
Stop Using Databases for Messaging: The Architectural Brilliance of Apache Kafka
Discover the architecture behind Apache Kafka's massive throughput. Learn how it achieves speed using sequential disk I/O, zero-copy system call, OS pagecache, message batching & horizontal partition.


Modern software architectures generate massive volumes of internal data every single second.
Application logs, system metrics, and state updates must flow continuously between different microservices.
Traditional database architectures quickly fail when forced to handle this intense flood of information. Writing millions of small data points to a standard database creates a massive performance bottleneck.
This engineering problem requires a specialized tool designed specifically for high throughput data streaming.
Apache Kafka was built perfectly to solve this exact hardware limitation. It is a distributed event streaming platform engineered to move massive amounts of data instantly.
Understanding the internal mechanics of this platform is critical for mastering scalable software architecture.
The Core Problem Of Data Movement
Moving data between different software applications is surprisingly difficult at a large scale.
The process requires constant interaction between the software code and the physical server hardware. Every time a piece of data is sent, the server must utilize its processor, memory, and network components. These hardware components have strict physical limitations on how fast they can operate.
Standard database systems try to process and organize every single piece of data as it arrives. They build complex search indexes to make finding that information easier later on. Building these search indexes requires the database to perform many small write operations across different files.
This constant organizing process consumes massive amounts of computing power.
Kafka abandons this complex organizing process entirely to focus purely on writing speed.
Redefining Storage Mechanics
Most software attempts to keep all fast data in memory.
Random Access Memory is the extremely fast temporary storage inside a computer server.
However, this temporary memory is highly expensive and severely limited in total size. Relying strictly on temporary memory limits how much information a system can hold at one time.
Kafka takes a completely different approach by relying heavily on the permanent hard drive. Hard drives are usually considered the slowest part of a computer server. Writing to a hard drive typically causes software to pause and wait for the physical hardware.
Kafka makes the permanent hard drive incredibly fast by fundamentally changing how data is written to it.
Mastering Disk Input And Output
To understand this incredible speed, we must examine how a hard disk writes data.
There are two primary ways an operating system saves information to a storage disk. The first method is random access.
Random access happens when the storage drive jumps around to different physical locations to write small pieces of data.
This jumping around is incredibly slow because mechanical parts must physically move across the disk. Even on modern solid state drives, random access requires the hardware to constantly update scattered storage blocks.
The second method is sequential access.
Sequential access means writing data in one long continuous block.
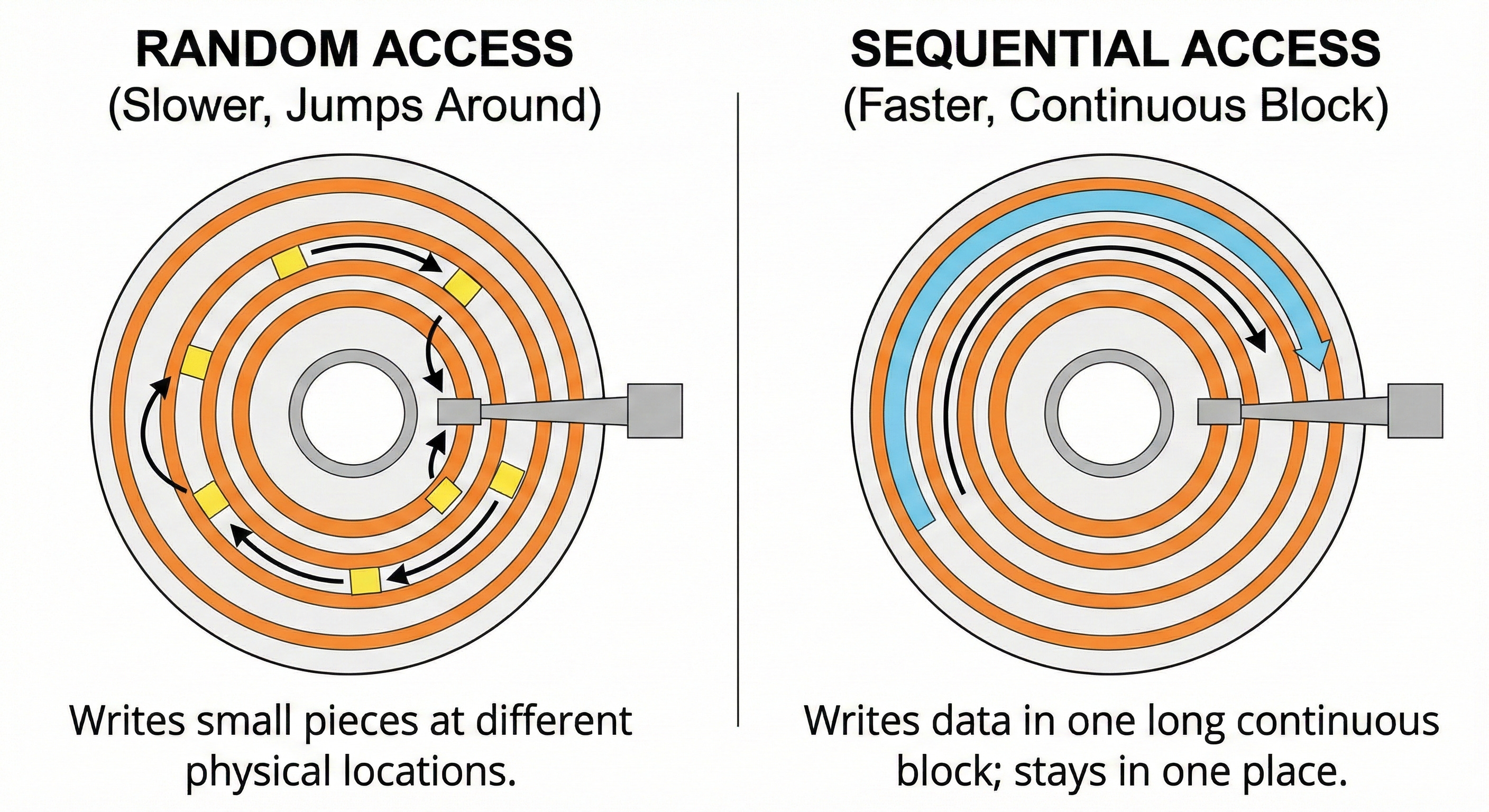
The disk stays in one place and writes information continuously as the hardware operates. Sequential disk access can actually process information faster than random memory access.
Kafka completely forces all data to be written using strict sequential access.
The Append Only Log File
Kafka implements sequential access by using a specific file structure called a log.
A log is simply a file that records software events in the exact order they happened.
When a new message arrives at the server, the software never searches for an empty spot. It never attempts to update or change old information stored in the middle of a file.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.