
The Architecture Behind Ultra Fast Systems: How Apps Stay Lightning-Quick at Scale
Learn the core architecture patterns that make large-scale systems incredibly fast. Covers caching, concurrency, load balancing, async processing, and more — perfect for interview prep and beginners.


Ever wondered how some apps and websites respond almost instantly, even under heavy load?
Ultra-fast systems make it possible.
They are engineered to deliver results at lightning speed for millions of users.
Building such speed is not magic; it’s smart architecture.
The right design decisions under the hood ensure low delays and high capacity.
For interview prep or junior developers, understanding these design principles is key. It can help you ace system design questions and build efficient systems in real life.
What Are Ultra-Fast Systems?
Ultra-fast systems are applications or services with near-instant response times, even when handling a huge number of requests.
In simple terms, they have very low latency (each request gets answered quickly) and very high throughput (they handle many requests per second).
Think of a search engine that shows results in milliseconds, while handling millions of searches.
Or a social network feed that loads immediately and stays smooth, even with countless users online.
These are examples of ultra-fast systems in action.
The goal is to make the user experience feel instantaneous.
To achieve this, every part of the system, from code to infrastructure, must be optimized for speed.
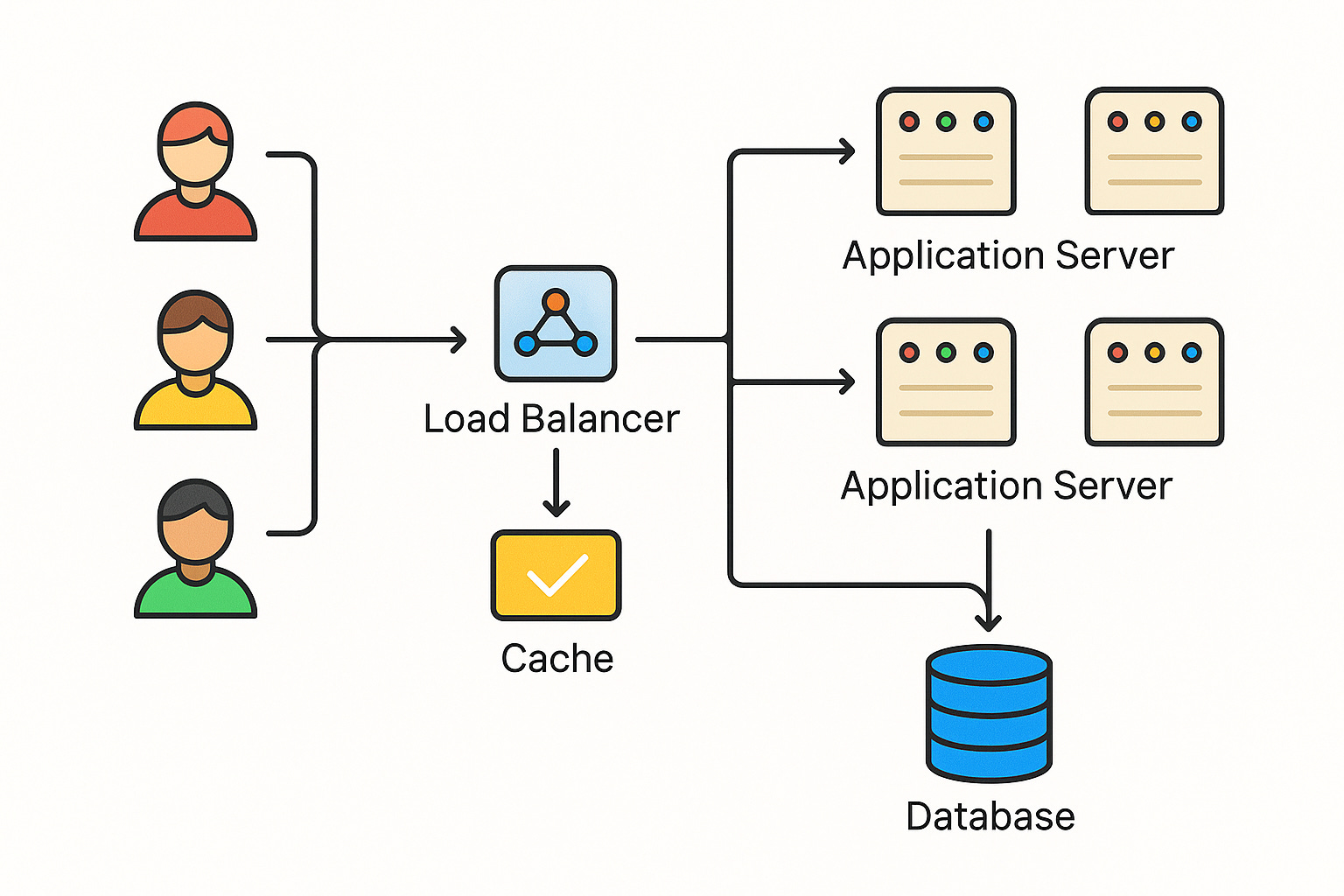
Now, let’s explore the key architecture choices that make such extreme performance possible.
