
System Design Interview: The Architecture of Kubernetes (Control Plane vs. Worker Nodes)
Discover how Kubernetes works behind the scenes. We explain the Control Plane, Worker Nodes, and self-healing mechanisms for junior developers.


Building software systems requires moving code from a local development environment to a production server.
In the past, engineering teams deployed monolithic applications directly onto bare metal hardware.
This approach created massive dependency conflicts and severe deployment bottlenecks. When network traffic spiked rapidly, the single physical server would run out of memory and crash completely.
To solve these software conflicts and scaling limitations, developers adopted containers.
A container packages the application code, runtime environment, and system libraries into one isolated environment.
While containers solve the immediate packaging problem, they introduce a massive operational challenge. Managing ten isolated containers on a single machine is incredibly simple. Managing ten thousand containers across hundreds of different physical servers is technically impossible for human operators. Servers crash unexpectedly.
Network connections drop without any warning. Software deployments must happen continuously without bringing the entire application offline.
The software industry needed an automated way to manage, scale, and repair these massive deployments.
The Core Problem in Distributed Systems
Containers are fantastic for isolating software dependencies.
However, a basic container runtime only knows how to start and stop a single process on a single machine. It does not understand the broader architecture of a large distributed system.
If a physical server suddenly loses power, all the isolated environments on that machine terminate immediately.
The basic container engine cannot detect this hardware failure on a broader network level. It also cannot automatically recreate those lost software environments on a completely different, healthy server.
Furthermore, network traffic is highly unpredictable.
If a web application suddenly receives a massive influx of user requests, a single container will consume all available memory and fail. The system needs a way to duplicate that container automatically to distribute the heavy network load.
Administrators cannot manually monitor memory usage and manually start new processes on new servers continuously.
This manual intervention is completely unscalable. The modern software ecosystem required an overarching management layer to handle these distributed computing problems.
This management layer must be capable of observing the entire network, making intelligent placement decisions, and executing recovery procedures instantly.
Enter Container Orchestration
Kubernetes is an open-source container orchestration platform. It automates the deployment, scaling, and operational management of containerized applications. It acts as the central management system for a vast network of physical or virtual computing resources.
Instead of interacting with individual servers, engineers interact directly with the Kubernetes system. They define the desired state of their software architecture using simple configuration files.
Kubernetes reads these configuration files and takes the necessary actions to make the actual system match that desired state.
To explain this using a simple technical example, imagine a configuration file states that exactly five frontend web containers must run at all times. The system ensures exactly five are running across the network.
If one server crashes and destroys two containers, the system detects the mathematical discrepancy.
It then automatically spins up two replacement containers on healthy servers to maintain the desired state of five. This declarative approach shifts the heavy burden of maintaining system stability from human operators to the automated software layer.
Understanding Cluster Architecture
To understand how this massive automation works, we must explore the underlying architecture.
A Kubernetes environment is officially called a Cluster.
A cluster is simply a group of individual servers connected over a strong network, acting together as a single computing entity.
The architecture divides these specific servers into two distinct categories.
The first category is the control plane, which makes all the high-level administrative decisions. The second category consists of the worker nodes, which execute the actual application code.
The Control Plane Components
The Control Plane is the core management hub of the cluster. It constantly monitors the entire state of the system and issues commands to manage workloads. It consists of several highly specialized software components working tightly together.
The API Server is the primary gateway for the entire system. Every single communication goes directly through this component. When an engineer submits a configuration file, they send it to the API Server.
The API Server validates the request, checks the authentication credentials, and ensures the request conforms to strict system rules.
Internal components also rely exclusively on the API Server to communicate with each other. It is the only component that directly updates the central cluster database.
This strict communication design prevents conflicting data and maintains high network security.
The etcd component is a highly reliable database. It is a distributed key-value store that securely saves the complete configuration and current state of the entire cluster. It is the absolute source of truth for the system.
Every time a new application is deployed or a server goes offline, that specific information is recorded in etcd.
