
Deconstructing Gossip Protocol: Anti-Entropy, Merkle Trees, and Heartbeats
Understand the core concepts of eventual consistency, cluster membership, and network broadcasting limits in massive distributed networks.

Scaling a distributed database requires perfect state synchronization.
Modern system architecture demands that thousands of individual servers hold identical data simultaneously.
Relying on a single central server to coordinate all these constant updates creates a severe bottleneck.
The central server will eventually crash under the massive network load, bringing the entire application offline.
This creates a critical need for highly decentralized communication frameworks.
Understanding the Gossip Protocol is essential for solving this specific engineering challenge. It allows massive systems to share state across thousands of nodes without needing a central coordinator.
This concept is a fundamental pillar of modern distributed system design.
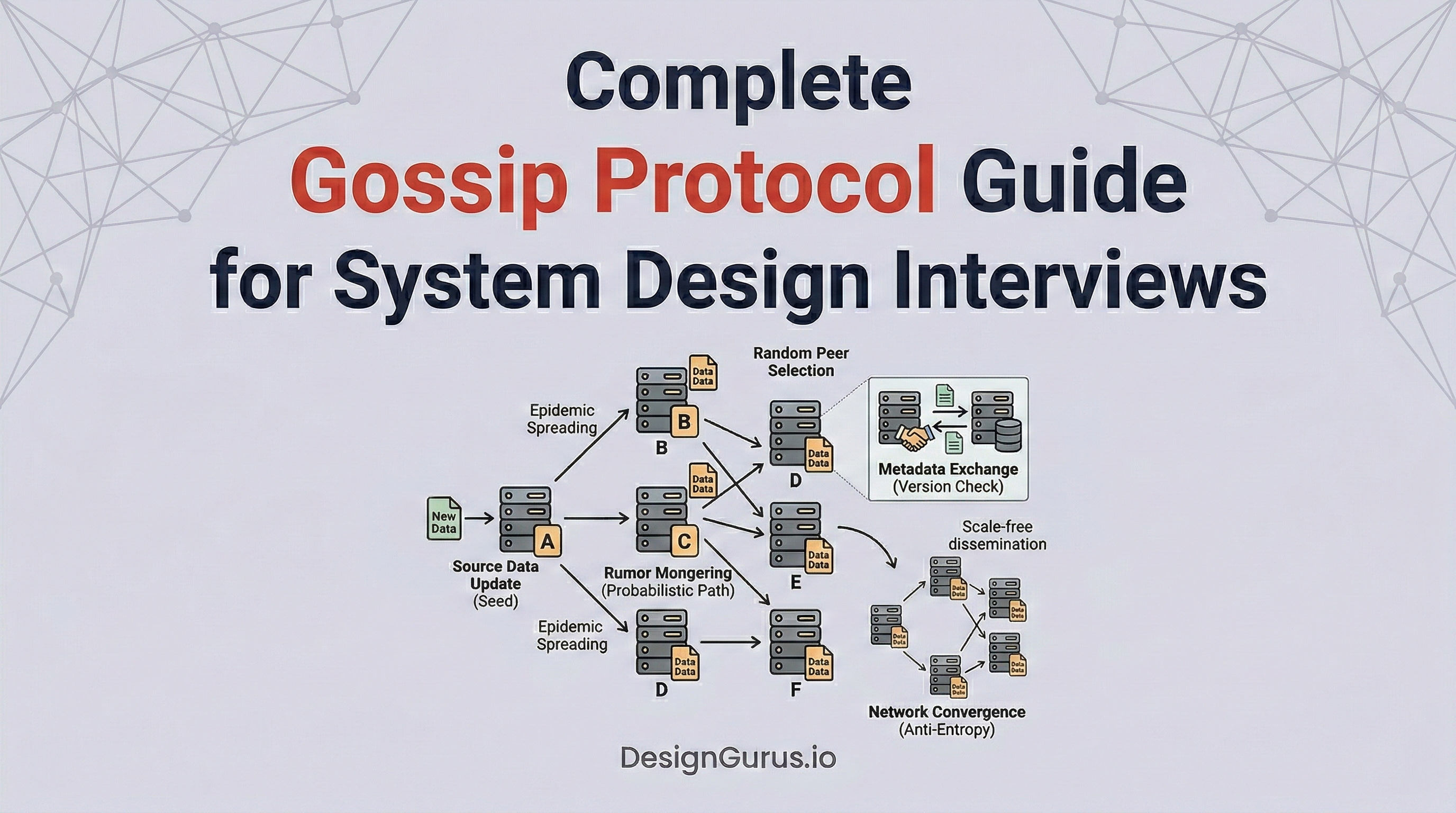
Consider a simple technical scenario involving four independent servers.
