
LLM Inference at Scale: Batching, Caching, Routing, and Cost Control
How Production LLM Systems Achieve High Throughput and Low Cost Through Batching, Caching, Routing, and Careful Resource Control


What This Blog Will Cover
Why LLM inference is expensive
How batching boosts throughput
Caching that avoids recomputation
Routing requests to the right model
Controlling cost at scale
Calling a large language model once is easy.
A single request to a model returns a response in seconds, and building a prototype around it takes very little effort. This ease has led to an explosion of AI features, and by 2026 large language models sit behind a large share of new products.
Serving those models to millions of users is a different problem entirely.
LLM inference, the process of running a trained model to generate output, is unusually expensive and slow compared to ordinary computation. It runs on costly hardware, it consumes enormous amounts of memory, and it generates output one piece at a time rather than all at once.
A naive deployment that works for a demo becomes financially ruinous and painfully slow the moment real traffic arrives.
This is why serving large language models efficiently has become its own engineering discipline.
The difference between a well-designed inference system and a naive one is not small. It can be the difference between a feature that is profitable and one that loses money on every request, or between a response that feels instant and one that frustrates every user.
Four levers control this efficiency.
Batching raises how many requests the hardware can serve at once.
Caching avoids repeating expensive work.
Routing sends each request to the right model and the right machine. And cost control ties these together to keep spending sustainable at scale. Mastering these four is what separates a serving system that survives production from one that collapses under it.
This article explains each of the four in depth, along with the inference fundamentals they build on. It is written for engineers building real AI systems in 2026 and for candidates who want to discuss modern AI infrastructure with genuine understanding rather than buzzwords.
Why LLM Inference Is So Expensive
Before the four levers, it is worth understanding why serving a large language model is so much harder than serving an ordinary web request.
The difficulty comes from a few properties unique to how these models run.
A large language model generates text in two distinct phases, and the distinction matters for everything that follows.
The first is the prefill phase, where the model processes the entire input prompt at once to understand it. This phase is fast per token because all the input tokens are processed together, and it is limited mainly by raw computation.
The second is the decode phase, where the model generates the output one token at a time, with each new token depending on all the tokens before it. This phase is slow because the tokens are produced sequentially, and it is limited mainly by how fast the hardware can move data in and out of memory.
The decode phase is where most of the time goes for typical responses, and its sequential nature is the root of the latency problem.
A response of several hundred tokens requires several hundred sequential steps, and no amount of raw compute can make those steps happen in parallel for a single request.
The second major property is the KV cache, short for key-value cache.
To generate each new token, the model needs information about all the previous tokens.
Rather than recomputing that information every step, the model stores it in the KV cache and reuses it. This is essential for speed, but the cache grows with the length of the sequence and consumes a large amount of GPU memory.
In practice, the KV cache is often the primary thing that limits how many requests a machine can serve at once, because memory runs out before compute does.
The third property is simply that the hardware is expensive and scarce.
Large models run on specialized accelerators that cost a great deal and are in high demand. Every inefficiency translates directly into needing more of this costly hardware, which is why efficiency is not a nicety but a core economic concern.
These three properties, sequential generation, memory-hungry caching, and expensive hardware, are exactly what the four levers address. Each one attacks the cost and latency problem from a different angle.
Pillar 1: Batching, Serving Many Requests at Once
The first lever is batching, which is the single most important technique for raising the throughput of an inference system.
Batching means processing multiple requests together in a single pass through the model rather than one at a time.
The reason batching helps so much comes from how the hardware works.
The accelerators that run large models are built for massive parallelism, and processing a single request leaves most of that capacity idle.
By grouping many requests together and processing them in one pass, the system uses the hardware far more fully, serving many requests for nearly the cost of one. Without batching, an expensive accelerator sits mostly unused, which is enormously wasteful.
The simplest form is static batching, where the system collects a fixed group of requests, processes them together, and waits for all of them to finish before starting the next group. This is better than no batching, but it has a serious flaw for language models. Because different requests generate responses of very different lengths, the whole batch is held up by its longest member.
A batch of ten requests where nine finish quickly and one is long forces the nine finished slots to sit idle until the long one completes, wasting capacity.
The technique that solves this is continuous batching, also called in-flight batching, and it is the standard for modern inference systems.
