
PostgreSQL vs. DynamoDB vs. Cassandra: A System Design Decision Tree
How to Decide Between PostgreSQL, DynamoDB, and Cassandra in a System Design, Based on Data Model, Scale, Consistency, and Operations

Choosing a database is one of the most consequential decisions in any system design. It is also one of the hardest to reverse, because once data and code are built around a database, switching later is expensive and risky.
A wrong choice early can constrain a system for years.
The difficulty is that the most popular databases are not interchangeable. They represent fundamentally different models, each optimized for different goals, and each making different trade-offs.
Comparing them on a single scale of better or worse misses the point, because the right choice depends entirely on what the system needs.
PostgreSQL, DynamoDB, and Cassandra are three of the most widely used databases, and they sit at three distinct points in this space.
PostgreSQL is a relational database built for structured data and rich queries.
DynamoDB is a fully managed key-value and document store built for effortless scale.
Cassandra is a distributed wide-column store built for massive write throughput and availability. Each excels where the others struggle.
This article cuts through the comparison with a decision tree. It first explains what each database is and what it is best at, then provides a clear set of decision questions that lead to the right choice, followed by a side-by-side comparison and the common mistakes to avoid.
The goal is to replace vague debate with a concrete framework you can follow in a system design.
The Three Databases at a Glance
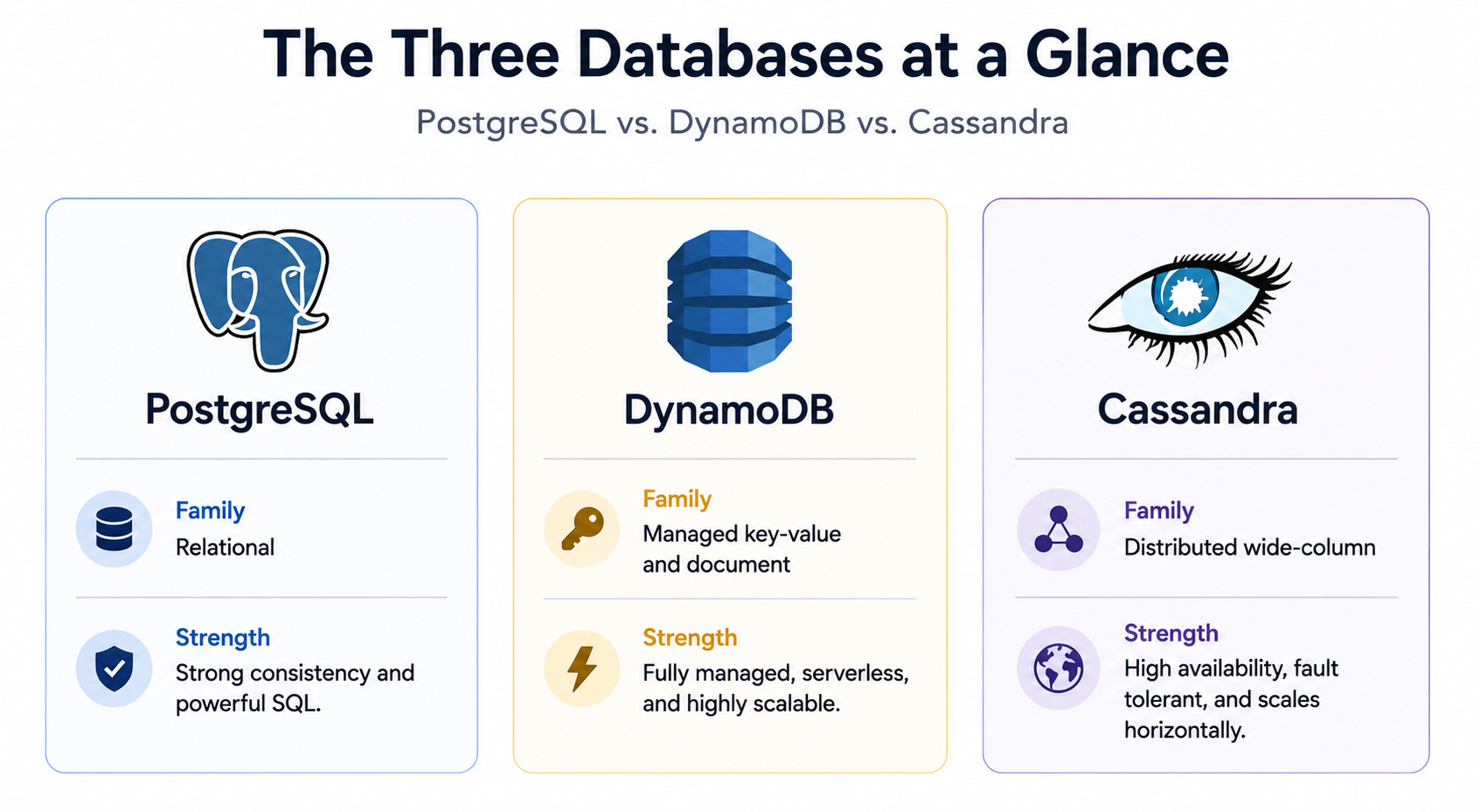
Before the decision tree, it helps to see the three side by side at a high level, because they belong to different families.
PostgreSQL is a relational database. It stores data in tables with defined columns and relationships, uses SQL, and provides strong consistency and transactions. It is built for structured data and flexible, powerful queries.
DynamoDB is a managed NoSQL store offered by AWS, combining key-value and document models. It is serverless and horizontally scalable, designed to deliver low latency at any scale with no operational management.
Cassandra is a distributed wide-column store. It spreads data across many nodes with no single leader, and it is built for very high write throughput, horizontal scale, and high availability across regions.
The differences between them come down to a few core dimensions: the data model, the query flexibility, how they scale, their consistency model, and how much operational work they require.
The decision tree is built around these dimensions. First, here is each database in more depth.
PostgreSQL: The Relational Workhorse
PostgreSQL is a mature, open-source relational database, and it is the default choice for a large share of systems for good reason.
Its core strength is the relational model.
Data is organized into tables with strict structure and explicit relationships between them. This makes it ideal for data that is naturally structured and interconnected, such as users, orders, products, and the relationships among them.
PostgreSQL provides ACID transactions, which guarantee that a group of changes either all succeed or all fail together, preserving correctness. This makes it the right choice for systems where data integrity is critical, such as financial systems, inventory, and anything involving money or important state.
Its query power is another major advantage.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.