
System Design Fundamentals: The Complete Guide to High Availability
A complete educational guide covering high availability architecture. Understand automated failover, stateless servers, and database replication.

This guide will explore:
Understanding core system availability metrics
Eliminating single points of failure
Implementing redundant server architectures safely
Managing automated traffic load balancing
Replicating stateful database information securely

Software platforms constantly face unexpected hardware degradation and sudden network outages.
A primary server will eventually experience a fatal hardware crash due to physical limitations. When this inevitable failure occurs, the entire digital application instantly drops offline.
All data processing stops completely, resulting in immediate and catastrophic service loss.
This total system failure creates a massive technical crisis for modern engineering teams.
High availability is the foundational architectural strategy that solves this exact computational problem. It prevents these severe system crashes from causing noticeable service interruptions.
The core concept focuses on ensuring an application continues running smoothly even when individual internal parts break down.
Instead of depending on one vulnerable machine, the system intelligently distributes work across multiple identical machines.
What Exactly is High Availability?
High availability is a structural design approach that guarantees a specific level of operational performance. It focuses heavily on maximizing the time an application successfully processes network requests.
Building a highly available system means accepting that physical hardware will always fail eventually.
Our architecture must be specifically designed to detect these failures instantly. It must route operations to healthy components automatically without any human input. The main objective is to completely hide internal hardware failures from the end user.
If a backend component dies, the system simply redirects the workload in milliseconds.
Measuring Success with Nines
Engineers rely on strict mathematical percentages to measure operational success accurately.
This percentage represents the total time a system remains online and accessible over a year.
The software engineering industry refers to this exact metric as the nines of availability.
A system with two nines of availability operates ninety-nine percent of the time.
This percentage might sound excellent, but it allows for over three days of total downtime per year. Three nines means the system operates at a percentage of 99.9 overall.
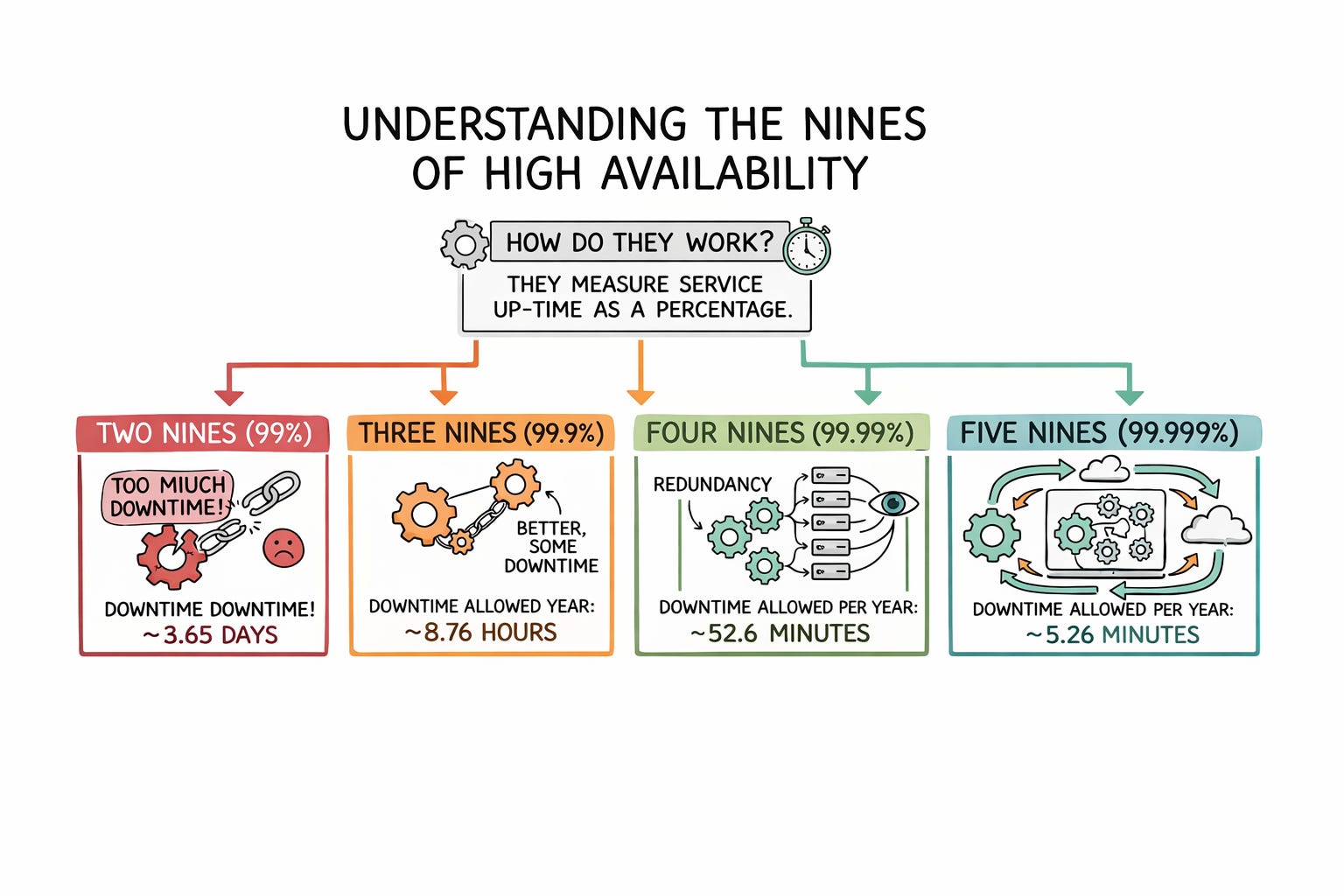
This stricter metric reduces allowed downtime to exactly eight hours per year.