Caching: Quick Access to Data
One of the biggest boosts to speed comes from caching.
A cache is a high-speed storage layer (often in-memory) that holds frequently used data.
By reading from a cache, the system avoids slower operations like database queries or complex computations.
Imagine you run a popular social app.
User Alice’s profile data is requested thousands of times a day.
Instead of querying the database each time (which is slow), the app can store Alice’s profile info in a cache.
Now, when someone needs that data, it’s returned almost instantly from memory.
Caching can happen at multiple levels.
Web browsers cache static files so they don’t re-download them.
Servers cache results of expensive calculations.
Databases have caching mechanisms for recent queries.
There are also dedicated cache systems (like in-memory data stores) that apps use for fast retrieval.
The result is reduced load on databases and faster responses to users.
By using caches effectively, ultra-fast systems handle more users with less waiting.
Parallelism and Concurrency: Doing More at Once
Another secret behind ultra-fast systems is doing many things at the same time.
In technical terms, this means leveraging concurrency and parallelism.
Instead of handling tasks one by one, a fast system handles multiple tasks simultaneously. For example, a server with multiple CPU cores can process several requests in parallel, one on each core.
Similarly, a single complex task can be split into subtasks that run at the same time on different threads or machines.
Think of it like a restaurant kitchen with many chefs. If one chef had to cook an entire meal for 100 people alone, it would take forever. But with 10 chefs working in parallel, those 100 meals get prepared much faster.
Each chef (or thread) works on a part of the workload concurrently.
Concurrency increases throughput significantly.
While one task waits (for example, reading from disk), another task can use the CPU.
Modern systems use multi-threading, multi-processing, and asynchronous I/O to keep all parts of the hardware busy.
This ensures the CPU isn’t sitting idle when it could be working on something else.
There is a catch: coordinating parallel tasks can be tricky.
If too many workers try to access the same resource, they might end up waiting (or “blocking”) each other.
Efficient ultra-fast systems are designed to minimize this contention. They use techniques like fine-grained locking (or avoiding locks), and they carefully plan which tasks truly benefit from parallel execution.
In short, by doing more work at once and smartly managing that work, systems can handle a lot more load in less time.
Horizontal Scaling and Load Balancing
Even with caching and concurrency, a single server has limits.
Ultra-fast systems typically scale out by using many servers in parallel. This is known as horizontal scaling.
Imagine an online service getting millions of hits per minute. One machine, no matter how powerful, might not handle it all.
The solution is to add more machines and balance the incoming requests among them.
A load balancer acts like a traffic cop in front of a cluster of servers. When users send requests, the load balancer distributes these requests across multiple servers, so no single server is overwhelmed.
If one server is busy, new requests go to another. This way, the system can handle a huge number of users by simply adding more servers and balancing the load.
