foundations.
This roadmap lays out the complete path in eight stages, from the prerequisites of how the web works to the modern demands of AI infrastructure.
Each stage explains the key concepts, why they matter, and how they connect to the rest. It is built to be followed in order, and it is written for engineers at any level who want a single structured path through the entire field.
Stage 0: The Prerequisites
Before any system design concept makes sense, the basics of how computers communicate must be in place.
Skipping this stage is the most common reason later topics feel confusing.
The first prerequisite is understanding the client-server model.
A client, such as a browser or mobile app, sends a request to a server, which processes it and returns a response.
Every web system is a variation on this exchange. When a user types a web address, the Domain Name System, or DNS, translates that human-readable name into an IP address, the request travels over the network using the HTTP protocol, the server does its work, and a response comes back.
The second prerequisite is basic networking. TCP is a reliable, ordered connection used by most web traffic, while UDP is faster but does not guarantee delivery, which suits video and gaming.
HTTP runs on top of TCP, and HTTPS adds encryption. Knowing the difference between these explains why certain design choices exist later.
The third prerequisite is an intuition for the relative speed of operations, because system design is largely about avoiding slow operations.
Reading from memory takes around 100 nanoseconds.
Reading from a fast solid-state drive takes around 100 microseconds, which is roughly a thousand times slower.
A network round trip within one data center takes around half a millisecond, while a round trip between continents can take over 100 milliseconds. These numbers shape every decision about where to put data and how to move it.
Caching, content delivery networks, and replication all exist because some operations are thousands of times slower than others.
For a comprehensive study on system design fundamentals, check Grokking System Design Fundamentals.
Stage 1: Core Principles
With the prerequisites in place, the next stage covers the principles that underlie every design decision. These are the lenses through which all systems are evaluated.
Scalability is the ability to handle growth.
There are two approaches.
Vertical scaling means using a more powerful machine, which is simple but has a hard ceiling.
Horizontal scaling means adding more machines, which has no ceiling but requires the system to coordinate work across them.
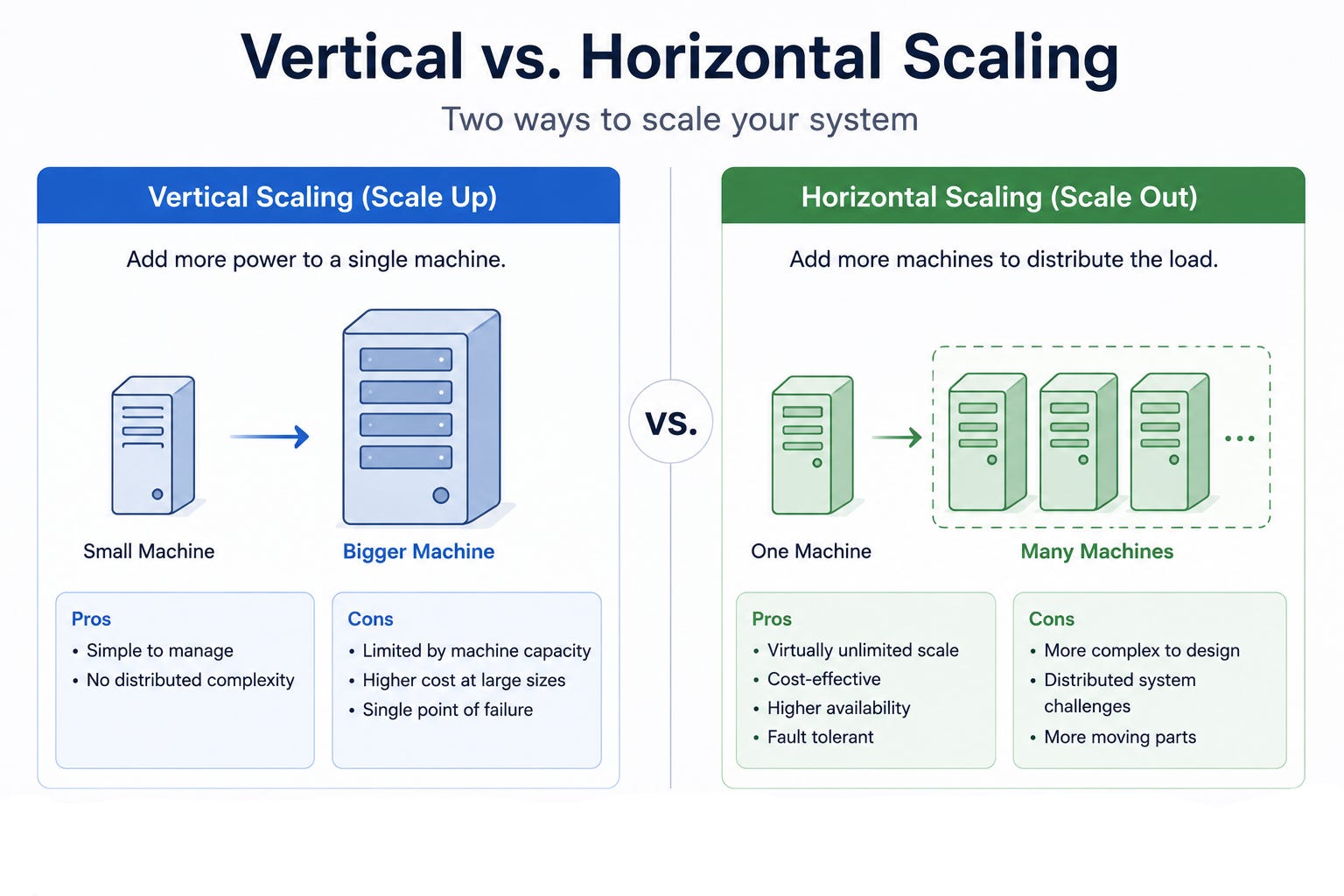
Modern large systems rely on horizontal scaling, which is why so much of system design is about distributing work and data.
