
System Design Interview Question: How to Design a Distributed Cache (like Redis) in 45 Minutes
Crack the Redis design question. Master the 14-step strategy for architecting a scalable key-value store, from non-functional requirements to final diagrams.


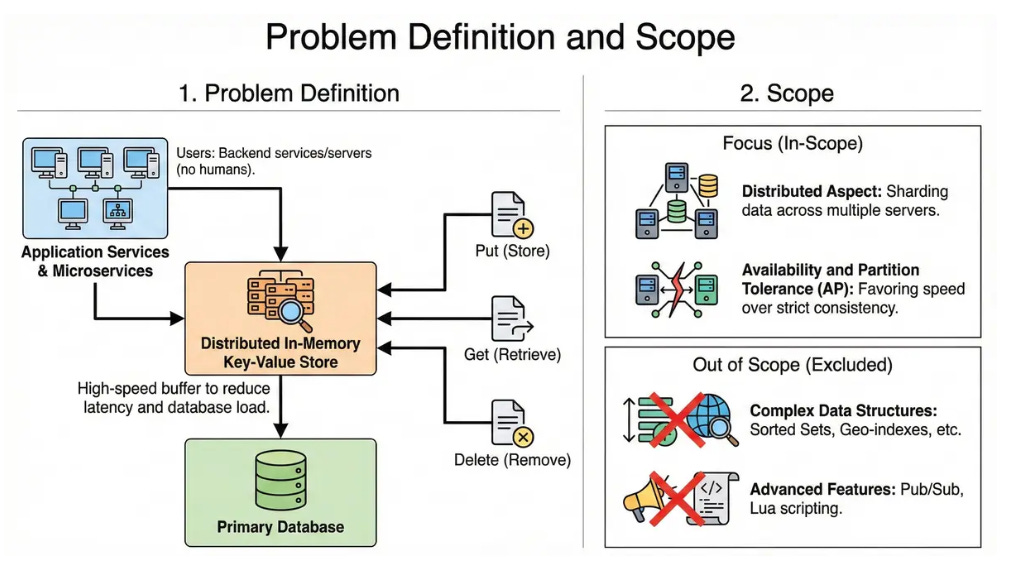
1. Problem Definition and Scope
We are designing a distributed, in-memory key-value store. The system acts as a high-speed buffer between application services and the primary database to reduce latency and database load.
User Groups: Backend microservices and application servers (not human end-users).
Main Actions: Storing data (Put), retrieving data (Get), and removing data (Delete).
Scope:
We will focus on the distributed aspect: sharding data across multiple servers.
We will focus on Availability and Partition Tolerance (AP), favoring speed over strict consistency.
Out of Scope: We will not cover complex data structures (like Sorted Sets, Geo-indexes) or advanced features like Pub/Sub and Lua scripting, focusing strictly on the core Key-Value functionality.
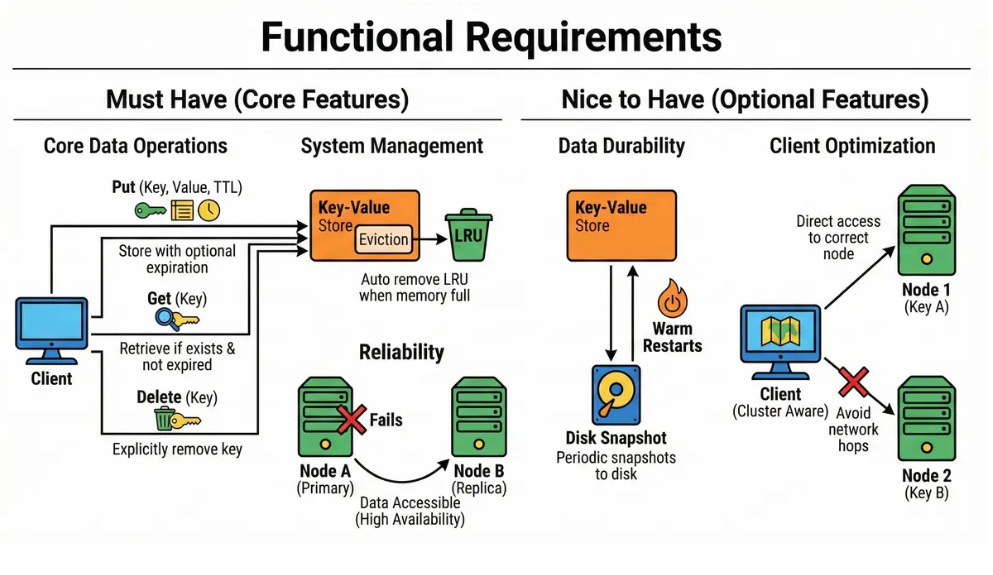
2. Clarify functional requirements
Must Have:
Put (Key, Value, TTL): Clients can store a binary value with a string key and an optional expiration time (Time-To-Live).