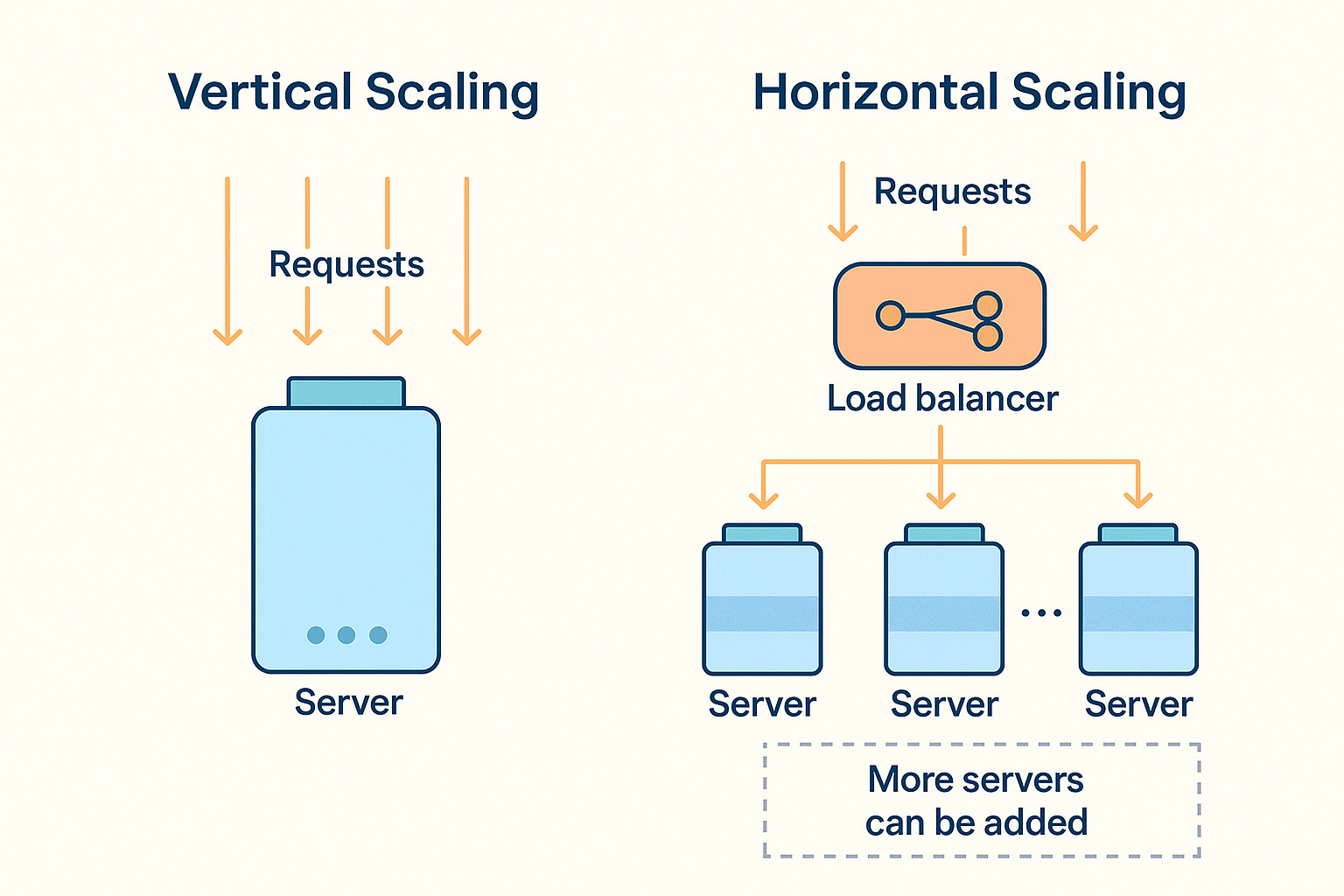
Horizontal scaling has big advantages for ultra-fast systems. It’s like having ten smaller cooks instead of one giant cook; together they serve more people.
In contrast, vertical scaling (buying a single super-powerful machine) hits a point of diminishing returns and can be very expensive.
Horizontal scaling is more flexible: you can increase capacity by just adding more commodity servers.
Many modern architectures also break the system into microservices, with separate components each handling a specific feature or function.
For example, one service might handle user profiles, another handles search, another handles notifications.
Each microservice can be scaled horizontally on its own.
If the search component needs extra power, you can run more instances of just that service.
This targeted scaling keeps the overall system fast under heavy load without over-provisioning everything.
The key takeaway: Ultra-fast systems avoid putting all the work on one server.
They spread the work out, and they use smart load balancing so that work is evenly shared.
This architectural choice means the system capacity (throughput) can grow almost linearly with each new server added.