Server one receives a brand new configuration file from an external source.
Instead of broadcasting this file to everyone at once, server one randomly selects server two and shares the update.
During the very next time interval, both server one and server two randomly select new targets. Server one might select server three, while server two selects server four.
The data spreads exponentially across the entire cluster through this randomized sharing process. This continues until every single server holds the exact same updated configuration file.
What is the Gossip Protocol?
To truly grasp this concept, we first need to define a few basic technical terms.
A node is simply a single server operating within a larger network.
A cluster is the complete group of these connected nodes working together. The state refers to the actual data stored on these nodes at any given moment.
The Gossip Protocol is a decentralized method for nodes to share their state. They do this without relying on any central registry or master controller.
Instead of one main server pushing updates out, all the nodes take equal responsibility for sharing the data. They achieve this through constant, randomized, and periodic communication.
Every second, a node will randomly select a few other nodes in the cluster. It will package up its current state and send it to those selected peers.
When the peers receive this data, they update their own local records immediately.
Then, they repeat the exact same process with other random peers.
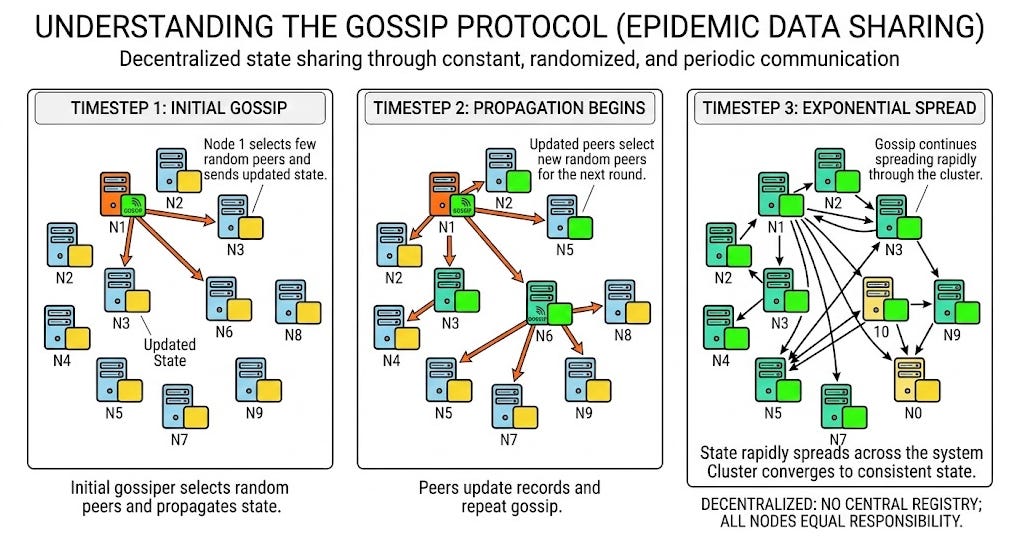
The ultimate goal of this process is convergence.
Convergence is the specific moment when every single node in the network holds the exact same updated data.
Because the protocol relies on continuous mathematical sharing, convergence is guaranteed to happen eventually.
Why Centralized Systems Fail at Scale
To appreciate this decentralized approach, system design candidates must explore why older methods fail.
In a traditional architecture, engineers often use a single leader node.
This leader node holds the absolute truth regarding the state of the network.
If the cluster has ten follower nodes, the leader simply opens ten connections and sends the data.