
System Design Interview: Designing a Near-Cache with Redis and Pub/Sub
Why choose between local and distributed caching? Learn how to implement a two-layer caching strategy for your system.

The blog post follows below:
Comparing memory versus network speed
Reducing latency with near-caches
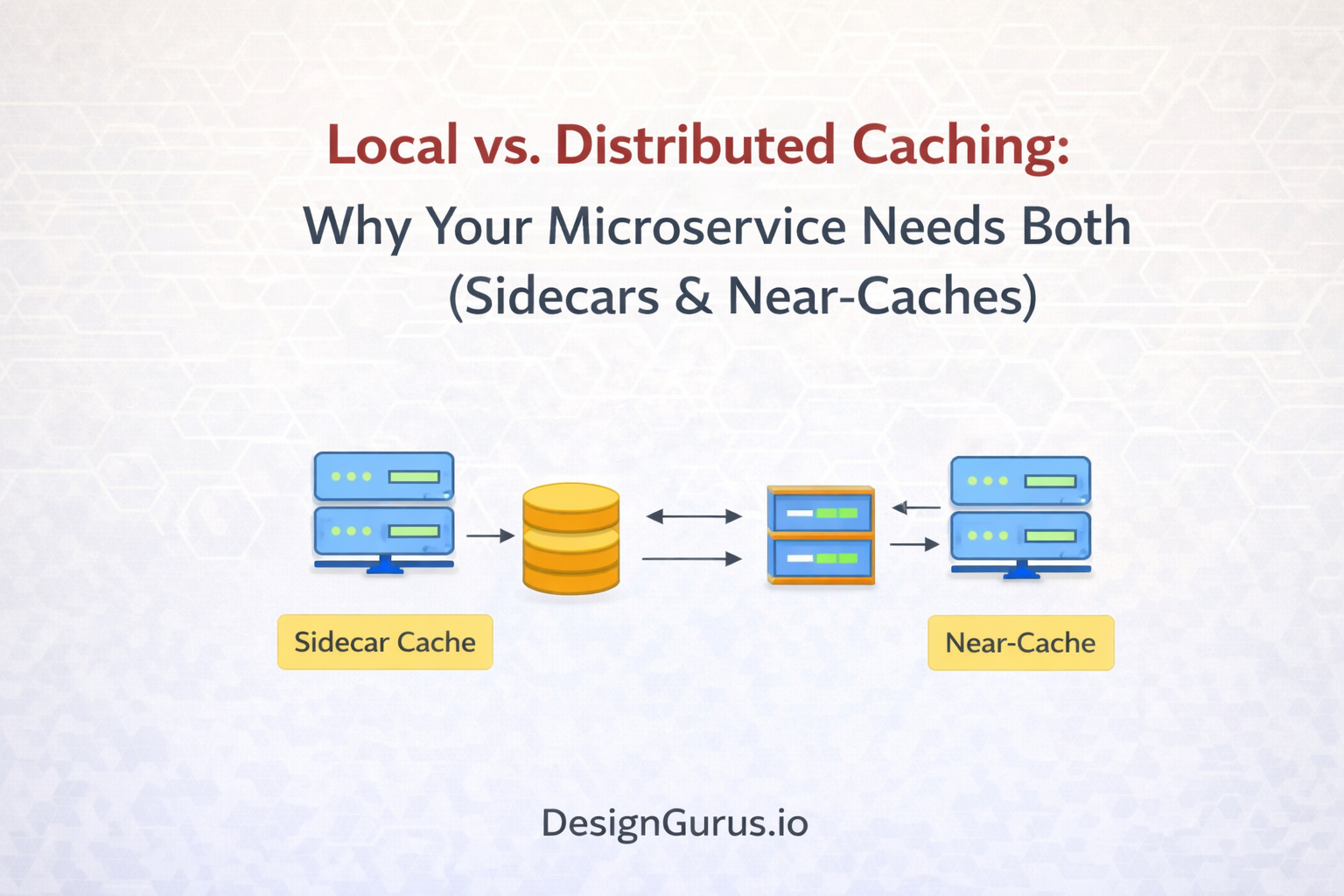
Scaling using sidecar patterns
Handling data consistency challenges
Performance is the defining characteristic of successful software architecture.
When a user interacts with an application, they expect an immediate response. They do not care about the complexity of the code, the elegance of the microservices, or the size of the database. They only care about speed.
As systems scale to handle millions of requests, the primary bottleneck inevitably becomes data retrieval. Reading data from a disk-based database is slow. Reading data from memory is fast.
This fundamental difference drives the need for caching.
However, simply adding a cache is not a complete solution. You must decide where that cache lives. Placing it incorrectly can lead to a system that is fast but displays incorrect information, or a system that is accurate but fails under heavy load. The choice between local caching and distributed caching is one of the most critical decisions in system design.
The Physics of Latency
To understand why caching strategies matter, you must first understand the cost of moving data.
In a standard microservice architecture, your application logic runs on a server. Your data lives in a database on a different server. When the application needs to process a request, it must fetch data from the database. This retrieval process involves a network call.
Data must travel from the database server, through switches and routers, to the application server. While fiber optics are fast, they are not instant. This travel time is called latency.
When an application makes one database call, the latency is negligible. When it makes thousands of calls per second, that latency accumulates. It consumes network bandwidth and CPU cycles.
The database itself also has a limit. It can only handle a certain number of concurrent connections before it queues requests. This queuing causes the application to slow down further.
Caching solves this by moving frequently accessed data to a storage location that is faster to access. The physical location of that cache determines the speed and reliability of the entire system.
Understanding Local Caching
Local caching is the practice of storing data within the same process as the application code. This is often referred to as In-Memory Caching.
In technical terms, the data sits in the heap memory of the application. If you are coding in Java, this is an object in the JVM heap. In Python, it is a dictionary in memory.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.