
Stateful vs Stateless Services: Key Differences Explained Simply
Learn the difference between stateful and stateless services. Explore pros, cons, scalability, fault tolerance, and when to use each in system design.

This blog defines stateful and stateless services and explains how each approach affects scalability. It also explores how distributed systems manage state, with practical strategies to handle data across multiple servers.
Imagine you’re shopping online and add items to your cart.
You come back later and your items are still there – the website remembered you!
That site likely uses a stateful service.
Now think of another site where every time you return, your cart is empty and you have to start over.
That’s a stateless service treating each visit like a new interaction.
Both approaches have pros and cons, and understanding them will help you design scalable, reliable systems.
So, let’s get started!
What is a Stateful Service?
A stateful service remembers information between requests.
For example, when you log in or add items to a cart, a stateful server stores your data and preferences.
Each new request can then use that stored context – it’s like the server already knows who you are. This gives a seamless, personalized experience.
The downside is the server must work harder to maintain and sync that data, which can complicate scaling and recovery.
What is a Stateless Service?
A stateless service, in contrast, forgets everything about previous calls. It doesn’t keep session data after responding, so each request is handled with no knowledge of any before it.
If information from an earlier request is needed, the client must send it again or the server must fetch it from a database.
For example, an API might require every request to include your authentication token and all necessary details, so the server can process it without any memory of prior requests.
Keep in mind, “stateless” doesn’t mean no state exists; it means any state is stored outside the service (in a database or cache).
This allows any server in a cluster to handle a request because none rely on local session memory.
Key Differences Between Stateful and Stateless
Here are the major differences at a glance:
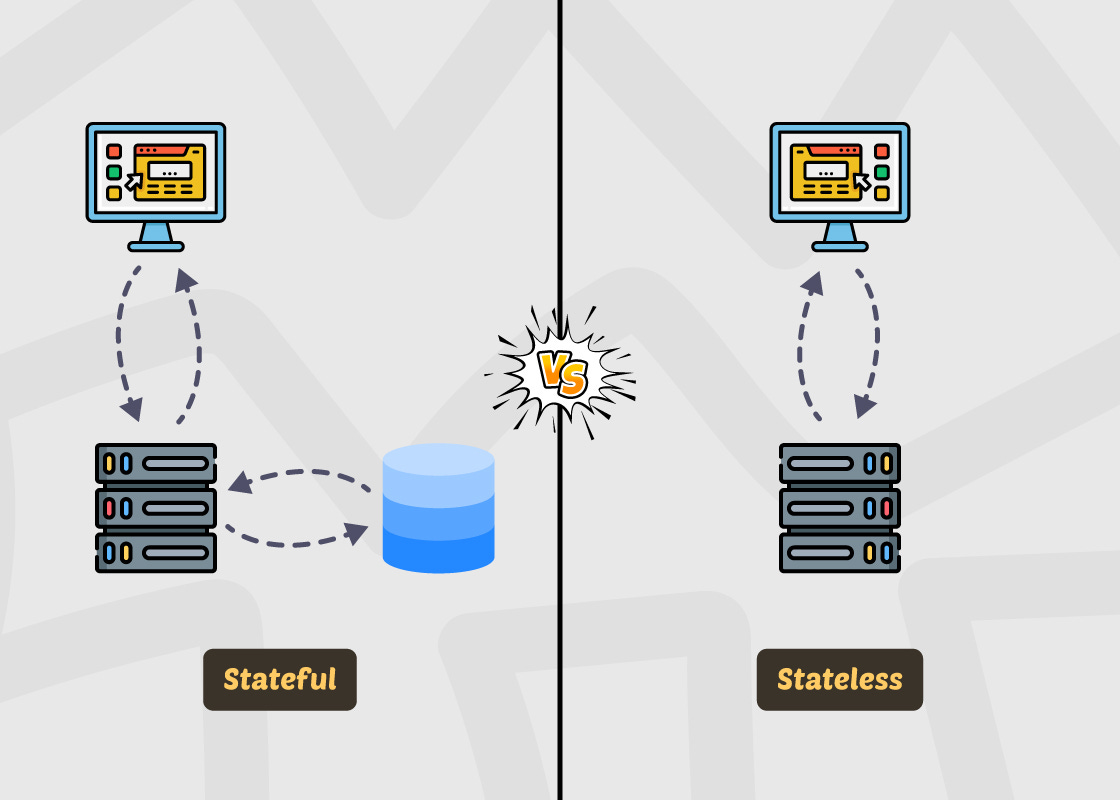
Session Persistence: Stateful services store user session data on the server (they “remember” past interactions). Stateless services do not – each request is processed with no knowledge of earlier requests.