Availability measures how often a system is up and responding. It is expressed as a percentage of uptime.
The difference between levels is large in practice.
A system at 99.9 percent availability is down for about 8.7 hours per year, while a system at 99.99 percent is down for only about 52 minutes per year.
Higher availability is achieved through redundancy, meaning extra copies of components that take over when one fails.
Reliability is related but distinct. It measures whether the system produces correct results. A system can be available but unreliable if it responds quickly with wrong answers.
Latency and throughput are two different measures of performance.
Latency is the time to complete a single request.
Throughput is the number of requests handled per second. These are independent, and optimizing one can hurt the other.
A system that batches requests together can achieve high throughput while increasing the latency of each individual request.
Consistency describes how synchronized data is across copies.
Strong consistency means every read returns the latest write.
Eventual consistency means copies will agree over time but may briefly differ.
The CAP theorem captures the core constraint: during a network partition, a distributed system must choose between consistency and availability.
The often-ignored extension, PACELC, adds that even without a partition, there is a trade-off between latency and consistency.
Underneath all of these principles sits the single most important habit in system design, which is trade-off thinking, the recognition that every choice gains something and gives up something else.
Stage 2: The Building Blocks
This stage covers the components that appear in nearly every system. Mastering these is what allows a person to design real systems, because almost every architecture is an assembly of these parts.
A load balancer sits in front of multiple servers and distributes incoming requests across them. It can operate at the network level or the application level, and it uses algorithms such as round robin, least connections, or hashing to decide where each request goes.
Load balancing only works cleanly when the servers are stateless, meaning any server can handle any request.
Databases divide into two broad families.
SQL databases store structured data in tables with strict rules and support powerful queries and transactions that guarantee correctness.
NoSQL databases trade some of that structure and consistency for flexibility and easier horizontal scaling.
NoSQL itself has four common shapes: key-value stores for simple fast lookups, document stores for flexible records, wide-column stores for massive scale, and graph databases for relationship-heavy data.