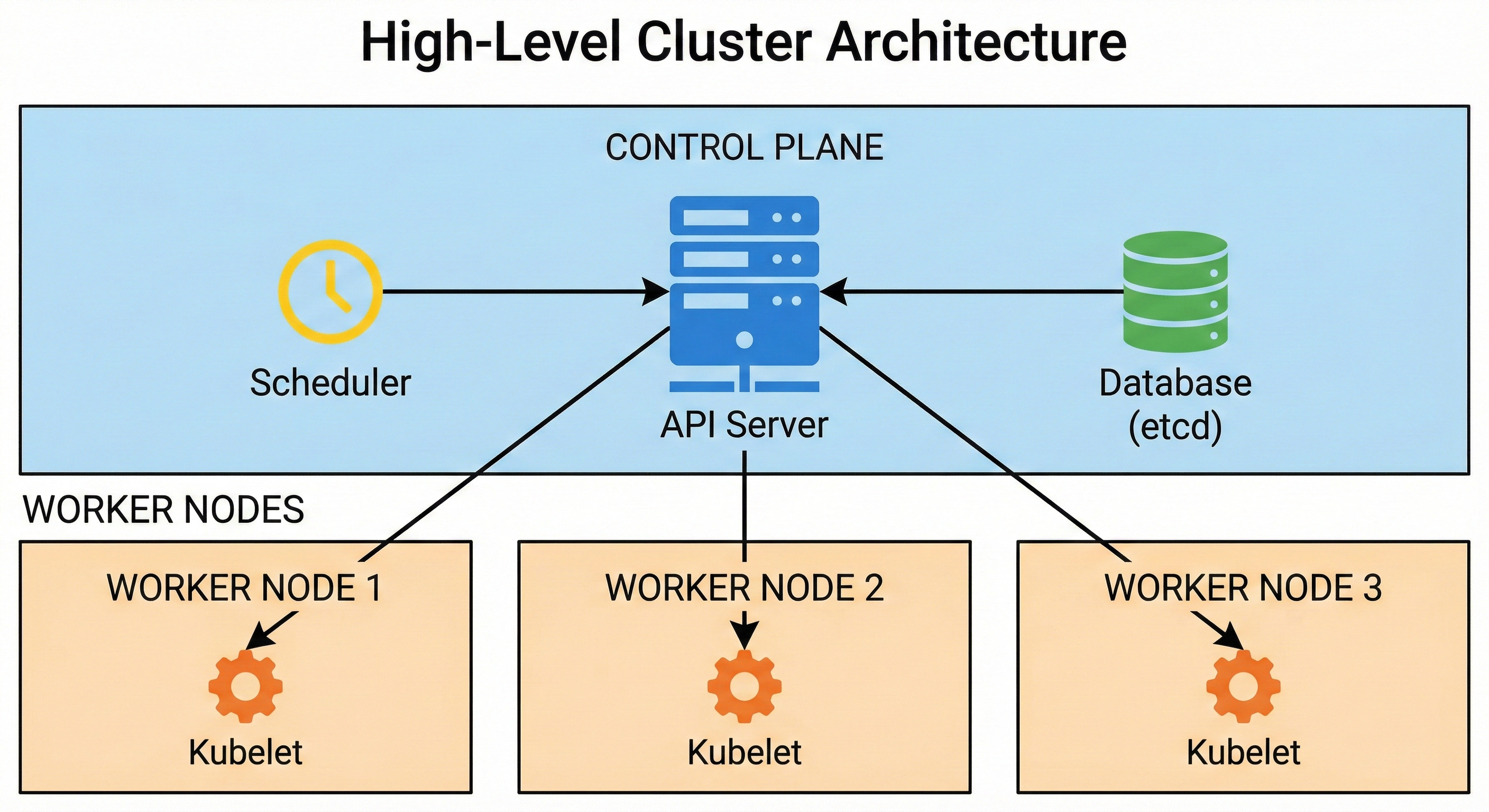
The Scheduler is responsible for assigning work to available servers.
When the API Server receives a request to deploy a new application, the Scheduler analyzes the hardware requirements. It scans the available worker nodes to find the ones with the most optimal processing power and memory. It ranks these available machines based on capacity and then assigns the workload to the best possible candidate.
The Controller Manager runs continuous background loops. These background processes constantly compare the actual state of the cluster against the desired state stored in etcd.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.