Scalability: Stateless services are easier to scale horizontally because any server can handle any request. Stateful services are harder to scale since user-specific data is tied to one server, often requiring sticky sessions or session replication.
Fault Tolerance: Stateless systems are more fault-tolerant: if one server goes down, no user session is lost and another server can step in seamlessly. Stateful systems risk session loss if a server fails, unless you implement replication or other failover measures.
Performance: Stateful services can respond faster for repeat requests (data is in memory), but they use more memory/CPU and can bog down as more users connect. Stateless services might do slightly more work per request (e.g. reloading data), but each server stays lightweight and can scale out under heavy load.
Use Cases: Use stateful architecture when an app needs to maintain context across steps or real-time interactions (chat apps, shopping carts, game sessions). Use stateless design for independent requests that don’t require history (public REST APIs, static content). In practice, many systems mix both (e.g. a stateless web frontend with a stateful database for persistence).
Managing State in Distributed Systems
Even if your application servers are stateless, you still have to store state somewhere.
Common strategies include:
Offload State Externally: Remove session burden from the servers by keeping state in external storage or on the client side. For example, store user sessions in a shared database or in-memory cache accessible to all servers. Alternatively, encode the session info in a client-side token that gets sent with each request. In both cases, the server doesn’t hold session data – any server can retrieve or receive the state as needed, making the system more scalable.
Server-Side Session Management: If a service must keep state in memory, use techniques to distribute and protect it. One approach is session replication: copy session data to a shared store or across multiple servers, so no single node is a point of failure. Another approach is sticky sessions, where a load balancer always sends a particular user’s requests to the same server that holds their data. These methods help a stateful service work in a cluster, but they add complexity and can create hotspots if one server gets too many sessions.
Choosing the Right Approach
There’s no one-size-fits-all answer.
For simple request-response services with high traffic (like public APIs or content feeds), a stateless architecture is usually ideal for easy scaling and resilience.
But if your application needs to remember user data or maintain context (a shopping cart, a game session, etc.), you’ll require some stateful components.
Often the best solution is a hybrid: keep as much of the system stateless as possible, and use stateful parts (like databases or caches) only where needed.
In system design interviews (and real-world design), you should be ready to explain how you’d handle state.
If you opt for a stateless design for scalability, clarify where the state is stored externally (for example, in a database or through client tokens).
If you use stateful services, describe how you’d manage scaling and failures (such as using replication or sticky sessions to avoid losing data).
Armed with this understanding, you’ll be able to choose the right approach and build systems that are both user-friendly and scalable.
FAQs
Q: Which is better, stateful or stateless architecture?
Neither is universally better – it depends on the use case. Stateless services excel in scalability and simplicity, since you can easily add servers and any server can handle any request. Stateful services are necessary when you need to maintain user context or data across sessions. Often, the most robust systems use a mix of both approaches.
Q: Why are stateless services more scalable?
Stateless services are more scalable because each request is independent. You can add or remove servers under a load balancer without worrying about sharing session information between them. If one server goes down, another can handle the next request. This flexibility makes scaling out (and replacing servers) very straightforward compared to stateful setups.
Q: How do stateless services handle user sessions or data?
They don’t keep session data on the server. Instead, a stateless service relies on external solutions: for instance, it might store session info in a database or cache that all servers can access, or it issues a token to the client that contains the session details. Every request must include whatever data the server needs to identify the user, so the server itself remains free of stored sessions.