
Architecting Data Pipelines: When to Use Kafka, Spark, Flink, and Hadoop
Master the core concepts of Hadoop, Spark, Kafka, and Flink to build highly scalable data processing architectures.


Modern software applications continuously generate massive volumes of internal diagnostic data. Recording this continuous flow of information without crashing the primary database is a complex engineering challenge.
Standard relational databases simply freeze when forced to calculate massive mathematical totals continuously.
Software engineers must build specialized processing pipelines to handle this heavy calculation work.
This exact challenge frequently appears in system design interviews as the metrics aggregation question.
Understanding how to solve this problem separates junior developers from senior system architects.
Mastering these core architectural concepts is absolutely critical for building reliable software platforms. It is the ultimate key to passing the most difficult technical interviews.
The Core Concept of Metrics Aggregation
Every system generates small textual records of events called logs.
A metric is simply a mathematical summary of these raw logs over a specific time period.
The total number of server errors per hour is a standard system metric.
Aggregation is the actual technical process of grouping these individual logs and calculating that final total.
When a software application is very small, calculating metrics is very simple. The main database just reads every single stored row and adds up the specific numbers.
However, massive software applications generate tens of thousands of raw logs every second. Asking a standard database to constantly sum up millions of rows will completely overload its internal processor.
To prevent this database failure, engineers build completely separate computing systems just for metric aggregation. They extract the raw logs from the main application servers and send them to specialized processing engines. These external calculation engines compute the totals safely away from the primary system database.
There are two primary ways to design these specialized processing engines.
The first architectural approach is batch processing.
The second architectural approach is stream processing. Understanding the deep technical differences between these two processing approaches is the entire goal of the interview.
Understanding Batch Processing
Batch processing handles data in large scheduled chunks.
The system collects raw server logs over a long period like an entire day. It stores these text logs safely in a massive storage system without doing any immediate math.
Nothing happens until a specific scheduled processing time arrives.
When the exact scheduled time arrives, a calculation engine activates and reads all the collected data at once. It performs all the necessary mathematical computations on the entire massive chunk of data. It then writes the final summarized metric totals into a separate reporting database.
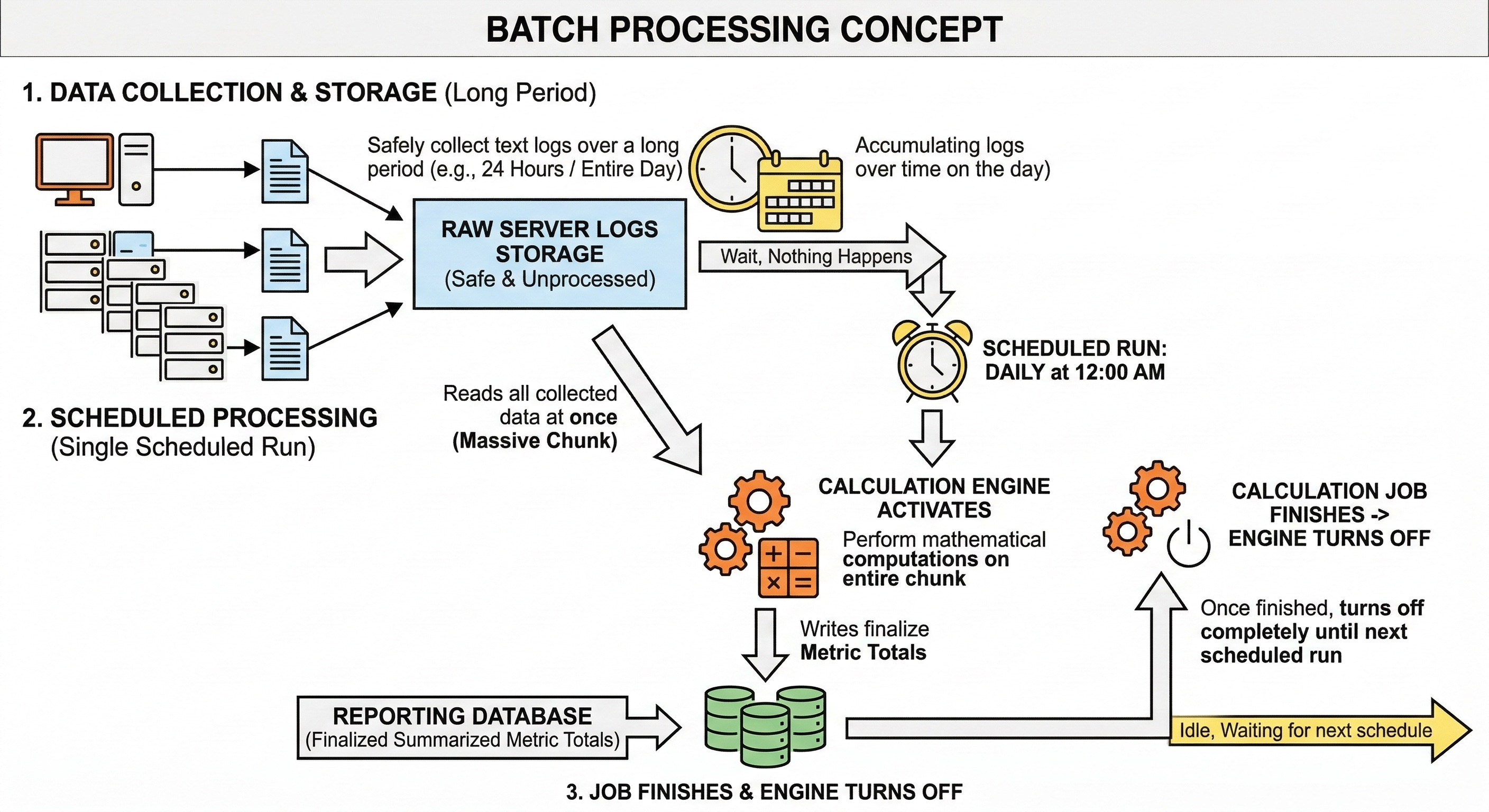
Once the heavy calculation job finishes, the engine turns off completely until the next scheduled run.
How Hadoop Stores The Data
To build a massive batch processing system, engineers often use a specialized tool called Apache Hadoop.
Hadoop is essentially a massive distributed hard drive designed specifically for big data. It takes giant files of raw system logs and splits them into much smaller blocks. It then copies these small blocks across hundreds of different physical computers.
Distributing the data this way ensures the overall system never runs out of physical storage space. It also provides deep safety for the original raw log records.
If one computer hardware drive completely breaks, the data is still safely stored on other healthy computers.
The raw data just sits quietly on these storage drives until a calculation job is officially requested.
How Spark Calculates The Metrics
When it is time to calculate the metrics, a powerful tool called Apache Spark is used. Spark is a highly optimized distributed calculation engine.
Spark reads the split data blocks from all the Hadoop computers at the exact same time. It pulls this raw data directly into its own temporary server memory to perform the required calculations.
