
System Design Failure Modes: 20 Problems Strong Candidates Plan For
The Twenty Ways Real Systems Break, Explained With Their Causes and Fixes, So You Can Design for Failure and Discuss It in Interviews


What This Blog Will Cover
Why failure modes matter in interviews
How failures spread through systems
Load, retry, and data failures
Resource and coordination failures
How to raise them in interviews
Most candidates prepare for system design interviews by learning how to build systems.
They study how to scale, how to store data, and how to connect services. Far fewer prepare for the more revealing question, which is how systems break.
This is a costly gap, because designing for failure is one of the clearest signals interviewers look for. Real systems fail constantly. Machines crash, networks drop, dependencies slow down, and traffic spikes without warning.
A design that only works when everything is healthy is an incomplete design, and interviewers know it.
Strong candidates raise failure modes on their own.
Without being prompted, they point out where a design is fragile and explain how they would handle it. This proactive attention to failure is one of the behaviors that consistently separates a strong performance from an average one, because it shows the candidate thinks about systems the way they actually behave rather than how they behave in an ideal demo.
The good news is that the ways systems fail are well understood and finite.
There is a recognized catalog of failure modes that appear again and again, each with a known cause and a known set of mitigations. Learning them gives you both better designs and a powerful set of points to raise in an interview.
This article covers twenty failure modes every system design candidate should know, organized by how they occur. For each one, it explains what the failure is, why it happens, a concrete example, and how to mitigate it.
The goal is to make you fluent in the ways systems break, so you can design against them and discuss them with confidence.
Why Knowing Failure Modes Makes You a Better Candidate
Before the catalog, it helps to understand why this knowledge is so valuable in an interview specifically.
Each failure mode is paired with a mitigation. When you know the failure, you also know the fix, which means every failure mode is a point you can raise and immediately resolve. Saying “this component is a single point of failure, so I would add redundancy and failover” demonstrates exactly the kind of thinking interviewers reward.
Raising failure modes also lets you drive the conversation rather than waiting to be asked. Interviewers often probe reliability by asking what happens when something breaks, and a candidate who has already addressed it is several steps ahead.
With that in mind, here are the twenty failure modes, grouped into five categories by how they occur.
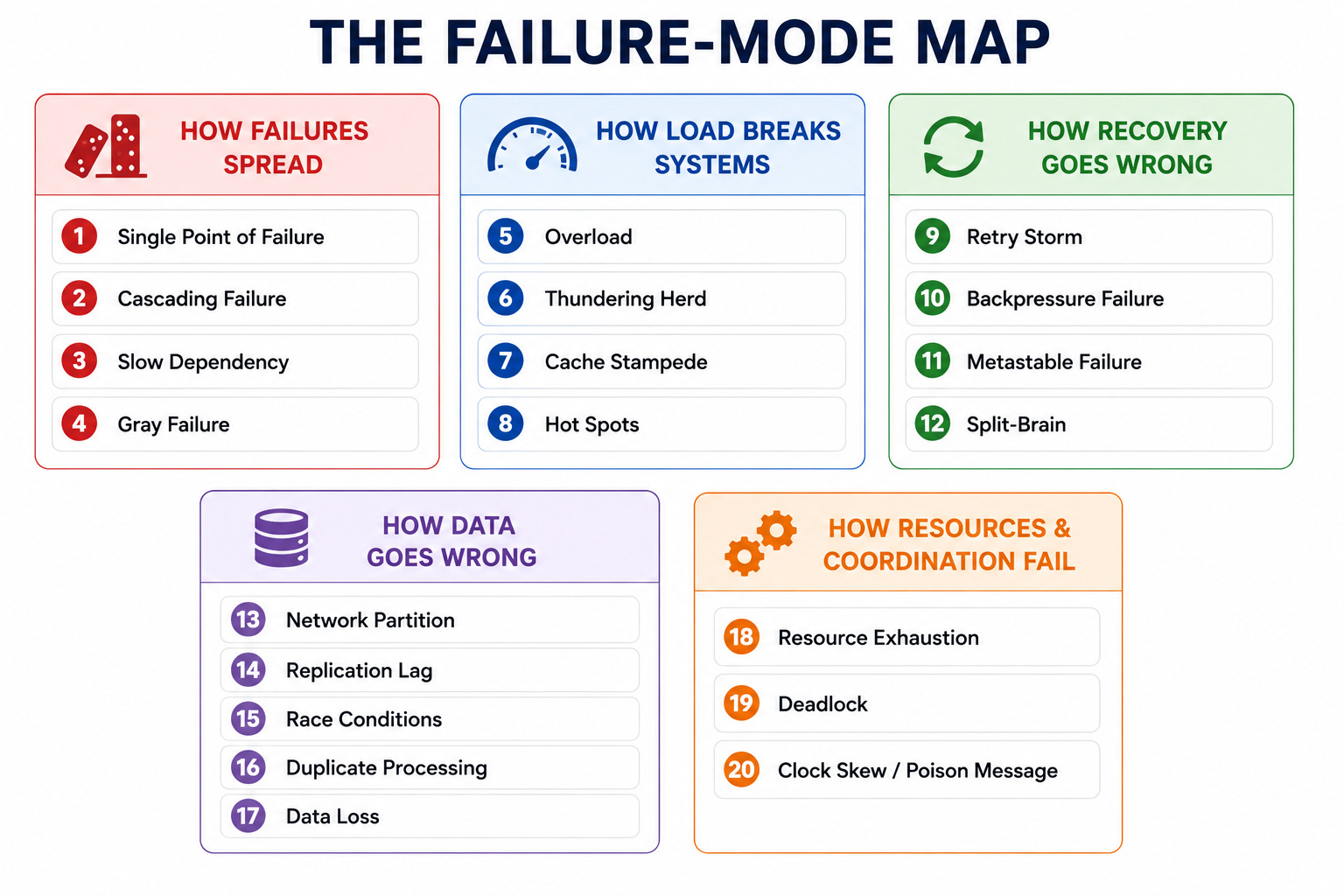
How Failures Spread
The first category covers failures that originate in one place and spread through the system. These are among the most dangerous, because a small initial problem can grow into a total outage.
