
System Design Essentials: ZooKeeper, Etcd, and Consistency
Learn how distributed systems maintain consistency. We break down ZooKeeper, Etcd, and the complex mechanics of consensus algorithms like ZAB and Raft.

This blog explains:
distributed consensus and its working
leader election process
Apache ZooKeeper
Etcd
MVCC
Comparison of architectures

Distributed systems present a unique set of challenges that do not exist in single-machine software development.
When an application runs on a solitary server, the state is absolute.
The memory and the disk are unified, and the operating system enforces a strict order of operations.
However, modern infrastructure requires applications to span across dozens, hundreds, or even thousands of servers to handle scale and provide availability.
This physical separation introduces a critical problem: uncertainty.
Hardware is imperfect.
In a distributed cluster, one group of servers may lose connection with another group, yet both groups remain operational.
Without a strict mechanism to coordinate their actions, these isolated groups might simultaneously attempt to modify the same data in conflicting ways. This leads to data corruption, lost transactions, and system-wide instability.
The solution to this problem is Distributed Consensus. It is the set of protocols and algorithms that allows a collection of unreliable machines to agree on a single source of truth.
ZooKeeper and Etcd are the two most prominent technologies used to implement this coordination. They serve as the reliable backbone for massive platforms like Kubernetes, Kafka, and Hadoop.
The Core Problem: Consistency in Chaos
To understand why ZooKeeper and Etcd are necessary, one must first understand the specific failure modes of distributed networks.
The most dangerous scenario is the Network Partition.
Consider a cluster of five database nodes that must stay synchronized.
If a network switch fails, the cluster might be sliced into two isolated groups: Group A with two nodes, and Group B with three nodes.
If a client connects to Group A and updates a record, and another client connects to Group B and deletes that same record, the system has entered a “Split-Brain” state. When the network is repaired, the system has two conflicting histories for the same data.
Distributed consensus systems solve this by enforcing a mathematical rule known as Quorum.
The Mathematics of Quorum
Quorum is the minimum number of votes required for a distributed system to perform a valid operation. It ensures that only one group of nodes can ever accept writes at a time.
The formula for a quorum is (N / 2) + 1, where N is the total number of nodes.
In a 3-node cluster, the quorum is 2.
In a 5-node cluster, the quorum is 3.
In the partition scenario described above, Group A (2 nodes) typically cannot form a quorum because 2 is not a majority of 5. Therefore, Group A automatically essentially freezes and refuses to process write requests.
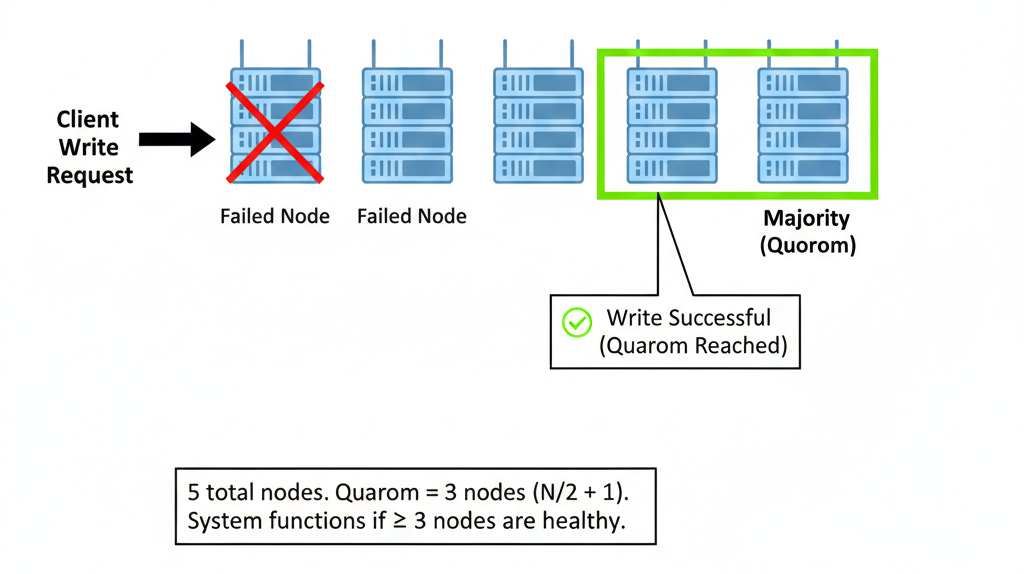
Group B (3 nodes) constitutes a majority. It continues to operate normally. This guarantees that split-brain never corrupts the data.
