
How to Design a Distributed Lock Service (Chubby/ZooKeeper)
Learn how to design a distributed lock service with a step-by-step breakdown. Includes back-of-the-envelope estimation, high-level architecture, core flows, scaling strategies, and bottlenecks.

Here is a detailed, step-by-step design for a Distributed Lock Manager (DLM) similar to Google’s Chubby.
1. Problem Definition and Scope
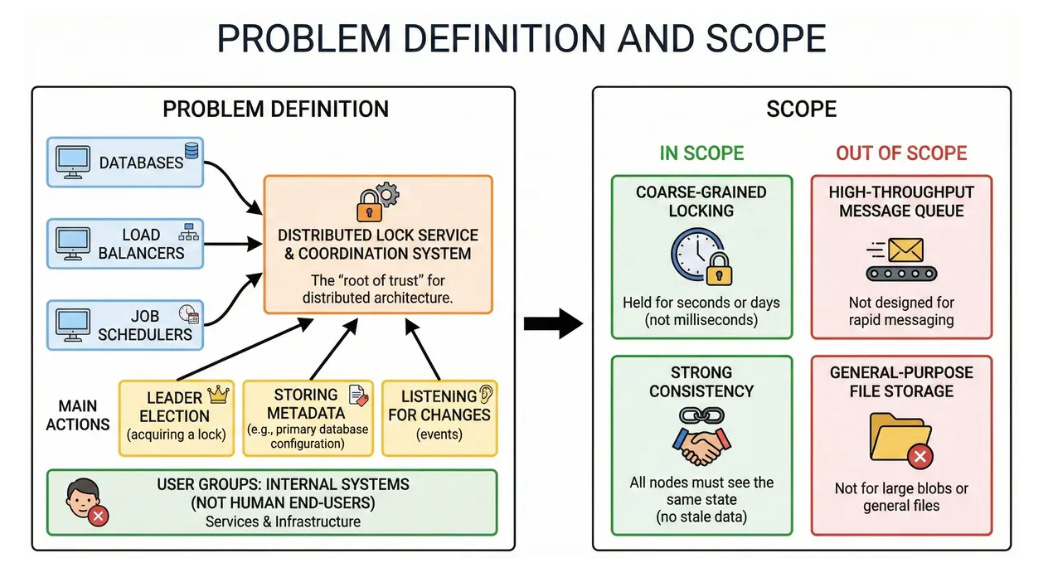
We are designing a distributed lock service and coordination system. It serves as the “root of trust” for a distributed architecture, allowing thousands of other systems (like databases, load balancers, and job schedulers) to elect leaders and store small, critical configuration files.
User Groups: Internal software services and infrastructure systems (not human end-users).
Main Actions: Leader election (acquiring a lock), storing metadata (e.g., “who is the primary database?”), and listening for changes (events).
Scope:
We will focus on coarse-grained locking. Locks are held for seconds or days, not milliseconds.
We will focus on Strong Consistency. All nodes must see the same state; stale data is not acceptable for locking.
We will not design a high-throughput message queue or a general-purpose file storage system for large blobs.
