
Beyond Relational: Understanding Vector Databases and NewSQL Architectures
Confused by database options? Master the differences between Relational, NoSQL, Key-Value, Graph, and Vector databases. Learn when to use PostgreSQL, MongoDB, Redis, or Pinecone for scalable systems.


Software systems generate massive amounts of information every second. This data drives decision-making, user personalization, and core application logic.
However, applications typically run in random-access memory (RAM), which is volatile.
When a process stops, crashes, or a server restarts, that in-memory state vanishes instantly.
To make systems useful and reliable, engineers must ensure data survives beyond the life of a single process. This requirement created the field of data persistence.
The challenge lies in the variety of data structures.
Some data fits perfectly into strict grids, while other data is messy, hierarchical, or heavily interconnected.
A single method of storage cannot optimize for every scenario.
This has led to the development of specialized Database Management Systems (DBMS).
Understanding these types allows a developer to select the right tool for optimizing speed, consistency, and scalability in 2026.
Key Takeaways
Relational databases prioritize structure and data integrity through strict schemas and ACID compliance.
NoSQL databases offer flexibility and horizontal scalability by trading off immediate consistency for high availability.
Vector databases have become standard in 2026 for handling high-dimensional data used in AI and similarity searches.
Graph databases optimize for traversing relationships between data points rather than just storing the points themselves.
Choosing a database requires analyzing the read/write patterns and the structural complexity of your specific workload.
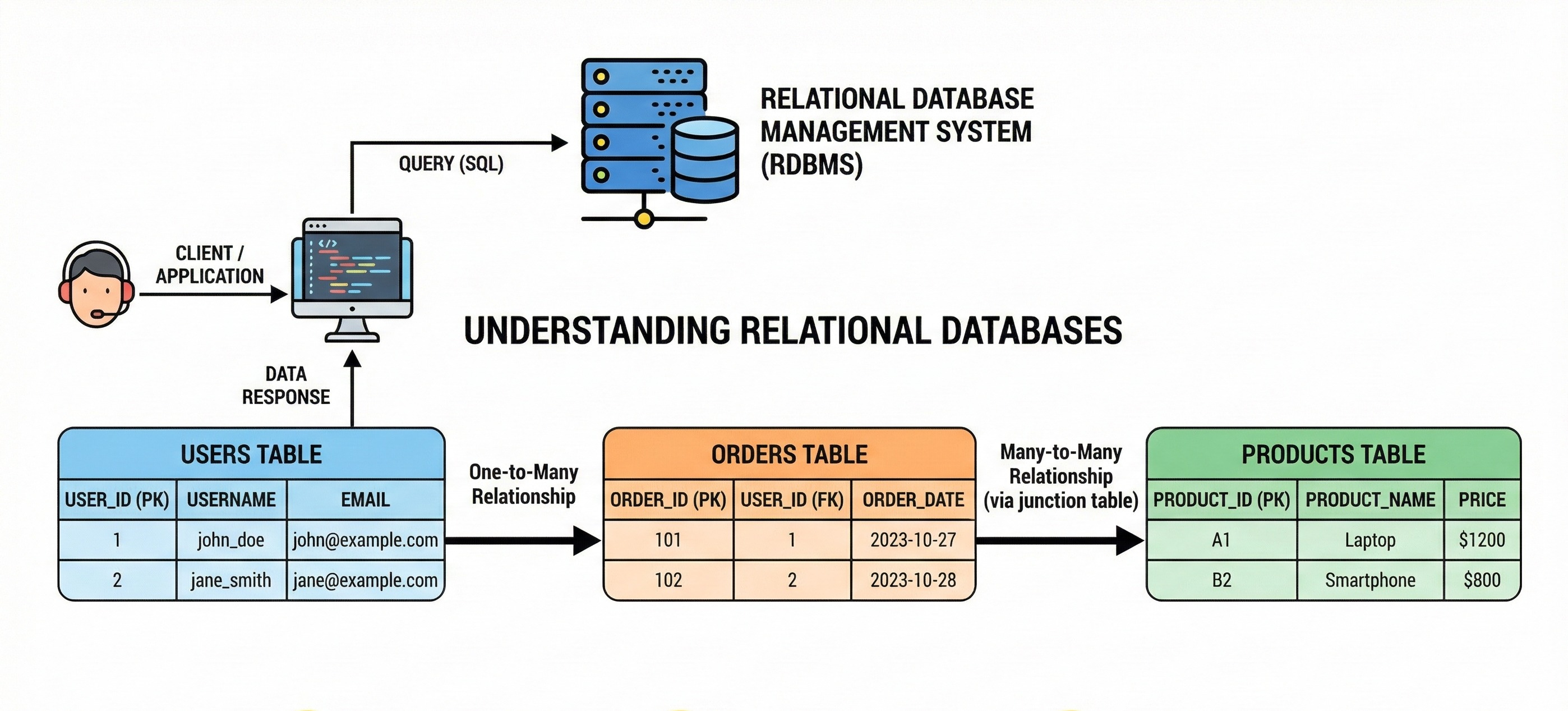
The Foundation: Relational Databases (RDBMS)
Relational databases have served as the backbone of software engineering for decades. When developers discuss “traditional” databases, they are usually referring to this model. They organize data into tables, which consist of rows and columns.
