
How Message Brokers Actually Work (Kafka vs RabbitMQ Internals Explained)
Learn how message brokers like Kafka and RabbitMQ scale using consumer groups. Covers offsets vs acknowledgments, partition rebalancing, at-most-once vs at-least-once vs exactly-once delivery

Software systems frequently struggle to process massive, sudden surges of incoming data. When a high-speed upstream application sends thousands of concurrent requests directly to a slower downstream service, the receiving server rapidly exhausts its available memory.
This severe resource depletion inevitably causes the receiving application to crash completely. Resolving this critical communication bottleneck is a fundamental requirement for building stable backend architectures.
To prevent these catastrophic cascading failures, engineering teams decouple their architecture using asynchronous communication layers.
This technical strategy requires a highly resilient middleware server to sit securely between the sending and receiving applications.
This intermediary system absorbs the heavy network traffic and stores the data safely until the downstream service is ready to process it.
Understanding exactly how this middleware manages data flow internally is a critical requirement for passing advanced system design interviews.
The Core Components of Distributed Messaging
To truly master system design, we must first clearly define the foundational components of a decoupled architecture. An application that continuously generates and sends data over the network is called a producer.
An application that connects to the network to receive and process this data is called a consumer.
A message broker is the dedicated intermediary server that sits strictly between them.
The message broker acts as a highly reliable, temporary holding area for data in transit.
If a producer generates data much faster than a consumer can calculate the results, the broker simply stores the excess data payloads safely on its hard drive or in its active memory. The consumer application then retrieves and processes the data strictly at its own required speed.
This buffering mechanism completely prevents the consumer from becoming overwhelmed and crashing.
While a basic message broker successfully prevents the consumer from crashing, it naturally introduces a brand new architectural problem.
A single consumer application can only process a strictly finite amount of data per second.
If the incoming data volume remains permanently higher than the maximum processing speed of that single consumer, the unprocessed data will pile up indefinitely. The message broker will eventually run out of storage space entirely, causing a system wide outage.
Scaling Workloads With Consumer Groups
To solve this persistent backlog of unprocessed data, we must drastically increase the total processing power of the system. We achieve this by launching multiple identical copies of the consumer application simultaneously.
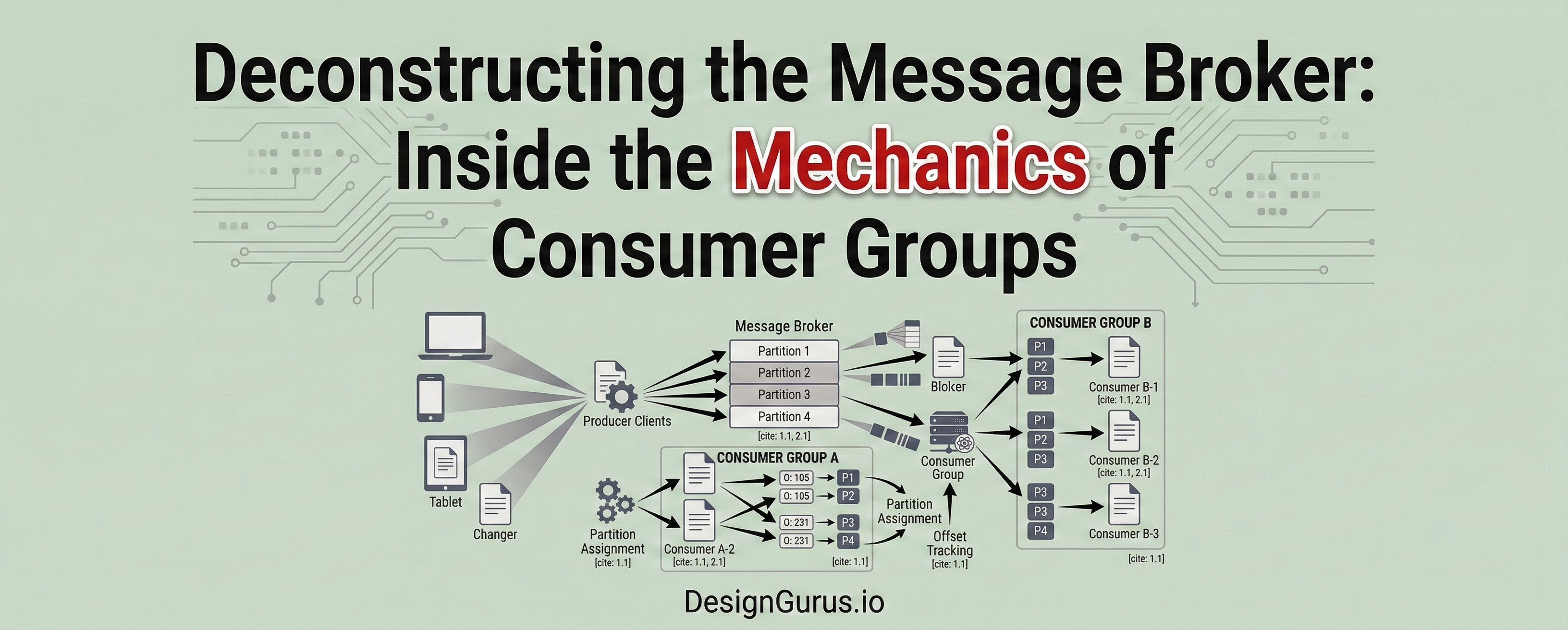
These independent application instances work together over the network to process the massive data backlog in parallel. This specific architectural scaling pattern relies entirely on a core concept known as a consumer group.
A consumer group is a logical configuration that securely links multiple independent consumer applications into a single unified processing entity.
When these individual application instances connect to the message broker, they explicitly declare the exact same group identifier string.
The message broker recognizes this specific identifier and treats all the distinct connected instances as a unified processing team. The broker then assumes the complex responsibility of dividing the incoming data evenly among these available instances.
We can easily see why this division of labor must be incredibly precise and strictly controlled.
If the broker accidentally sends the exact same data payload to three different consumer instances, the system duplicates its effort.
This duplication wastes valuable processing power and actively corrupts downstream database records. The broker must absolutely guarantee that every single data payload goes to exactly one consumer instance within the specific group.
The software engineering industry heavily relies on two dominant message brokers to handle this complex coordination. These robust systems are Apache Kafka and RabbitMQ.
While they both achieve the same ultimate goal of decoupling applications, their internal mechanics are fundamentally different.
Let us explore how these differing internal architectures actually work behind the scenes.
Tracking Progress: Offsets and Acknowledgments
When multiple consumer applications read data simultaneously, the broker must securely track exactly what data has been successfully processed.
If a consumer instance crashes suddenly due to a hardware failure, the broker needs to know exactly where the replacement instance should resume. Tracking this progress efficiently across a distributed network is a major engineering challenge.
Kafka and the Append Only Log
Apache Kafka avoids using temporary data structures entirely. Instead, it relies on a highly permanent storage structure called a log.
A log is simply a sequential data file saved directly on the physical hard drive of the broker server. New incoming data payloads are strictly appended to the very end of this persistent file.
Because a single log file cannot scale indefinitely, Kafka splits the data into multiple independent segments called partitions.
Partitions act as the fundamental scaling mechanism within a modern Kafka architecture. When a consumer group connects, Kafka assigns specific partitions to specific consumer instances.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.