1. Single Point of Failure
A single point of failure is any component whose failure takes down the entire system because it has no backup. If a system has one database, one load balancer, or one critical service with no redundancy, the failure of that one piece stops everything.
This happens whenever a critical component is deployed as a single instance. It is one of the most basic and most common design flaws.
The mitigation is redundancy. Every critical component should have multiple instances, with replication and automatic failover so that the loss of one does not stop the system. Identifying and removing single points of failure is one of the first things to do in any design.
2. Cascading Failure
A cascading failure is when the failure of one component overloads others, causing them to fail in turn, until the problem spreads across the system.
A small initial failure triggers a chain reaction.
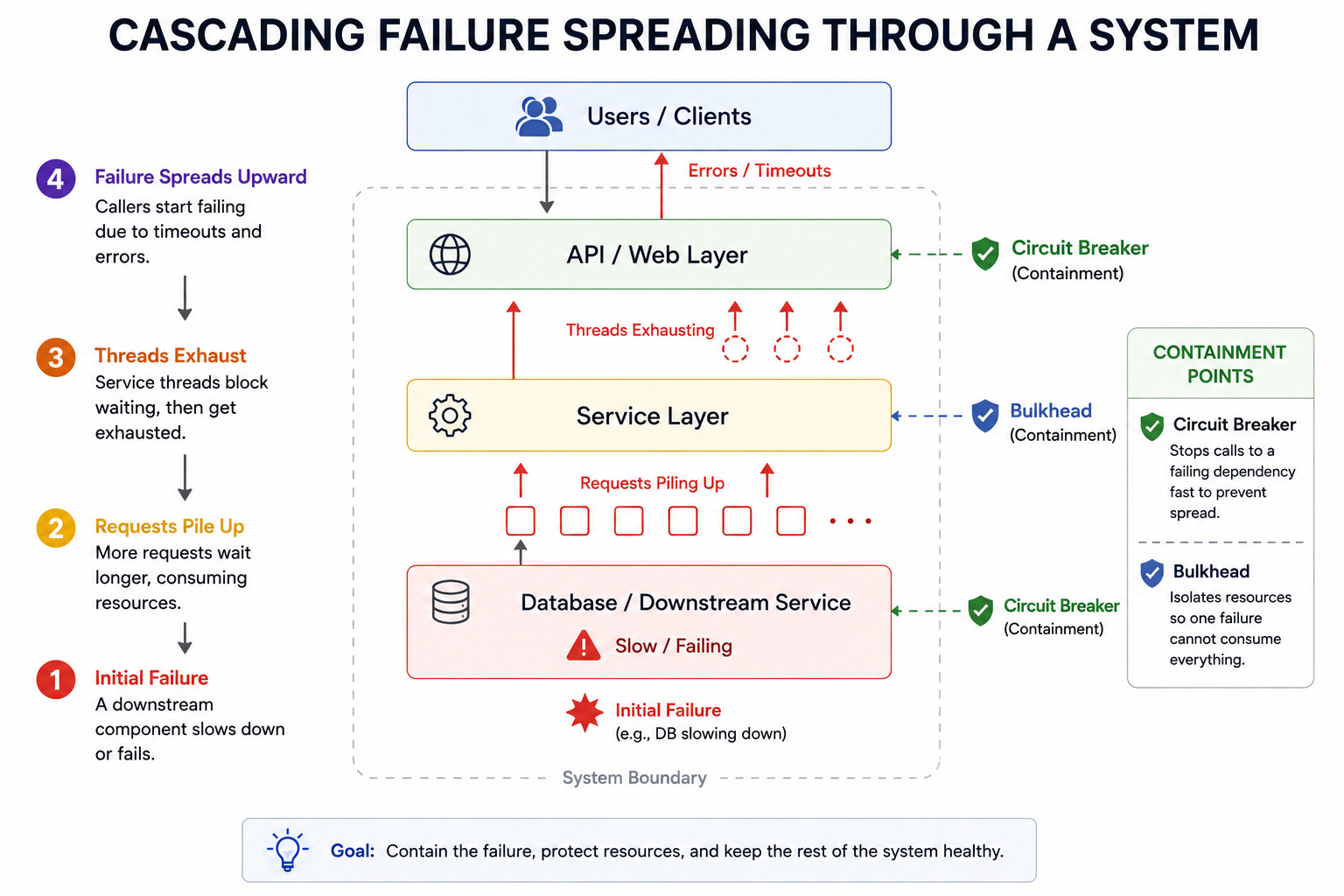
For example, if a database slows down, requests to it pile up, the service waiting on it exhausts its threads, and callers of that service then fail too, spreading the damage upward.
The mitigations are isolation patterns.
Circuit breakers stop calls to a failing component before it drags others down, bulkheads isolate resources so one failure cannot consume everything, and load shedding drops excess work to protect the core. The goal is to contain a failure rather than let it spread.
3. Slow Dependency
A slow dependency is often worse than a failed one.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.