Four nines allows only fifty-two minutes of annual downtime.
Five nines is considered the ultimate gold standard in modern system design. It allows for just five minutes of total downtime per year. Achieving five nines requires extreme architectural planning and fully automated recovery mechanisms.
Identifying Single Points of Failure
The Danger of Centralization
When we build a resilient system, we must first find its structural weaknesses.
A single point of failure is any component that causes the entire system to stop working if it crashes. Finding and removing these vulnerable components is the first mandatory step in system design.
A standard basic architecture often features one web server and one central database. The web server handles all the application logic, and the database stores all the permanent data. Both of these standalone components act as severe single points of failure.
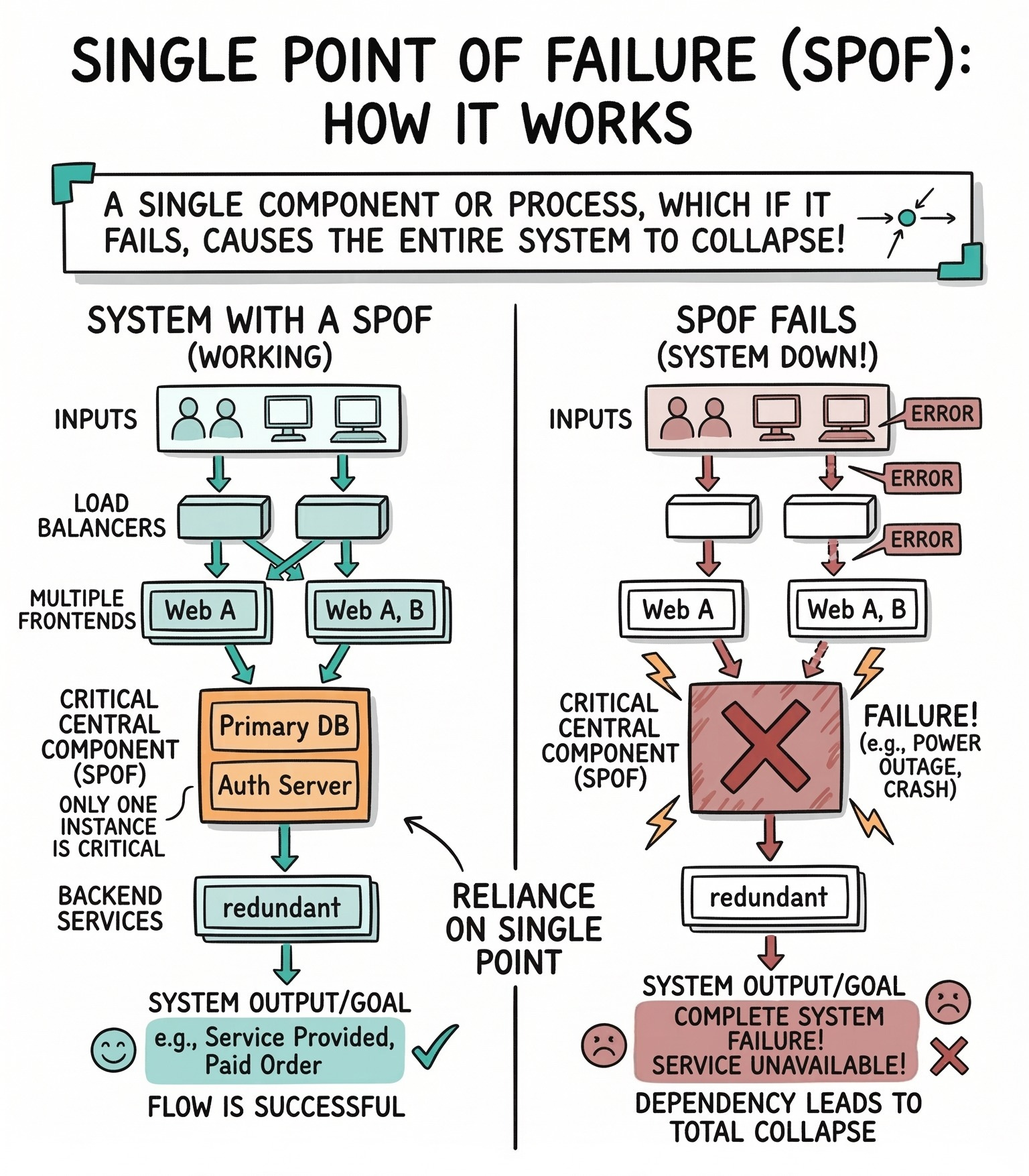
The entire platform depends entirely on their continuous operation.
Finding the Weak Links
If the solitary web server loses electrical power, the application drops offline completely. The system cannot process any new network traffic.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.