2. Clarify functional requirements
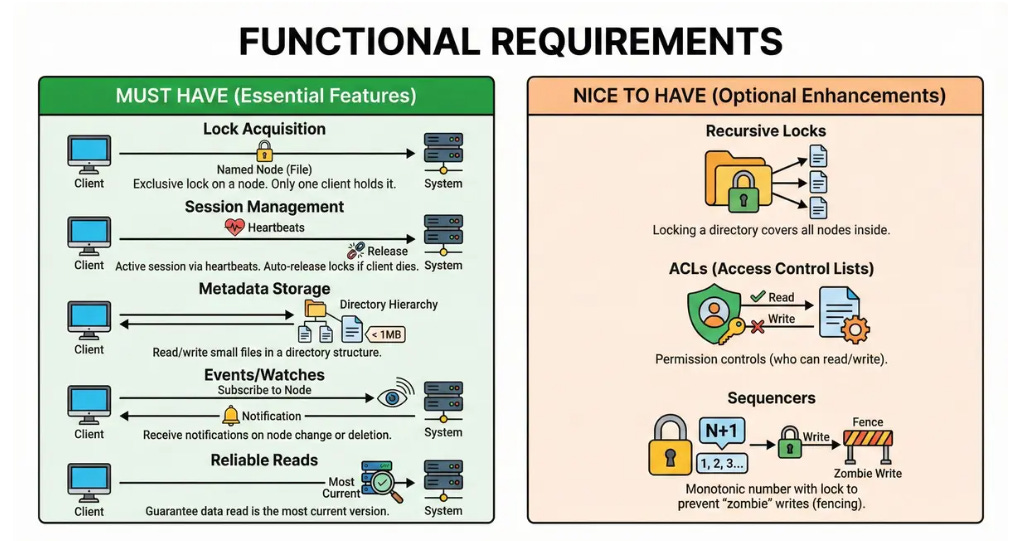
Must Have
Lock Acquisition: Clients can acquire an exclusive lock on a named node (file).
Session Management: The system must maintain an active session for each client via heartbeats. If a client dies, its locks are automatically released.
Metadata Storage: Clients can read and write small files (under 1MB) organized in a directory hierarchy.
Events/Watches: Clients can subscribe to a node and receive notifications when it changes or is deleted.
Reliable Reads: Clients can read data with a guarantee that it is the most current version.
Nice to Have
Recursive Locks: Locking a directory covers all nodes inside it.
ACLs: Permission controls (who can read/write).
Sequencers: A monotonic number returned with the lock to prevent “zombie” writes (fencing).
3. Clarify non-functional requirements
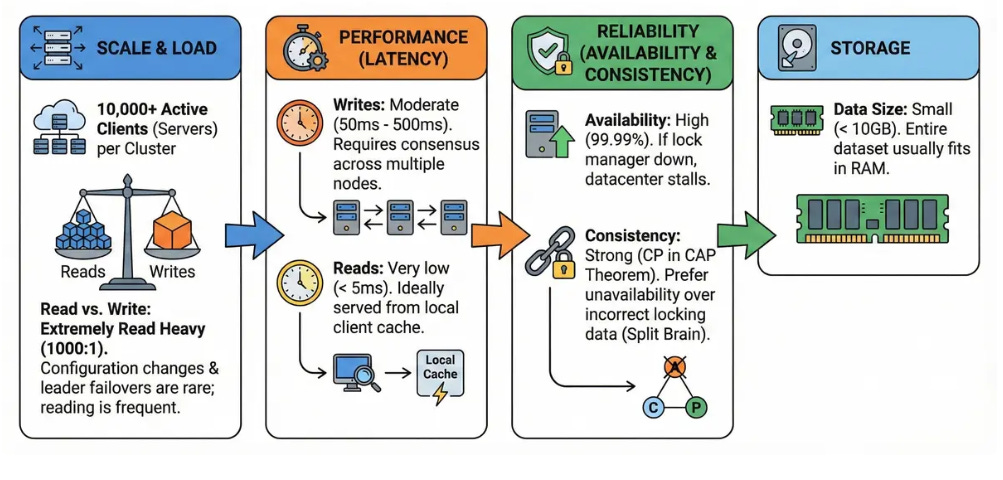
Target Users: 10,000+ active clients (servers) per cluster.
Read vs. Write: Extremely Read Heavy (1000:1). Configuration changes and leader failovers are rare; reading the config is frequent.
Latency:
Writes: Moderate (50ms - 500ms) as they require consensus across multiple nodes.
Reads: Very low (< 5ms), ideally served from local client cache.
Availability: High (99.99%). If the lock manager is down, the entire datacenter usually stalls.
Consistency: Strong (CP in CAP theorem). We prefer the system to be unavailable rather than returning incorrect locking data (Split Brain).
