
System Design Guide to Large Language Models
Master Large Language Model (LLM) architecture for your system design interview. Learn how tokenization, vector embeddings, and KV caching power modern AI inference.

Software engineering traditionally relies on exact instructions and rigid conditional logic. Computers execute strictly defined binary commands natively. This exactness creates a severe technical barrier when systems attempt to process natural human language.
Human communication is inherently fluid and constantly breaks predefined structural rules.
Early computational attempts utilized hardcoded grammar rules to parse text strings. Those legacy systems failed rapidly because writing discrete mathematical logic for every linguistic variation is impossible.
A completely different architectural paradigm was required to bridge the gap between strict binary code and unstructured text.
Large language models solve this exact engineering problem. They discard rigid grammatical rules entirely and treat language generation as a massive statistical pattern matching challenge. These systems process unstructured text data and map it into high-dimensional mathematical spaces.
Understanding this underlying computational architecture is essential for modern software developers and system design candidates.
This mathematical framework forms the foundational infrastructure for contemporary artificial intelligence applications.
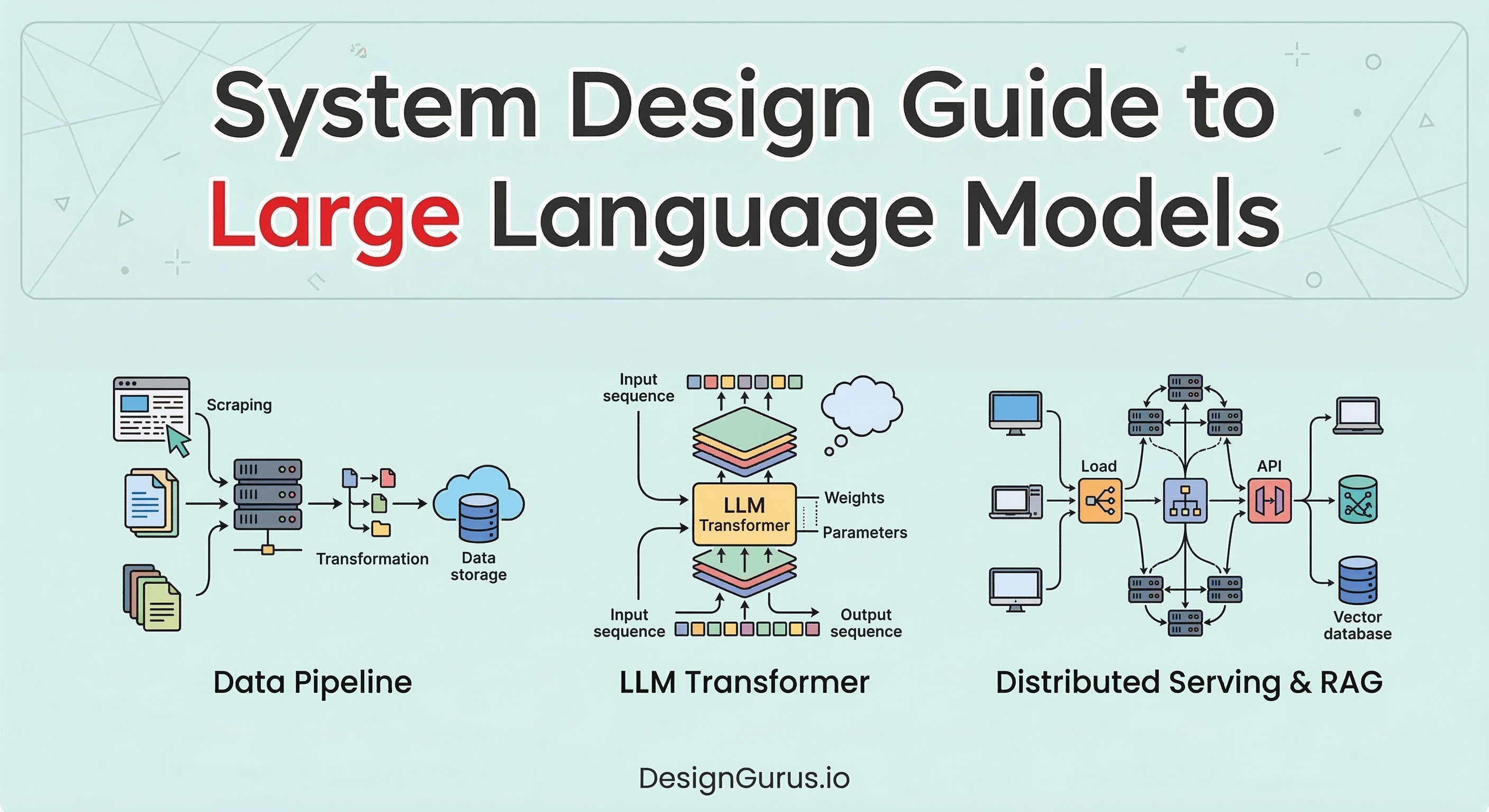
How Large Language Models Work
Language models operate on a fundamental principle of statistical probability. Their singular primary function is predicting the absolute most probable next item in a sequence. They do not comprehend meaning intrinsically. They simply calculate strict mathematical likelihoods across massive datasets.
To achieve this predictive capability, the architecture relies on deep neural networks.
A neural network is a complex mathematical framework consisting of interconnected computational layers. These layers contain millions of parameters that store specific numerical weights.
During the initial training phase, the system constantly adjusts these internal weights to minimize predictive errors.
