
Deconstructing Bloom Filters: Hash Functions, Bit Arrays, and False Positives
Master the complete architecture of Bloom filters for your upcoming system design interviews with this highly detailed 2026 technical guide.


Modern software platforms process millions of network requests every single second.
A massive structural bottleneck occurs when backend databases must constantly verify if specific records exist.
Querying a physical storage disk for data that does not actually exist wastes precious computational resources. This database lookup problem causes severe latency and system crashes across distributed networks.
Understanding how to intercept and filter these empty queries is absolutely critical for building a scalable architecture.
To solve this massive performance issue, system architects rely on highly specialized technical components. These components act as a lightweight shield sitting directly in front of the heavy database. They mathematically guarantee that when a requested record is completely missing from the system.
By instantly dropping invalid requests, the primary database can dedicate all its processing power to valid data. This technical concept is a fundamental requirement for mastering backend engineering and passing technical interviews. We will explore exactly how this mechanism operates and why it is highly efficient.
What Is A Bloom Filter?
A Bloom filter is a highly space efficient data structure used heavily in computer science. Its primary job is to test whether a specific piece of data is currently part of a larger dataset. It belongs to a specialized technical category known as probabilistic data structures.
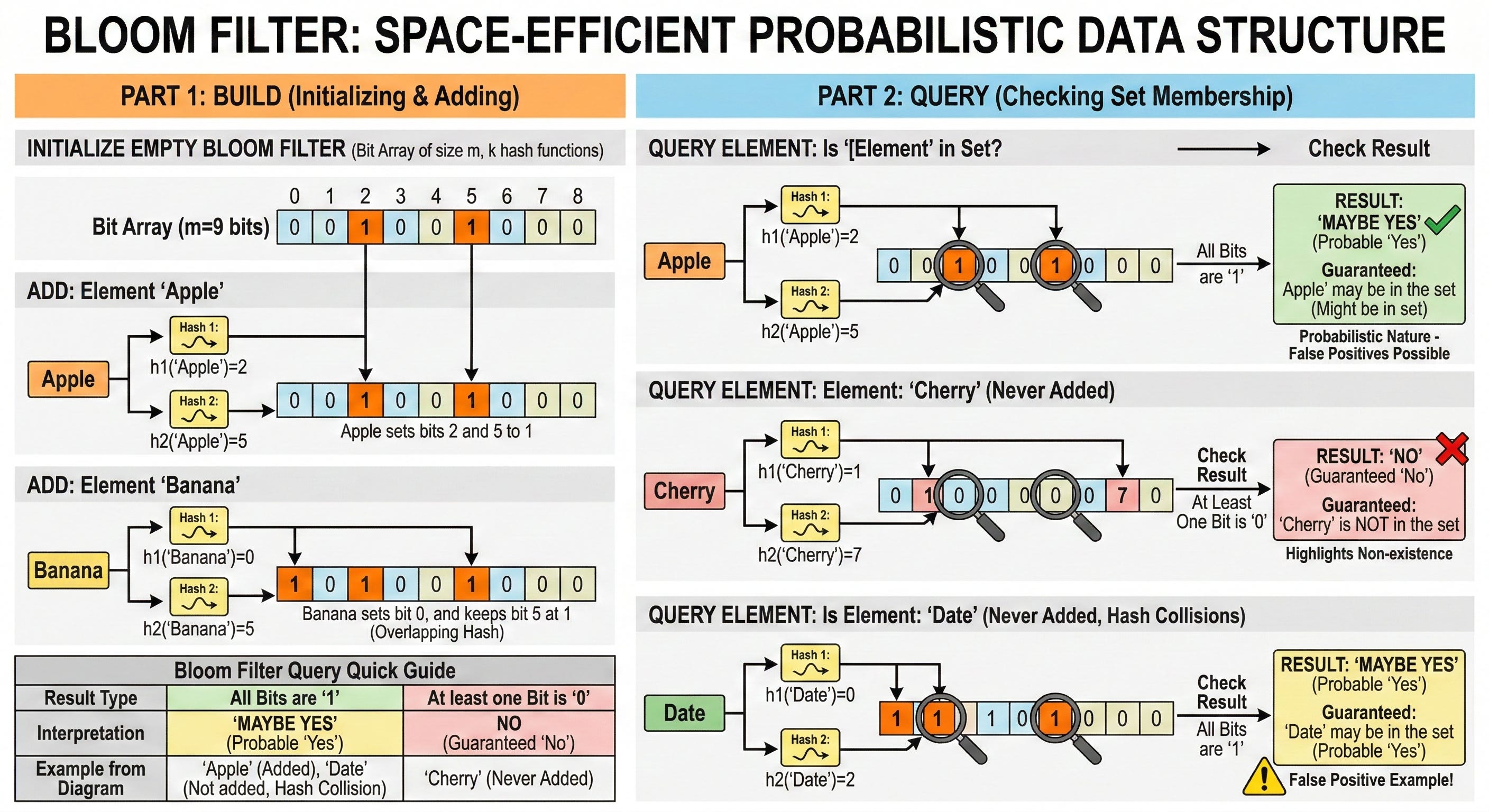
A probabilistic data structure is a framework that does not guarantee an exact answer in every scenario.
The Efficiency Advantage
Traditional data structures provide absolute certainty.
If a software system asks a standard array if a number exists, the array answers with a definitive yes or no.
Probabilistic data structures sacrifice a tiny amount of accuracy in exchange for massive savings in computer memory and processing speed. When a program queries this specific filter, it never returns the actual data.
Two Possible Answers
Instead, it returns one of two highly specific mathematical answers. It will either say that the data is definitely not present in the dataset.
Alternatively, it will say that the data is possibly present in the dataset. This inherent uncertainty might initially sound like a major architectural flaw.
However, this exact probabilistic nature allows it to use a tiny fraction of the memory that standard storage methods strictly require.