Get (Key): Clients can retrieve the value if it exists and hasn’t expired.
Delete (Key): Clients can explicitly remove a key.
Eviction: The system must automatically remove the Least Recently Used (LRU) items when memory is full.
High Availability: If a node fails, data should remain accessible via replicas.
Nice to Have:
Persistence: Periodic snapshots to disk to allow “warm” restarts.
Cluster Awareness: Clients should know which node holds which key to avoid network hops.
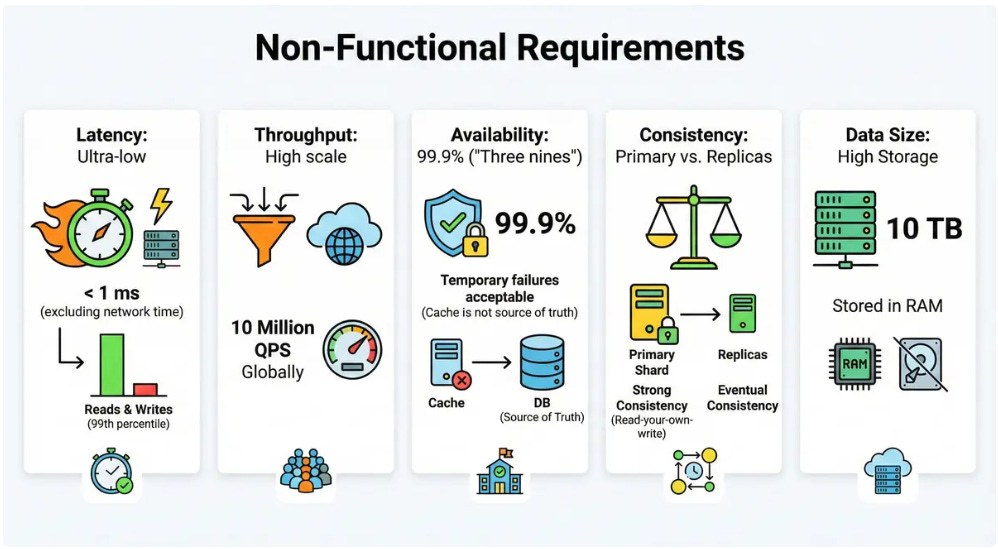
3. Clarify non-functional requirements
Latency: Ultra-low. Reads and writes should be < 1 ms (excluding network time) at the 99th percentile.
Throughput: High scale. We target 10 million QPS (Queries Per Second) globally.
Availability: 99.9% (”Three nines”). Since this is a cache, temporary failures are acceptable (the DB is the source of truth), but the system should be robust.
Consistency: Eventual consistency is acceptable for replicas, but the primary shard should provide strong consistency (read-your-own-write).
Data Size: We need to store roughly 10 TB of data in RAM.