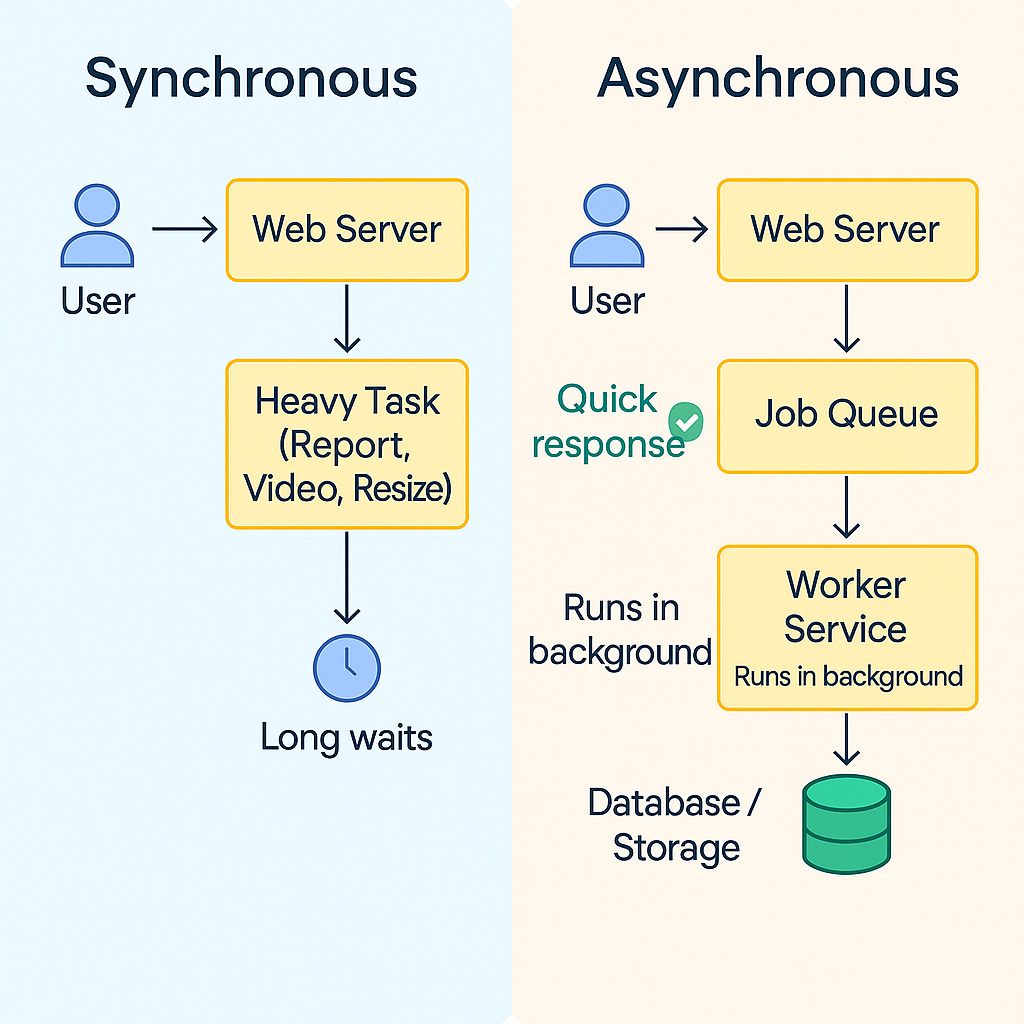
Asynchronous Processing: Don’t Keep Users Waiting
Ultra-fast systems often use asynchronous processing to remain snappy.
The idea is simple: don’t make the user wait for things that can be done in the background.
Consider a web application where a user uploads a high-resolution photo.
If the server were to process that photo (resize, store, etc.) immediately while the user waits, it could take several seconds. This would make the app feel slow.
With an asynchronous design, the app will quickly acknowledge the upload and maybe show “Processing in progress...” to the user.
The heavy work of resizing and storing the photo is put into a queue and handled by background worker processes.
The user can continue using the app without delay, and the processed photo will appear when ready.
This approach is common for sending emails, generating reports, encoding videos, and other time-consuming tasks. By offloading these tasks to background workers, the main system (the part the user interacts with) stays fast and responsive.
Message queues or event streams are often used to implement this. When a task needs to be done asynchronously, a message describing the task is sent to a queue.
Worker services listen to the queue, pick up tasks, and complete them behind the scenes.
The overall system throughput increases because the web or front-end servers are free to handle new requests instead of being tied up with slow jobs.
Asynchronous processing also improves reliability.
If a background task fails, it can be retried without affecting a user’s immediate experience.
In ultra-fast architectures, this decoupling of front-end response and back-end work is crucial. It means the user almost always gets a quick response, even if a lot of work still needs to be done afterwards.
In summary, don’t do all work up front if it’s not needed right away.
Respond quickly, then let other components finish the heavy lifting in parallel. This pattern keeps systems feeling fast from the user’s perspective.
Conclusion
Designing the architecture of ultra-fast systems is all about removing bottlenecks and doing work efficiently.
We achieve low latency by caching data and doing the minimal necessary work for each request.
We achieve high throughput by processing many things at once (concurrency) and adding more machines to share the load (horizontal scaling).
We keep users happy by handling non-critical work asynchronously, so they aren’t left waiting.
These techniques work together like pieces of a puzzle.
A well-designed system might use all of them: cached data for speed, multiple threads and servers for parallel work, and background jobs for heavy tasks. The result is a system that feels almost magically fast to users.
For those preparing for interviews or starting out in software engineering, remember that speed is a feature.
Understanding the architectural patterns behind ultra-fast systems will help you design better systems and answer performance-related questions with confidence.
With the right architecture in place, you can build applications that scale to millions of users and still respond in the blink of an eye.