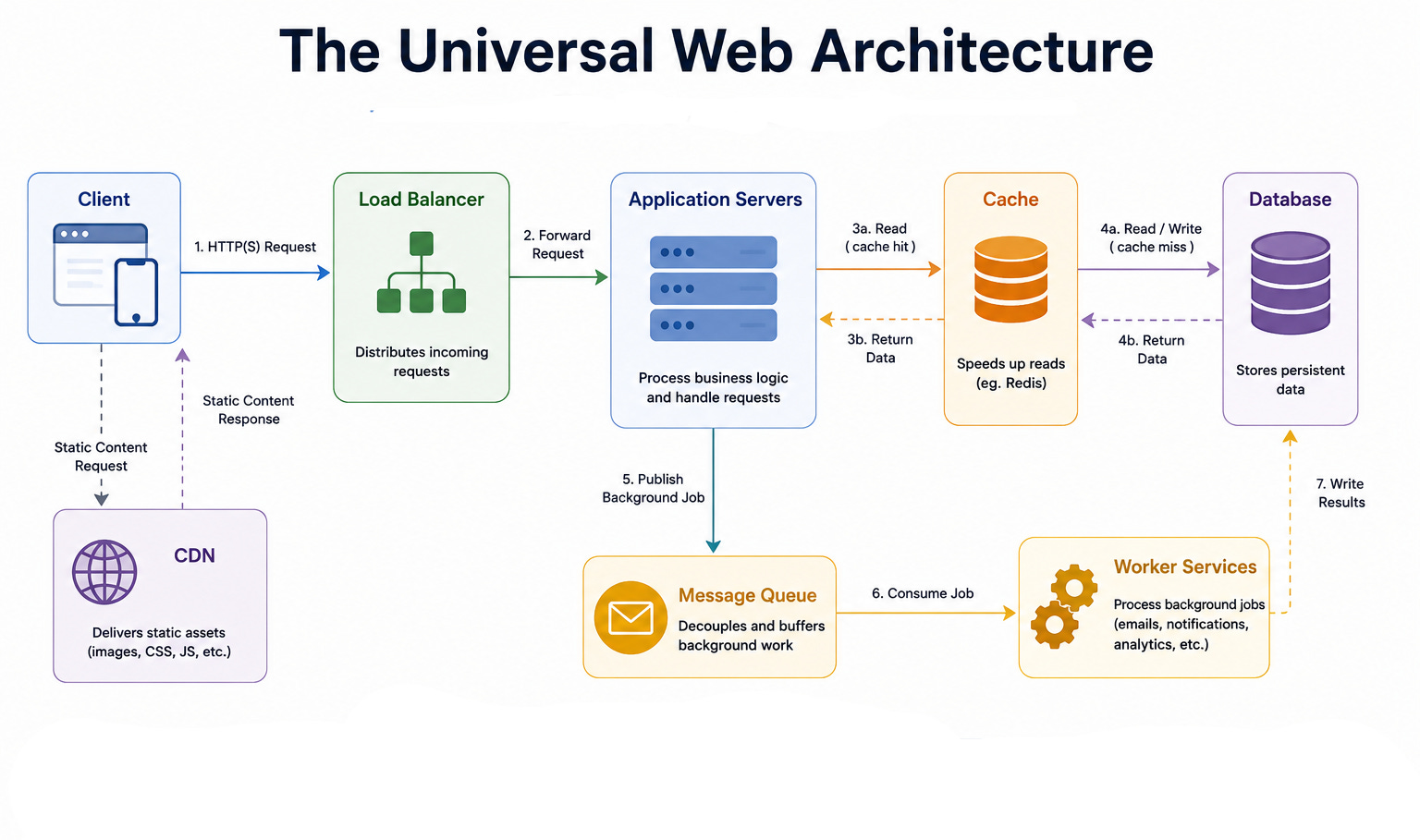
Caching stores frequently used data in fast memory to avoid repeating slow work.
A cache like Redis can serve data in well under a millisecond, compared to several milliseconds for a database query.
The common strategies are cache-aside, where the application loads data into the cache on a miss, write-through, where writes update the cache and database together, and write-behind, where writes hit the cache first and the database later.
When the cache fills up, an eviction policy such as least recently used decides what to remove.
A content delivery network, or CDN, stores copies of static files in locations around the world so users receive them from a nearby server. This is why a global website can load quickly everywhere.
A message queue lets services communicate asynchronously by placing work in a queue for later processing, which decouples services and absorbs traffic spikes.