
System Design for AI: How Transformers and Vector Databases Work
Learn the difference between AI Agents and LLMs. This guide covers vector databases, embeddings, and context windows for system design candidates.


Artificial Intelligence has shifted from a theoretical field of study into a practical utility for modern software engineering.
The rapid introduction of new architectures and methodologies often leaves developers scrambling to decipher the terminology.
The challenge for software engineers is no longer accessing these tools but understanding the underlying mechanics to build reliable systems.
This guide serves as a technical breakdown of the core components defining the current AI landscape, providing clear definitions and structural explanations of how these systems function.
Key Takeaways
Transformers utilize attention mechanisms to process entire sequences of data simultaneously rather than sequentially.
Large Language Models (LLMs) generate text based on statistical probability and do not possess inherent factual knowledge.
Retrieval-Augmented Generation (RAG) mitigates hallucinations by connecting models to external, verifiable data sources.
AI Agents extend LLM capabilities by executing code and interacting with APIs to complete multi-step tasks.
Vector Databases enable semantic search by converting text into numerical representations called embeddings.
Transformers
To understand modern AI, one must first understand the architecture that powers it.
The Transformer architecture changed how computers process language. Before its introduction in 2017, models processed data sequentially.
If a model read a sentence, it looked at the first word, then the second, and so on. This approach caused the model to lose context in long paragraphs because it would “forget” the beginning of the sentence by the time it reached the end.
Transformers introduced a mechanism called self-attention.
This allows the model to look at every word in a sequence simultaneously. It assigns a “weight” or importance to the relationship between words, regardless of how far apart they are in the text.
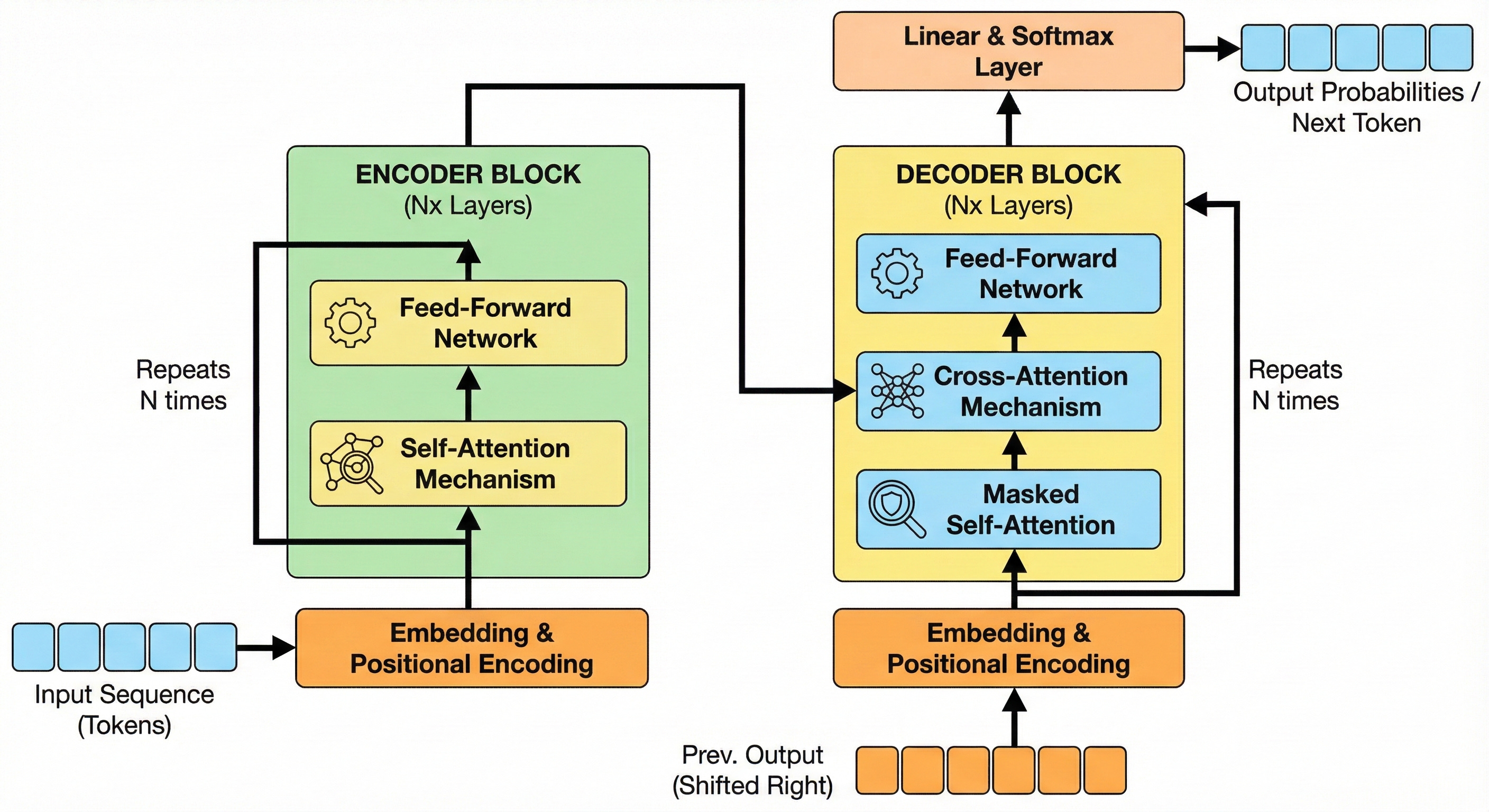
This parallel processing capability enables the model to understand complex nuances and dependencies in language much faster than previous methods.
The Predictor: Large Language Models (LLMs)
An LLM is a deep learning algorithm capable of recognizing, summarizing, translating, predicting, and generating text. These models are trained on massive datasets containing significant portions of the public internet.
