
Mastering Latency, Sharding, and CAP Theorem for System Design
Transition from coder to architect. Move beyond syntax and logic errors to understand the structural challenges of building large-scale applications.


Software development typically takes place in a highly controlled environment.
The code runs on a single machine where the memory is fast, the processor is reliable, and variables stay exactly where they are placed.
This environment is deterministic. It allows a developer to focus entirely on logic, syntax, and algorithm efficiency.
However, modern software rarely lives in isolation.
It spans across hundreds or thousands of servers. It serves millions of concurrent users. It must survive hardware failures and network outages without crashing.
Transitioning to this level of engineering requires a fundamental shift in perspective. It is no longer enough to write a perfect algorithm.
One must understand how that algorithm behaves when it is split across multiple computers that must coordinate over an unreliable network. This is the domain of distributed systems.
This guide explores the foundational concepts required to bridge the gap between writing code and designing architecture. It breaks down the mechanics of how systems talk, how they fail, and how they grow.
The Limitation of the Single Machine
Every application relies on resources. These resources are the Central Processing Unit (CPU), Random Access Memory (RAM), storage disks, and network bandwidth.
In a standard development environment, these resources feel infinite.
If a function is slow, the immediate solution is often to optimize the code.
If the database is slow, the solution might be to add an index.
But there is a physical limit to how much power a single computer can hold. A motherboard can only accept a certain amount of RAM. A processor can only handle a specific number of instructions per second.
When an application becomes popular, the traffic eventually exceeds what one computer can handle. The server crashes. It runs out of memory. It stops responding.
At this distinct moment, the problem changes. It is no longer a coding problem. It is an architectural problem.
To solve this, engineers do not just buy a bigger computer. They add more computers. They distribute the workload.
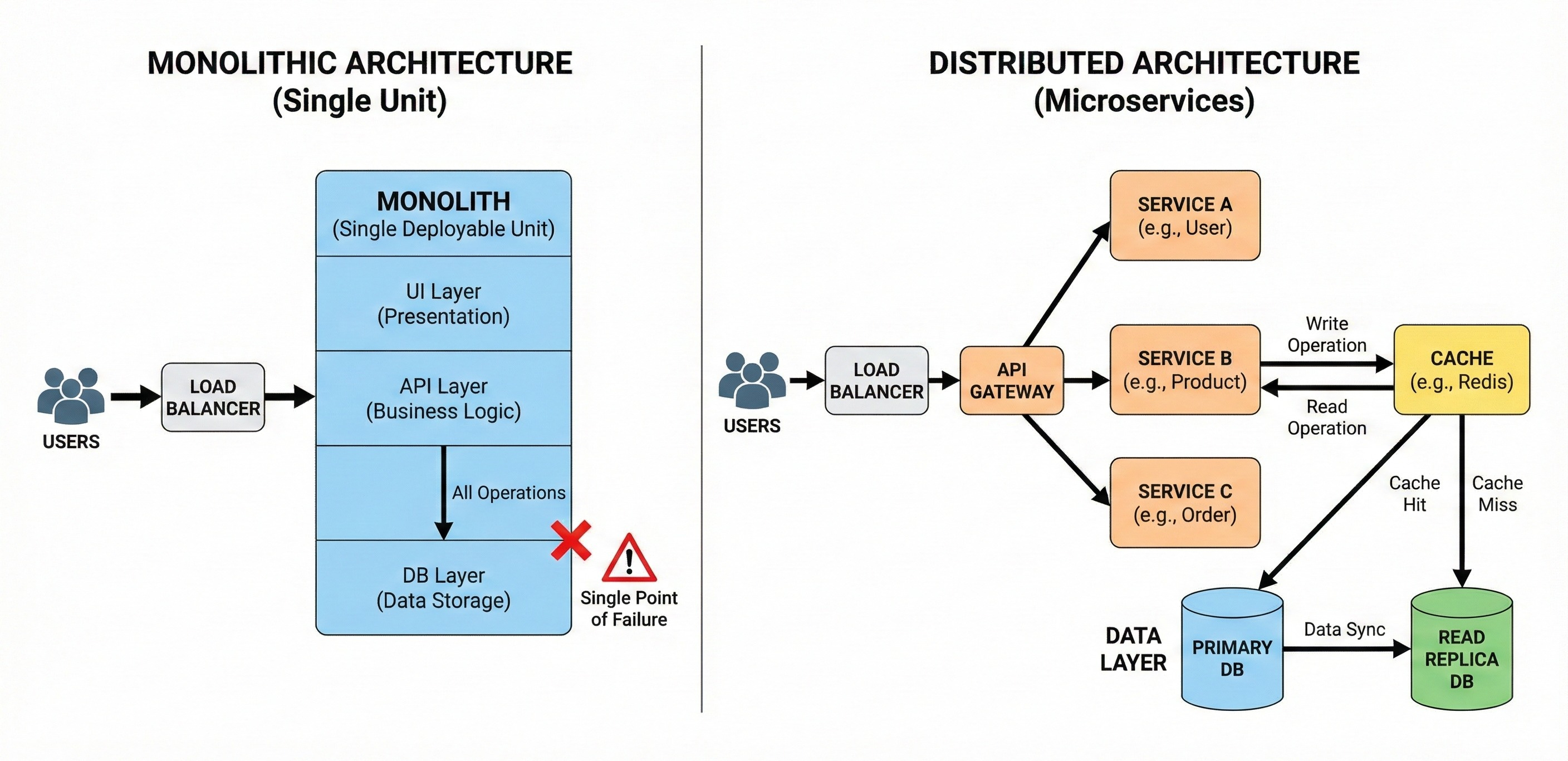
This decision introduces a new set of challenges that do not exist when code runs on a single machine.
The Network is the New Variable
The most significant difference between a local application and a distributed system is the network.
When a function calls another function within the same program, it happens almost instantly.
The computer places the instruction in memory, the CPU executes it, and the result is returned. This process is reliable. It almost never fails unless the code itself is broken.
In a distributed system, components are separated by physical distance. They might be in the same room, or they might be on different continents. To communicate, they must send messages over wires or fiber optic cables.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.