
The Mechanics of Service-to-Service Communication: Protocols and Reliability
Master the mechanics of microservices communication. Learn when to use REST vs. gRPC, understand the trade-offs of Synchronous vs. Asynchronous patterns, and implement reliability strategies.


When you write code for a single application, the process is straightforward. You define variables, write functions, and execute logic.
Everything happens within the boundaries of one computer.
The memory is shared. The processor is shared.
If Function A needs data from Function B, it simply accesses the memory address where that data lives. This operation is fast, reliable, and invisible to you as the developer.
However, modern software architecture often requires a different approach.
Instead of one large program, we often build systems composed of many smaller, independent programs.
We call these services.
One service might manage user authentication, while another manages product inventory. These services usually run on different servers, often located in different data centers.
This physical separation creates a fundamental problem.
Service A cannot read the memory of Service B. There is no shared variable that they can both access. To share information, they must send data across a network.
This shift from “memory access” to “network communication” changes everything about how you design software. It introduces latency, complexity, and the risk of connection failures.
This guide will explain the core patterns developers use to enable these services to talk to each other. We will focus on the technical mechanics of how data flows, how services coordinate, and how we handle errors when the network fails.
Serialization and Transport
Before a service can send data, it must prepare that data for travel.
Inside your code, data exists as objects, structs, or classes. These are optimized for your specific programming language and the computer’s memory.
You cannot send a raw Python object or a Java class over a network cable. The other computer might not even be running the same programming language.
To solve this, we use a process called Serialization.
The sender converts the internal memory object into a standard format, such as a string of text or a sequence of binary bytes. This format is language-neutral.
The sender transmits this package over the network.
The receiver catches it and performs Deserialization, converting it back into a memory object that its own code can understand.
Once the data is ready, we need a pattern to control the flow. Broadly speaking, there are two ways to structure this conversation: Synchronous and Asynchronous.
Pattern 1: Synchronous Communication
Synchronous communication is the most common pattern because it closely resembles standard programming logic.
In this model, the interaction happens in a direct loop.
The caller (often referred to as the Client) sends a request and waits for a response. The receiver (the Server) processes the request and sends back the result.
The Blocking Nature
The defining characteristic of this pattern is that it is blocking.
When Service A sends a request to Service B, Service A pauses its current execution. It cannot move to the next line of code. It effectively freezes that specific thread of work until Service B replies.
If Service B is fast, this pause is negligible. However, if Service B is slow, Service A becomes slow. If Service B takes ten seconds to reply, Service A sits idle for ten seconds.
This creates a phenomenon known as Tight Coupling.
The performance and availability of the sender are tied directly to the performance and availability of the receiver. If the receiver fails, the sender fails.
Protocols: REST and gRPC
We need a standard language for these synchronous requests.
There are two primary standards used in the industry.
1. REST (Representational State Transfer): REST is the standard for web communication. It typically uses HTTP as the transport layer and JSON as the data format.
Human-Readable: JSON looks like text. You can read it easily.
Universal: Almost every programming language has built-in support for HTTP and JSON.
Stateless: Each request contains all the information needed to process it. The server does not need to remember previous interactions.
