
The Complete Guide to Load Balancing in System Design Interviews [2026 Edition]
A practical playbook on Load Balancers for candidates: what to ask, what to design, what to measure, and how to describe load balancing like a strong engineer.


Large systems rarely fail because a single server cannot handle a single request.
They fail because thousands of small routing decisions happen every second, and the system cannot keep those decisions consistent under changing load, partial failures, and uneven capacity.
A load balancer exists to make those routing decisions predictable. It sits between clients and a pool of servers, then decides which server gets each connection or each request.
When it is designed well, it improves availability (staying up), latency (responding quickly), and throughput (handling more work per second).
When it is designed poorly, it can become a new bottleneck, a new point of failure, and a source of subtle bugs like broken sessions, retry storms, and uneven hot spots.
What a Load Balancer Really Does
A beginner-friendly way to understand load balancing is to separate what it does from what it does not do.
A load balancer does three core jobs.
First, it provides a stable front door. Many backends can come and go, but the entry point stays consistent.
In cloud load balancers, that front door can be a DNS name, an IP address, or both.
Second, it distributes traffic across multiple backends. Traffic distribution is not just to “share load.” It is also to reduce the impact of a single backend failure and to let capacity grow by adding more backends.
Third, it enforces policy.
Policy means rules like “only forward to healthy targets,” “prefer local targets,” “drain connections before removing a server,” “terminate TLS,” or “route path A to service A.”
Those policies are where most system design trade-offs appear.
Now the “does not do” list.
A load balancer does not magically fix slow code.
If every backend request takes too long, a load balancer can only spread that slowness around.
A load balancer does not guarantee fairness unless it is configured for a fairness goal. Even “round robin” can become unfair in real systems because of persistent connections, different request costs, and uneven backend performance.
A load balancer does not remove the need for capacity planning. It can buy time and smooth spikes, but it cannot make infinite capacity appear.
The Smallest Useful Mental Model