Data Size: Small. The entire dataset usually fits in RAM (e.g., < 10GB).
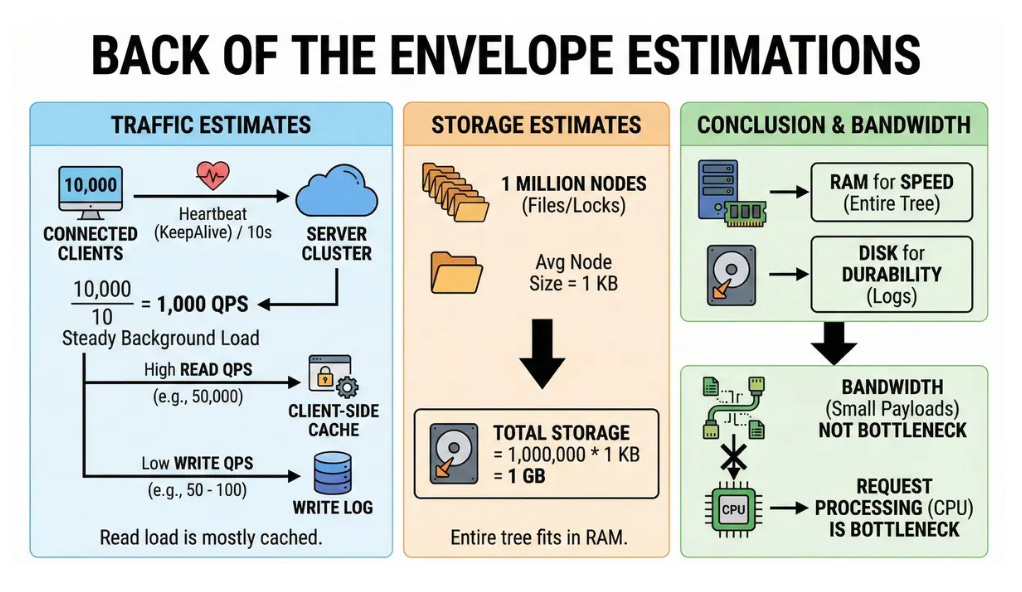
4. Back of the envelope estimates
Traffic Estimates:
Assume 10,000 connected clients.
Each client sends a heartbeat (KeepAlive) every 10 seconds.
Heartbeat QPS = 10,000 / 10 = 1,000 QPS. This is a steady background load.
Read QPS: High (e.g., 50,000 QPS), but mostly served by client-side cache.
Write QPS: Low (e.g., 50 - 100 QPS).
Storage Estimates:
Assume 1 million nodes (files/locks).
Average node size = 1 KB.
Total Storage = 1,000,000 * 1 KB = 1 GB.
Conclusion: We can keep the entire tree in RAM for speed, using disk only for durability (logs).
Bandwidth:
Payloads are small text/binary. Bandwidth is not a bottleneck; request processing (CPU) is.
5. API design
We will use a gRPC-style API (or internal RPC) rather than REST, as it fits the session-oriented nature better.
1. CreateSession
Method: POST /session/create
Response: session_id, keep_alive_interval (e.g., 10s).
2. KeepAlive
Method: POST /session/renew
Params: session_id
Response: status (OK/EXPIRED).
3. AcquireLock (Create Ephemeral Node)
Method: POST /node/create
Params: path (e.g., “/db/leader”), content, mode (EPHEMERAL)
Response: status (SUCCESS/ALREADY_EXISTS), sequencer (version).
4. GetNode
Method: GET /node
Params: path, watch (boolean)
Response: content, stat, lock_holder.
Behavior: If watch=true, the connection registers a callback. The server will notify the client later if the node changes.
5. SetContent
Method: PUT /node
Params: path, content, expected_version (for optimistic locking).
Response: new_version.