The architecture requires massive volumes of raw text data to calibrate accurately. The system analyzes this unstructured data mathematically to learn structural patterns.
This intensive process transforms language from a linguistic concept into a purely computational sequence.
Translating Text Into Computable Data
We must remember that computers cannot process alphabetical letters natively. They strictly require numerical inputs to perform required mathematical operations.
The first major phase in this system architecture is converting raw text into structured numbers. This critical conversion happens in two distinct technical steps.
The Tokenization Phase
Tokenization is the specific process of breaking raw text strings into smaller structural units. These individual units are called tokens.
Tokens can represent complete words, partial sub-words, or even individual characters.
Modern software systems primarily utilize sub-word tokenization algorithms to maximize computational efficiency.
The algorithm analyzes a massive training dataset to find the most frequent character combinations. It groups these frequent combinations into permanent single tokens. The system handles highly complex or rare words by breaking them down into recognizable sub-word fragments.
A complex word might split into a recognizable prefix, a root, and a suffix.
Once the text string is properly segmented, the system assigns a unique integer identifier to each token.
The computational model possesses a strictly fixed vocabulary of these predefined tokens. Every piece of input text ultimately becomes a simple linear array of integer values.
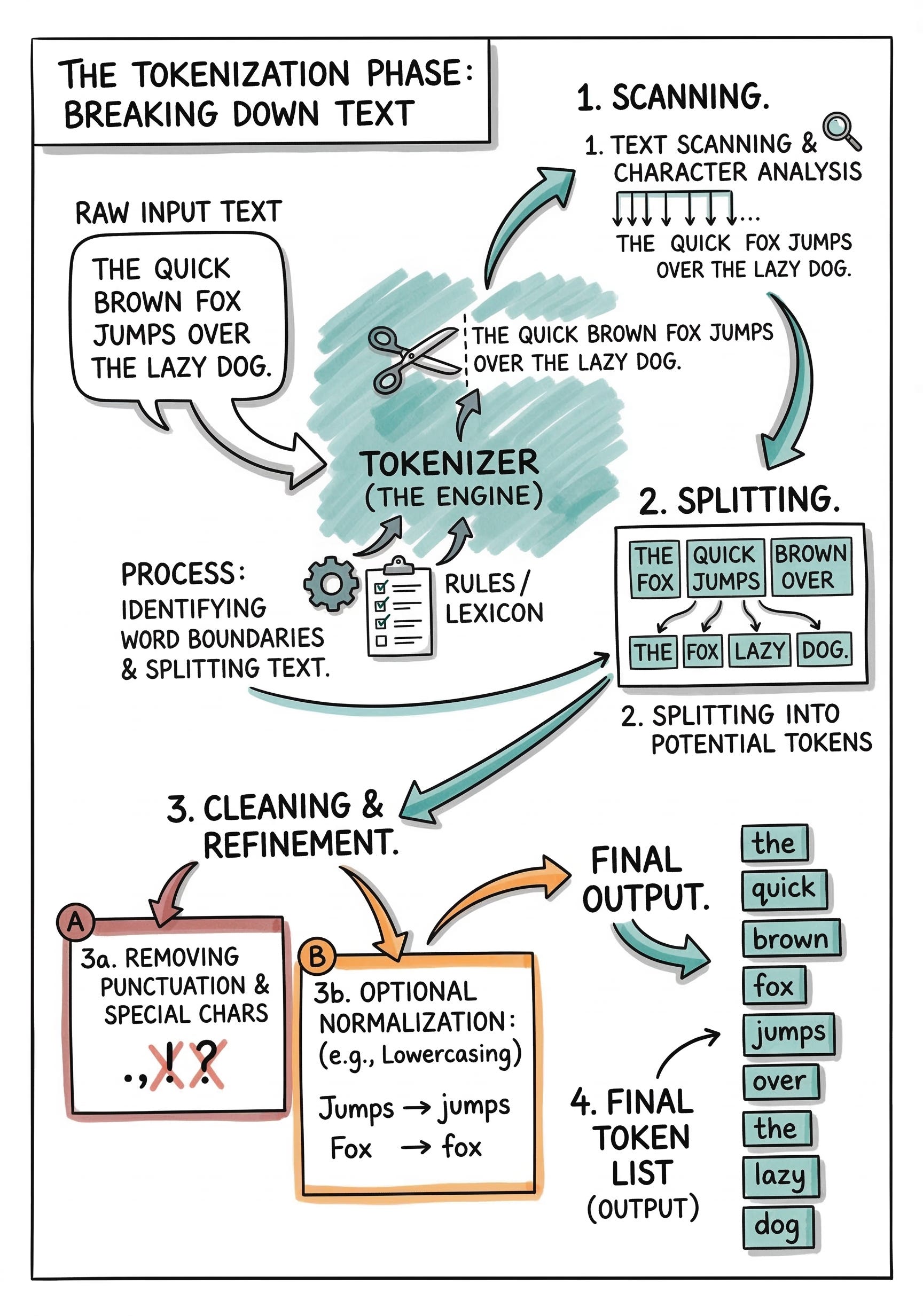
This numerical array serves as the absolute first step toward advanced mathematical processing.
Generating Vector Embeddings
Integer identifiers alone do not provide enough contextual information for the neural network.
The specific integer assigned to a token does not represent its grammatical context or structural relationships.
The system must convert these isolated integers into a significantly richer mathematical format. It uses a technique called vector embeddings to achieve this necessary transformation.