
System Design Deep Dive: Why Redis is Single-Threaded and Blazing Fast
Master Redis for your next system design interview. Learn why Redis is single-threaded, and understand core concepts like I/O multiplexing, LRU eviction policies, Redis Replication & Sharding.

Software applications frequently experience severe performance bottlenecks as they attempt to scale.
Traditional databases store data on physical disks to ensure data remains completely safe when power goes out. Fetching data from a physical disk requires complex mechanical operations or solid-state drive interactions. These physical interactions consume significant time in computing terms, creating high response times.
When a system attempts to process millions of requests simultaneously, the database becomes rapidly overwhelmed.
Read times increase drastically, and applications stall completely while waiting for the database to return the requested information. This physical limitation of disk storage creates a massive barrier to building highly responsive software systems.
Engineers must find technical ways to bypass the slow physical disk to deliver data instantly.
Understanding how to solve this specific latency problem is absolutely critical for building modern software architectures.
This requires a completely different architectural approach to data storage and data retrieval.
What Is Redis?
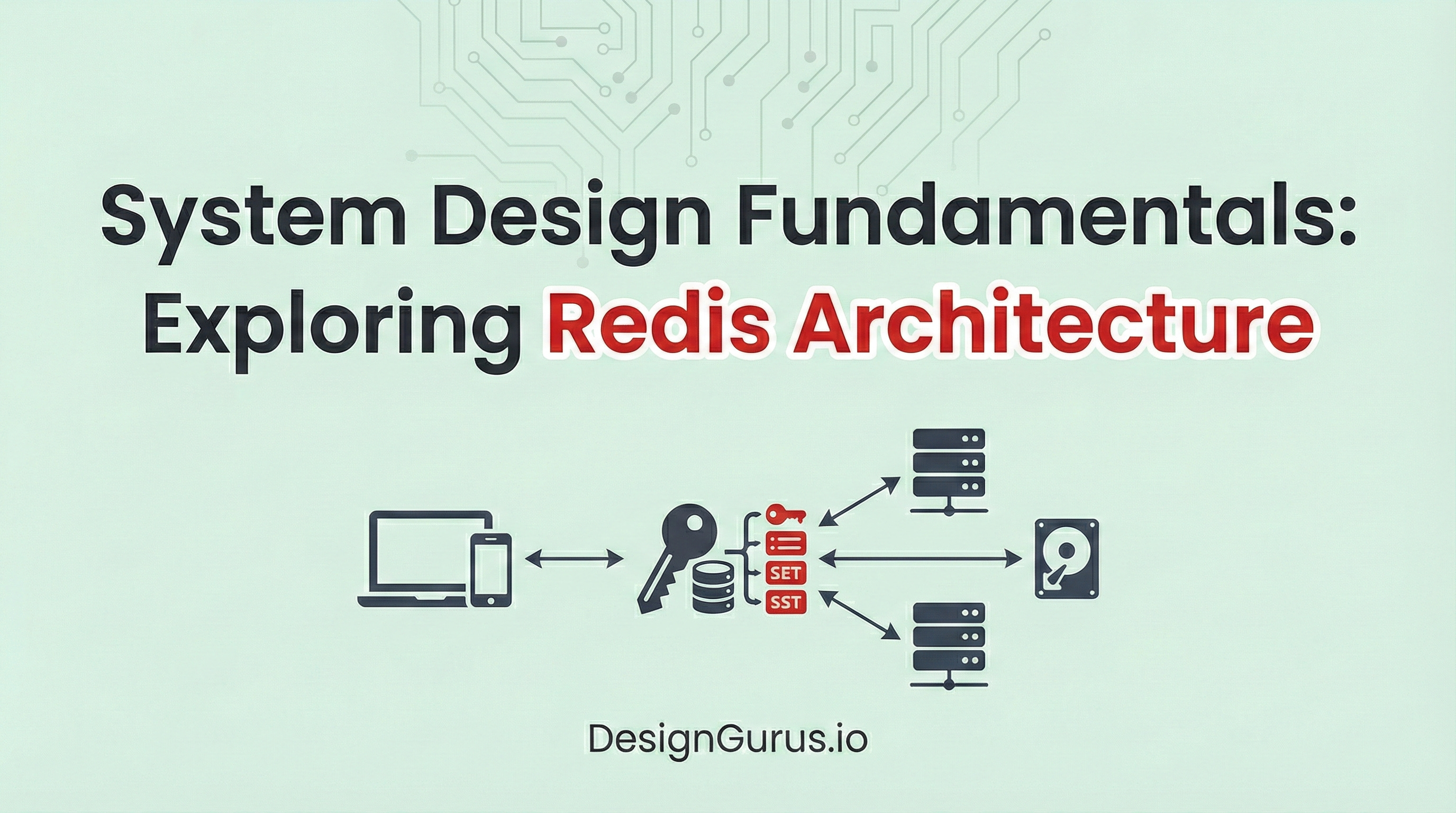
To solve the disk latency problem, engineers rely on an architectural component called Redis.
The name technically stands for Remote Dictionary Server. It operates primarily as an in-memory data structure store.
This means it stores and accesses all of its data directly in the Random Access Memory of the host server.
Because it operates entirely in memory, it eliminates the need to access a slow physical disk.
A standard database might take several milliseconds to return a piece of data over the network. This in-memory store can return that exact same piece of data in a tiny fraction of a millisecond.
This extreme speed makes it an essential component in large-scale distributed systems.
The system is utilized primarily as a key value database.
A key-value database stores data as a collection of unique identifiers linked directly to specific data blocks.
The unique identifier is called the key, and the data block is called the value.
This structure completely avoids the rigid tables and columns used by traditional relational databases.
If an application needs to check the authentication status of a user session, it uses a unique session token as the key.
The in memory database will instantly return the user data strictly associated with that specific key. It performs a direct mathematical lookup in the memory space. The system does not need to search through complex tables to find the correct answer.
The Single-Threaded Architecture
Understanding the internal mechanics of this system helps engineers make better architectural decisions.
The most surprising fact about this technology is its internal execution model. It operates primarily on a single-threaded architecture. This means it uses only one processor core to execute all the commands it receives from clients.
In modern computing, engineers typically use multithreading to handle multiple tasks concurrently.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.