To keep the concept concrete without relying on real-world stories, use a small, mechanical model.
Assume three backend servers: S1, S2, S3.
Assume a stream of requests arrives: R1, R2, R3, R4, …
The load balancer holds a list of backends and some state, like:
which backends are healthy
how many connections each backend has
what weights each backend has
whether any backend is “degraded”
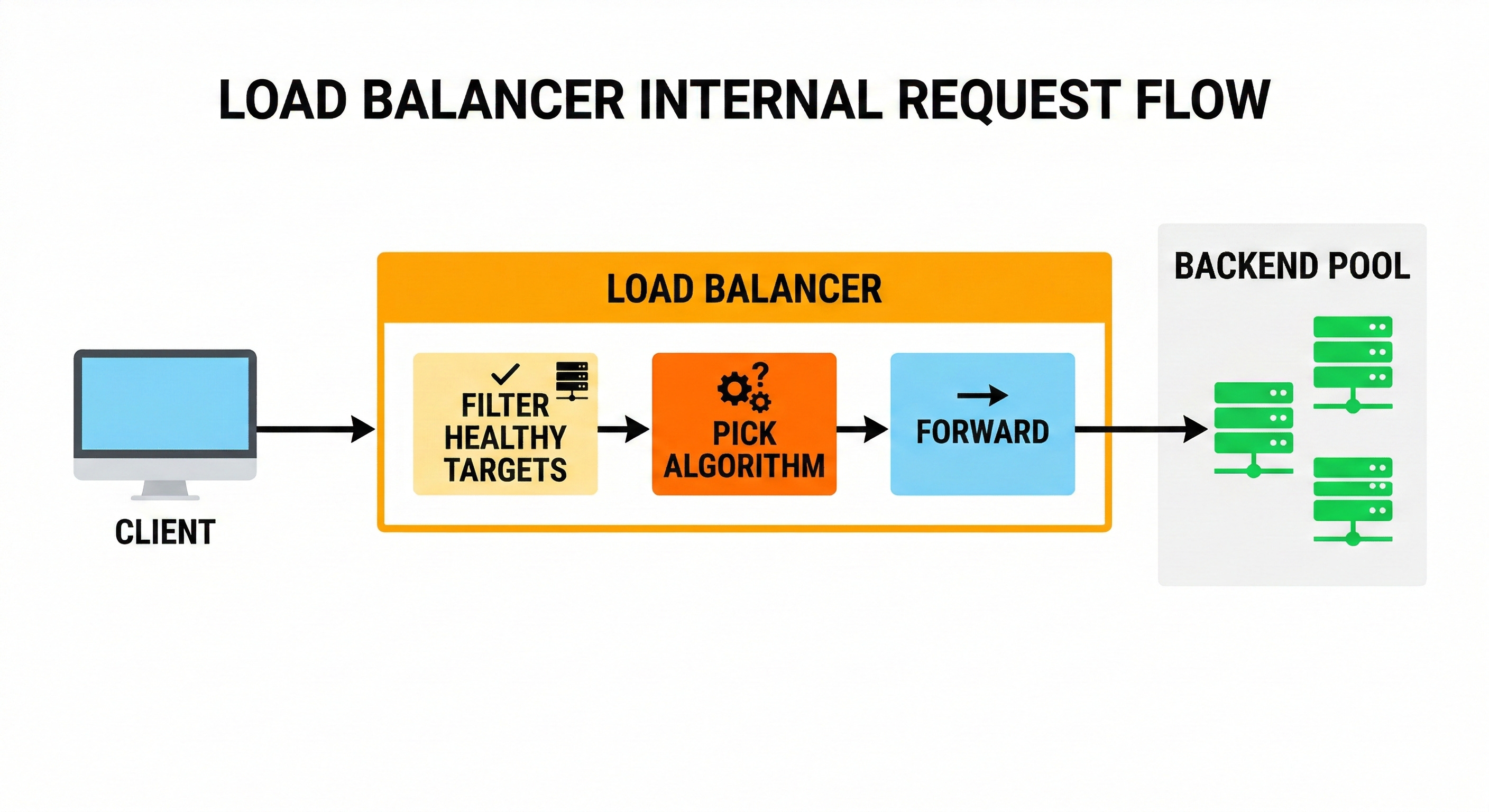
For each incoming unit of work, the balancer runs a selection step:
filter out unhealthy backends
apply a routing rule (if any)
pick a backend using an algorithm
forward the connection or request
record metrics and update internal state
That is the whole story at a high level.
The complexity appears because real systems add goals that conflict:
distribute evenly
keep latency low
keep sessions consistent
avoid cross-zone traffic
respond safely to failure
minimize cost
keep configuration simple
System design interviews often test whether these conflicts are recognized early, then handled explicitly.
Understanding the Vocabulary
Backend (target, instance, endpoint): a server that receives a forwarded request.
Pool: the set of backends available for selection.
Health check: a periodic test to decide whether a backend should receive traffic.
Failover: moving traffic away from failed or unhealthy backends.
Sticky sessions (session affinity): routing the same client to the same backend for some time.
Connection draining (deregistration delay): stop sending new traffic to a backend, but allow in-flight traffic to finish before removing it.
Transport protocol: the lower-level protocol that carries data, such as TCP or UDP.
Application protocol: a higher-level protocol like HTTP.
Understanding these terms makes later details easier to follow.
Where Load Balancing Happens
A common beginner mistake is to assume there is “the load balancer,” singular.
In modern systems, load balancing can happen at multiple layers, and sometimes at multiple points in the same request path.
Client-side Load Balancing
Client-side load balancing means the client chooses a backend.
To do that, the client needs a way to discover backends. Discovery can come from DNS, a service registry, or a control plane like xDS in proxy-based ecosystems.
This approach can be fast, because it can remove a hop. It can also scale well because each client shares the balancing work.
But it requires more sophistication in clients.