
System Design Interview Basics: How APIs and Rate Limiting Work Together
Master API design and protect your system. Learn the fundamentals of REST APIs, Idempotency, and Rate Limiting algorithms like Token Bucket and Fixed Window for your system design interview.


In software engineering, there are two fundamental realities that dictate how large-scale systems are designed.
First, software components are naturally isolated; they do not share memory or processing power by default.
Second, computing resources are finite; every server has a maximum capacity that cannot be exceeded without consequence.
These two constraints create a specific engineering challenge. You must construct a mechanism that enables these isolated components to communicate freely, yet you must also implement a control system to ensure that this communication does not overwhelm the infrastructure.
Consider a standard web application.
The database storing user records resides on a server with its own file system and operating system. This server is physically distinct from the mobile device or web browser attempting to access that data. Without a standardized communication channel, these systems remain disconnected.
However, once you establish that channel, you expose the system to the outside world.
A sudden viral spike in traffic, a malicious bot attempting to brute-force passwords, or a bug in a frontend script could send an avalanche of requests that consumes all available computing power, causing the entire system to crash.
To build a reliable distributed system, you must master two core concepts: the Application Programming Interface (API), which enables connectivity, and Rate Limiting, which ensures stability.
Part 1: The Interface
The mechanism that bridges the gap between isolated systems is the Application Programming Interface (API).
In the context of distributed systems, an API acts as a formal specification. It acts as a strict contract between the client (the system asking for data) and the server (the system holding the data).
The API as a Contract
The most effective way to understand an API is to view it as a published agreement.
This agreement states specific rules: if the client provides input X in format Y, the server guarantees it will process the request and return output Z.
This concept of the “contract” is the most important mental model for a system designer.
In a tightly coupled system without this abstraction, one piece of code might try to read directly from another system’s internal memory or database. This is fragile.
If the database schema changes, such as if a column is renamed or a data type is altered, the dependent code fails immediately.
An API solves this problem by decoupling the implementation from the interface.
The backend team is free to completely rewrite their internal algorithms, migrate to a new database engine, or switch programming languages.
As long as the API continues to accept the same request structure and return the same response format, the client application remains unaffected.
This separation of concerns is what allows modern software teams to work independently and scale applications rapidly.
The Anatomy of a Request
Communication across this boundary typically follows a synchronous Request-Response cycle. To design a robust system, one must understand the anatomy of this cycle at a granular level.
A valid API request is a precise instruction packet containing four distinct components.
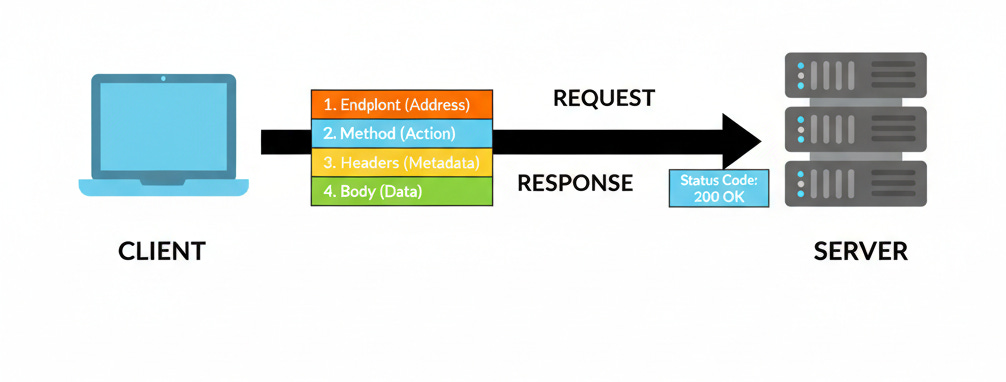
1. The Endpoint
The Uniform Resource Identifier (URI) is the network address of the specific resource being accessed.
In a well-designed system, the endpoint represents a noun rather than a verb. It functions as the location identifier for the data object involved.
For example, /users/123 identifies a specific user resource, while /products/456 identifies a product.
2. The HTTP Method
This component defines the intent of the request. It tells the server what type of operation to perform on the resource defined by the endpoint.
GET: Retrieves the current state of a resource. This operation is read-only and does not alter data on the server.
POST: Submits data to be processed, typically resulting in the creation of a new resource.
PUT: Replaces the target resource with the request payload.