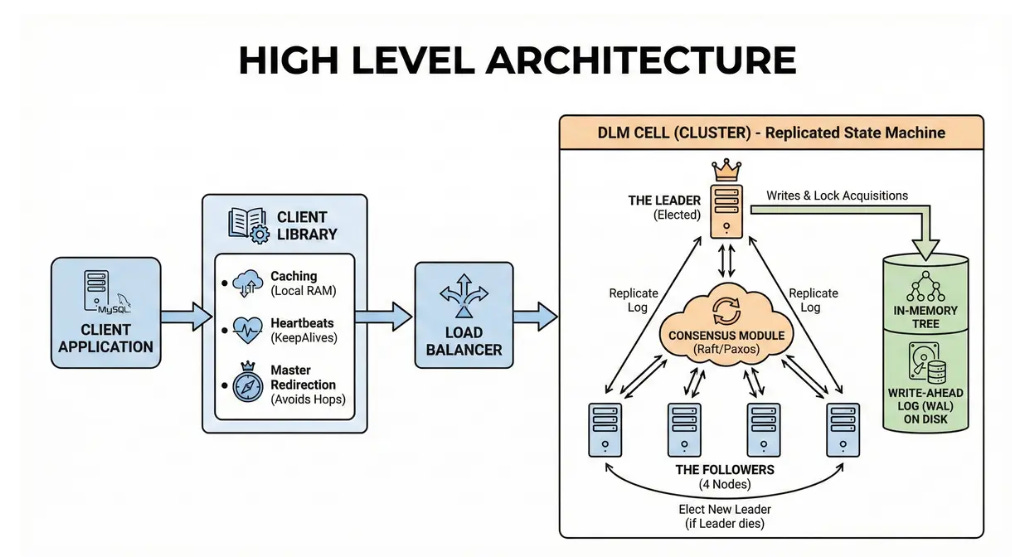
6. High level architecture
Our architecture follows a “Replicated State Machine” model using a consensus protocol like Raft or Paxos.
Client App -> Client Library -> Load Balancer -> DLM Cell (Cluster)
Client Application: The service using the lock (e.g., a MySQL server).
Client Library: A “smart” library linked into the application. It handles:
Caching: Stores file content in local RAM.
Heartbeats: Automatically sends KeepAlives for the session.
Master Redirection: Remembers who the Leader is to avoid unnecessary hops.
DLM Cell (The Cluster): A group of 5 servers.
The Leader: One node is elected Leader. All writes and lock acquisitions go here.
The Followers (4 nodes): They replicate the Leader’s log. If the Leader dies, they elect a new one.
Consensus Module: The logic (Raft/Paxos) ensuring all 5 nodes agree on the order of operations.
Storage: In-memory tree structure backed by a Write-Ahead Log (WAL) on disk.
7. Data model
We use a hierarchical tree structure similar to a UNIX filesystem.
Storage Engine: In-Memory Tree
The entire database lives in RAM.
Root /
ls (Lock Service)
global
master_db (Node)
Content: “10.0.0.5”
Type: Ephemeral (Lock)
ACL: [Read:All, Write:DB_Admins]
Watchers: [Client_A, Client_B]
Why In-Memory?
Since the data is small (1GB), RAM is cheap and provides the fastest access.
We do not need complex SQL joins. We just need path lookups (/ls/global/master_db).
Durability:
WAL (Write Ahead Log): Every change (create, delete, write) is appended to a file on disk before updating the RAM.
Snapshot: Every few hours, the RAM state is saved to a file so we can truncate the log.
8. Core flows end to end
These flows describe exactly how the Distributed Lock Manager (DLM) handles its three most critical jobs: deciding who is in charge (locking), guaranteeing data accuracy (consistency), and cleaning up failures (session management).
This design prioritizes Strong Consistency (CP). The system would rather be slow or unavailable than lie to a client about who holds a lock.
Flow 1: Leader Election (Acquiring a Lock)
This flow explains how distributed processes coordinate to ensure only one leader exists at a time. It relies on the concept of Ephemeral Nodes (files that disappear when the creator disconnects).
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.