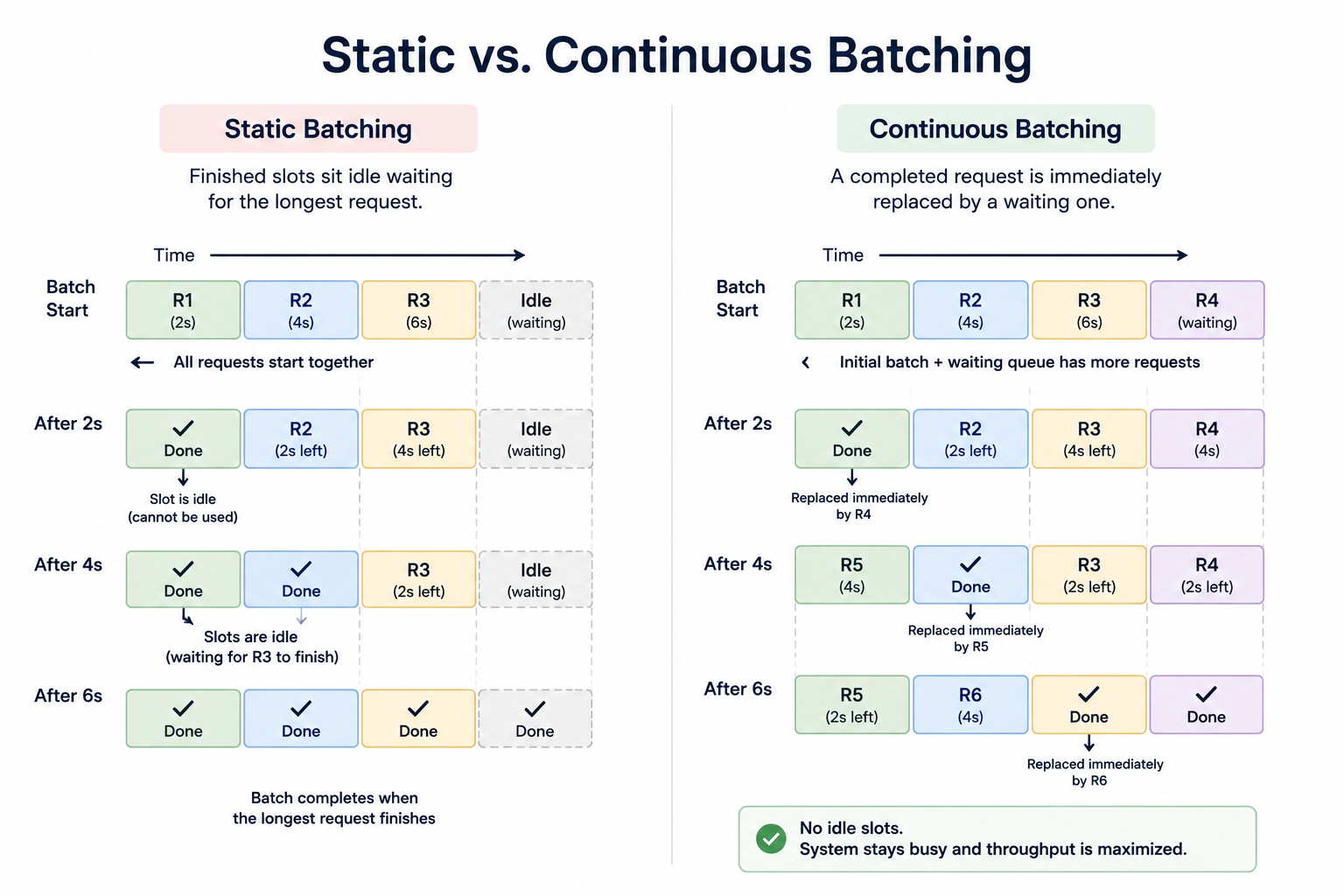
Instead of waiting for an entire batch to finish, the system works at the level of individual generation steps.
As soon as one request in the batch completes, it leaves, and a new waiting request takes its place immediately.
The batch is continuously refilled rather than processed in fixed groups. This keeps the hardware fully occupied, since finished requests are replaced the instant they complete, and it dramatically increases the number of requests a machine can serve.