DELETE: Removes the specified resource.
3. Headers
Headers provide metadata about the transaction itself. They handle the administrative side of the request.
Common headers include Authorization, which carries credentials to validate the client’s identity, and Content-Type, which specifies the format of the data being sent.
4. The Body
For operations that involve data transmission (such as POST or PUT), the body contains the actual data entity.
In modern distributed systems, this is almost exclusively formatted as JSON (JavaScript Object Notation).
JSON is a text-based format that structures data in key-value pairs. It is preferred because it is lightweight, easy for machines to parse, and easy for humans to read and debug.
Architectural Styles and Constraints
Not all APIs are structured the same way.
The choice of architecture dictates how data is fetched and how the system manages connectivity.
The most common architectural style for web services is REST (Representational State Transfer).
REST imposes a set of constraints on how an API should behave. The most critical constraint for system design is Statelessness.
In a stateless architecture, the server does not retain any session information about the client between requests.
Every single request must be self-contained, holding all the information necessary to understand and process it, including authentication tokens.
The server treats every request as if it is the first time it has seen that client.
This constraint is vital for Horizontal Scaling.
Because the server holds no unique state for a user, any server in a cluster can handle any request.
If one server fails, traffic can be instantly routed to another without the user losing their session or experiencing an error. This allows systems to grow from one server to one thousand servers with minimal complexity.
Reliability and Idempotency
In distributed systems, network failures are inevitable.
A client may send a request, but the network connection might drop before the response is received.
The client, unsure if the operation succeeded, will naturally retry the request.
This reality necessitates Idempotency.
An operation is idempotent if applying it multiple times produces the same result as applying it once.
GET and DELETE are inherently idempotent. Deleting a record five times is the same as deleting it once; the record is gone.
POST is typically not idempotent. If a client sends a payment request, times out, and sends it again, the server might inadvertently process two separate payments.
To address this, system designers implement idempotency keys.
The client generates a unique ID for the request. The server tracks these IDs in a temporary cache.
If it receives a request with an ID it has already processed, it simply returns the cached result of the initial operation rather than executing the business logic again. This ensures data integrity even in unreliable network conditions.
Part 2: The Guardrails
Once an API is established, the system is open to interaction. However, this openness introduces significant risk.
Resources are finite. Your Central Processing Unit (CPU) can only execute a specific number of instructions per second. Your Random Access Memory (RAM) has a fixed limit. Your database can only maintain a specific number of concurrent connections.
If you leave your system completely open without any guardrails, you are gambling with its stability. A “noisy neighbor,” which refers to a single user or script sending thousands of requests per second, can consume all available resources. This causes the system to slow to a crawl or crash entirely for everyone else.
To prevent this, we need a governance mechanism. We need a way to say, “I can handle this much traffic, but no more.” This mechanism is called Rate Limiting.
What Is Rate Limiting?
Rate Limiting is a strategy for governing network traffic. It places a cap on how frequently a client can repeat an action within a certain timeframe.
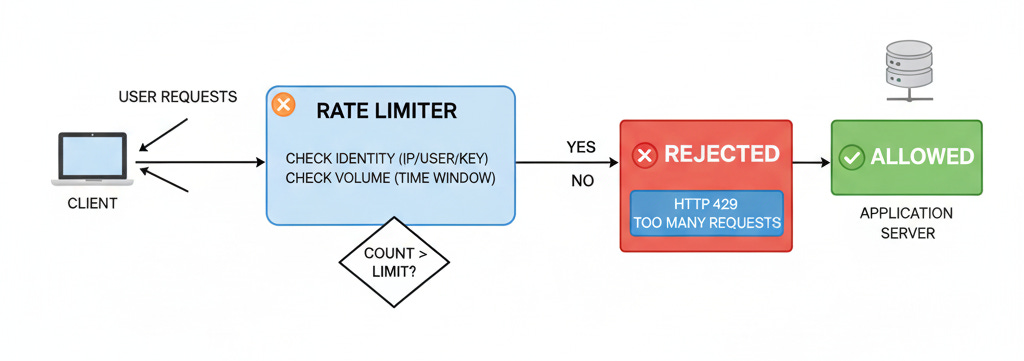
When a request arrives, the rate limiter evaluates it against a specific rule set. It checks the identity of the requester (usually via IP address, User ID, or API Key) and the volume of requests that identity has made recently.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.