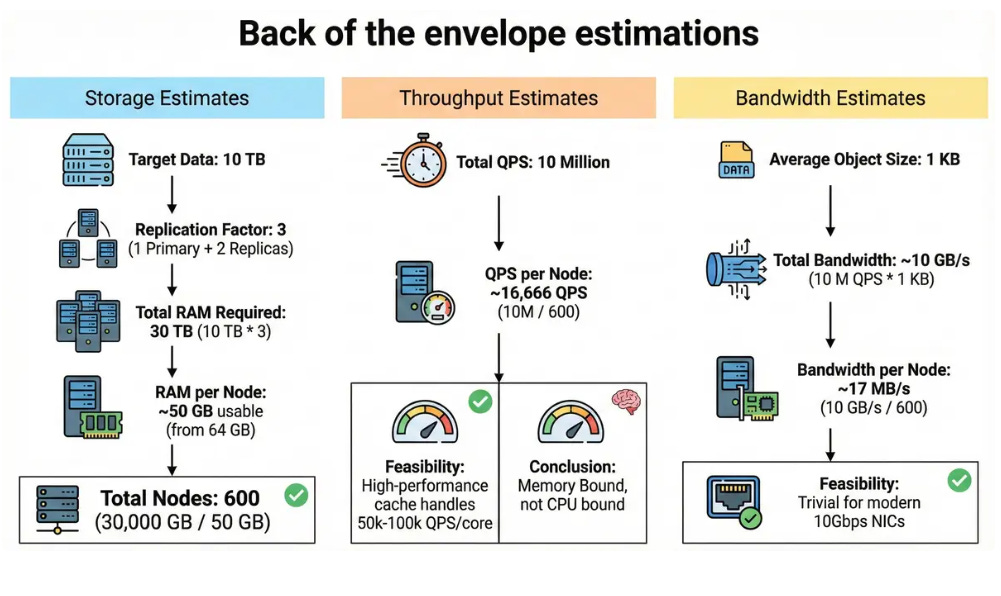
4. Back of the envelope estimates
Let’s size the system for the 10 TB and 10M QPS targets.
Storage Estimates:
Target Data: 10 TB.
Replication Factor: 3 (1 Primary + 2 Replicas for HA).
Total RAM Required: 10 TB * 3 = 30 TB.
RAM per Node: Assume 64 GB physical RAM, with ~50 GB usable for cache (leaving space for OS).
Total Nodes: 30,000 GB / 50 GB = 600 nodes.
Throughput Estimates:
Total QPS: 10 Million.
QPS per Node: 10,000,000 / 600 ≈ 16,666 QPS.
Feasibility: A high-performance cache (like Redis) can easily handle 50k-100k QPS per core.1 Our load per node is low, meaning we are Memory Bound, not CPU bound.
Bandwidth Estimates:
Average Object Size: 1 KB.
Total Bandwidth: 10 M QPS x 1 KB ≈ 10 GB/s.
Bandwidth per Node: 10 GB/s/600 ≈ 17 MB/s. This is trivial for modern 10Gbps NICs.
5. API design
While real caches use binary protocols (like TCP/RESP) for performance, we will define a simple REST-style API for clarity.
1. Set Value
Method: PUT /v1/keys/{key}
Body: { “value”: “base64_data”, “ttl_seconds”: 3600 }
Response: 201 Created or 413 Payload Too Large.
2. Get Value
Method: GET /v1/keys/{key}
Response:
200 OK: { “value”: “base64_data”, “ttl”: 3590 }
404 Not Found: Key missing or expired.
3. Delete Value
Method: DELETE /v1/keys/{key}
Response: 204 No Content.
6. High level architecture
To achieve sub-millisecond latency, we will use a Smart Client architecture. This avoids a centralized Load Balancer (which adds an extra network hop) and allows the application to route requests directly to the correct shard.
Components:
Smart Client (SDK): A library embedded in the application servers (Service A, Service B). It holds a “Cluster Map” and uses Consistent Hashing to pick the right server.