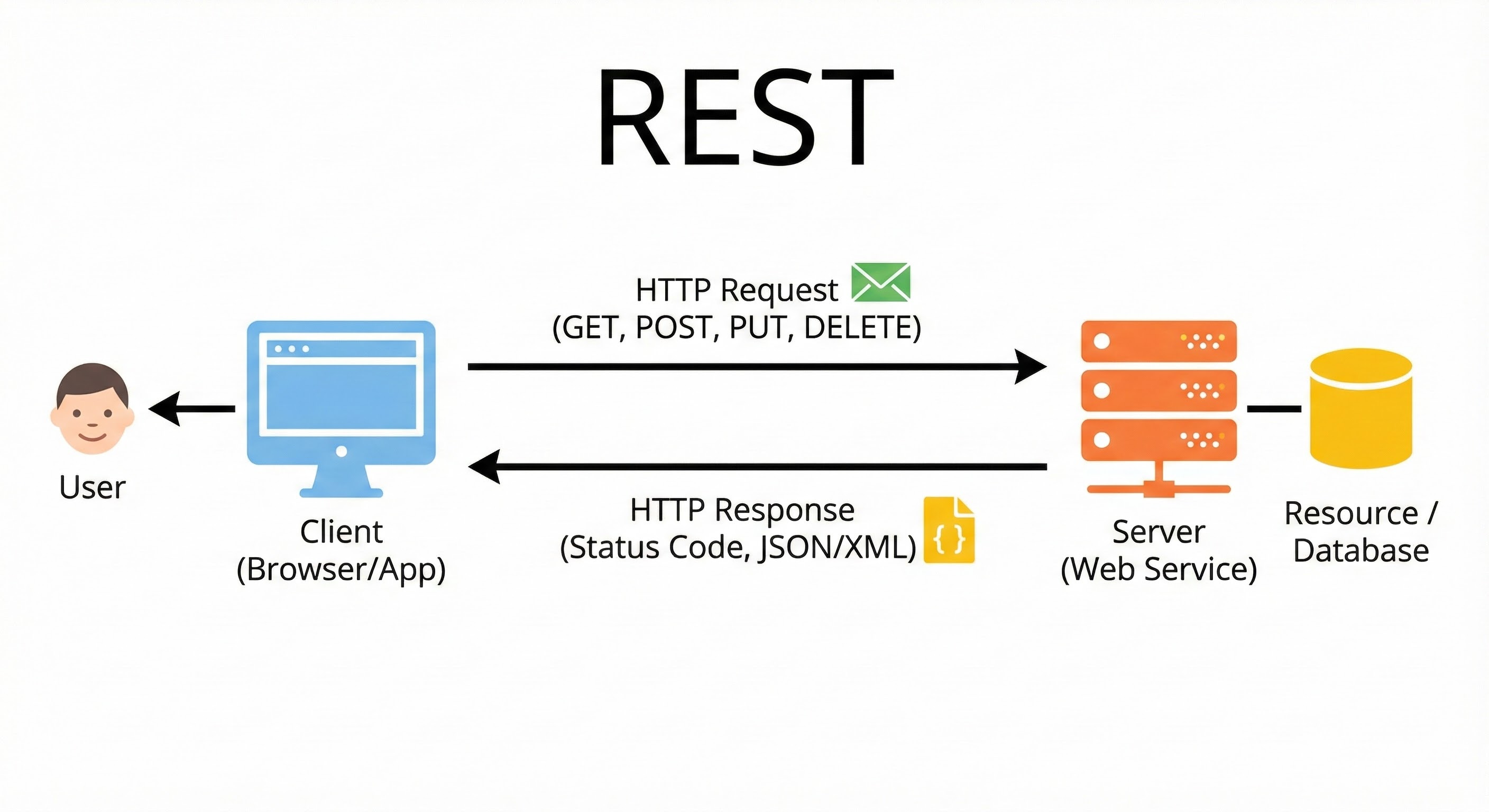
REST is the default choice for most public-facing APIs because of its simplicity and compatibility.
2. gRPC (Google Remote Procedure Call): For internal communication between high-performance services, REST can be inefficient. Sending text requires significant bandwidth and processing power to parse.
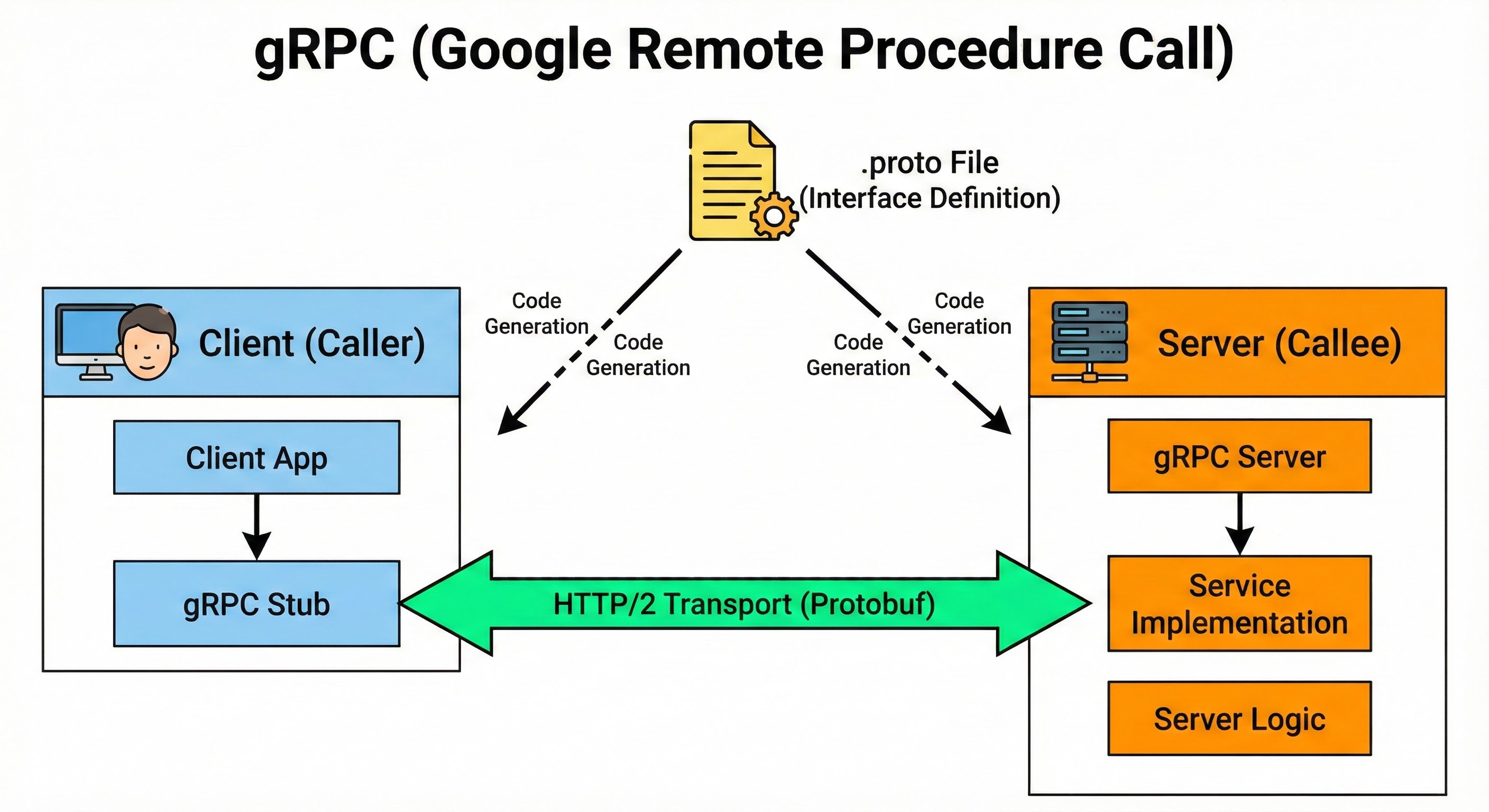
gRPC solves this by using a binary format called Protocol Buffers.
Binary Efficiency: Instead of sending the word “integer” or field names in text, it sends compact binary codes. This results in much smaller message sizes.
Strict Contracts: You must define the data structure in advance. Both the sender and receiver typically share a definition file. This ensures that the data always matches the expected format.
Performance: It is significantly faster than REST, making it ideal for systems that handle millions of internal requests per second.
When to Use Synchronous Patterns
You should use synchronous communication when the sender requires the answer immediately to proceed.
Consider a login scenario. When a user submits a password, the system must verify that password before loading the profile page.
The system cannot load the page “eventually.” It needs a definitive “Yes” or “No” right now. This requires a blocking, synchronous request.
Pattern 2: Asynchronous Communication
To solve the problems of blocking and coupling, we use asynchronous communication. In this pattern, the sender does not wait for a response.
Service A constructs a message and sends it.
Once the message is sent, Service A immediately continues with other work. It does not know when, or even if, Service B has processed the request.
This pattern usually requires an intermediary component known as a Message Broker. The broker acts as a temporary holding area for messages.
The Decoupled Nature
This approach provides Loose Coupling.
Because Service A does not wait, it is not affected by the performance of Service B. Service B could be offline, crashing, or running slowly.
Service A simply drops the message at the broker and moves on. The broker keeps the message safe until Service B is ready to pick it up.
This allows for better scalability.
If a sudden spike of 10,000 requests occurs, the broker absorbs them.
Service B can process them one by one at its own pace without being overwhelmed.
Two Asynchronous Models
There are two main ways to implement this.
1. Message Queues (Point-to-Point) In a queue model, a message is meant for a single consumer.
Imagine a list of tasks. Service A adds a task to the bottom of the list. Service B takes a task from the top.
Once Service B takes a task, it is removed from the list.
Even if you have multiple instances of Service B running to share the workload, a specific message is processed only once by one instance.