A row represents a single record, and a column represents a specific attribute of that record.
The defining feature of this type is the schema.
A schema is a strict blueprint. It defines exactly what data types go into which columns.
You cannot insert text into a column designed for integers.
This rigidity ensures data quality.
If data enters the system, you can be certain it matches the expected format.
The Power of SQL and Normalization
These systems use Structured Query Language (SQL) to interact with data. SQL allows developers to define relationships between different tables using unique identifiers called keys.
A “Foreign Key” in one table points to a “Primary Key” in another.
To reduce redundancy, developers practice normalization. This involves breaking data down into the smallest logical tables to avoid duplication.
While this saves space and ensures consistency, it requires the database to perform “joins” during queries.
A join combines rows from two or more tables based on a related column.
ACID Compliance
The most critical technical aspect of RDBMS is ACID compliance. This set of properties guarantees valid database transactions.
Atomicity: This ensures that a transaction is treated as a single unit. Either every step in the process succeeds, or the entire transaction fails. There is no partial state.
Consistency: The database must move from one valid state to another valid state. It must adhere to all defined rules and constraints.
Isolation: Multiple transactions occur concurrently without interfering with each other. The intermediate state of a transaction is invisible to other transactions.
Durability: Once a transaction is committed, it remains saved even in the event of a system failure.
In 2026, relational databases remain the default choice for systems where data accuracy is non-negotiable, such as financial ledgers or inventory management. PostgreSQL and MySQL remain the industry standards.
NoSQL Databases
As applications grew larger, the rigid nature of relational databases introduced bottlenecks.
Scaling a relational database usually requires vertical scaling.
This means adding more power (CPU, RAM) to a single machine.
Eventually, a single machine reaches its physical limits.
NoSQL (Not Only SQL) databases emerged to solve this. They are designed for horizontal scaling. This involves adding more distinct machines to a cluster rather than upgrading a single machine.
NoSQL databases generally offer flexible schemas and faster write speeds. They often relax the strict consistency rules of ACID in favor of “eventual consistency.”
This means that while data is replicated across nodes, there might be a brief moment where different users see different versions of the data.
There are four main categories of NoSQL databases you should know.
1. Document Databases
Document databases store data in formats that resemble the objects developers use in code, such as JSON or BSON.
A record is a single document.
Unlike the relational model, these documents do not require a uniform structure. One document can have five fields, while another in the same collection has ten. This flexibility allows developers to iterate quickly without altering a global schema.
These systems excel at handling hierarchical data.
In a relational database, you might need to join three tables to reconstruct a complex user profile.
In a document store, that entire structure exists within a single document. This improves read performance for individual records.
MongoDB is the prominent player here.
2. Key-Value Stores
This is the simplest form of database. It functions exactly like a dictionary or hash map in programming. Every data item consists of a key and a value.
To retrieve data, you must know the specific key. The database does not care what is inside the “value.” It treats the value as an opaque blob of data. Because the internal logic is so simple, these databases are incredibly fast. They offer low-latency reads and writes.
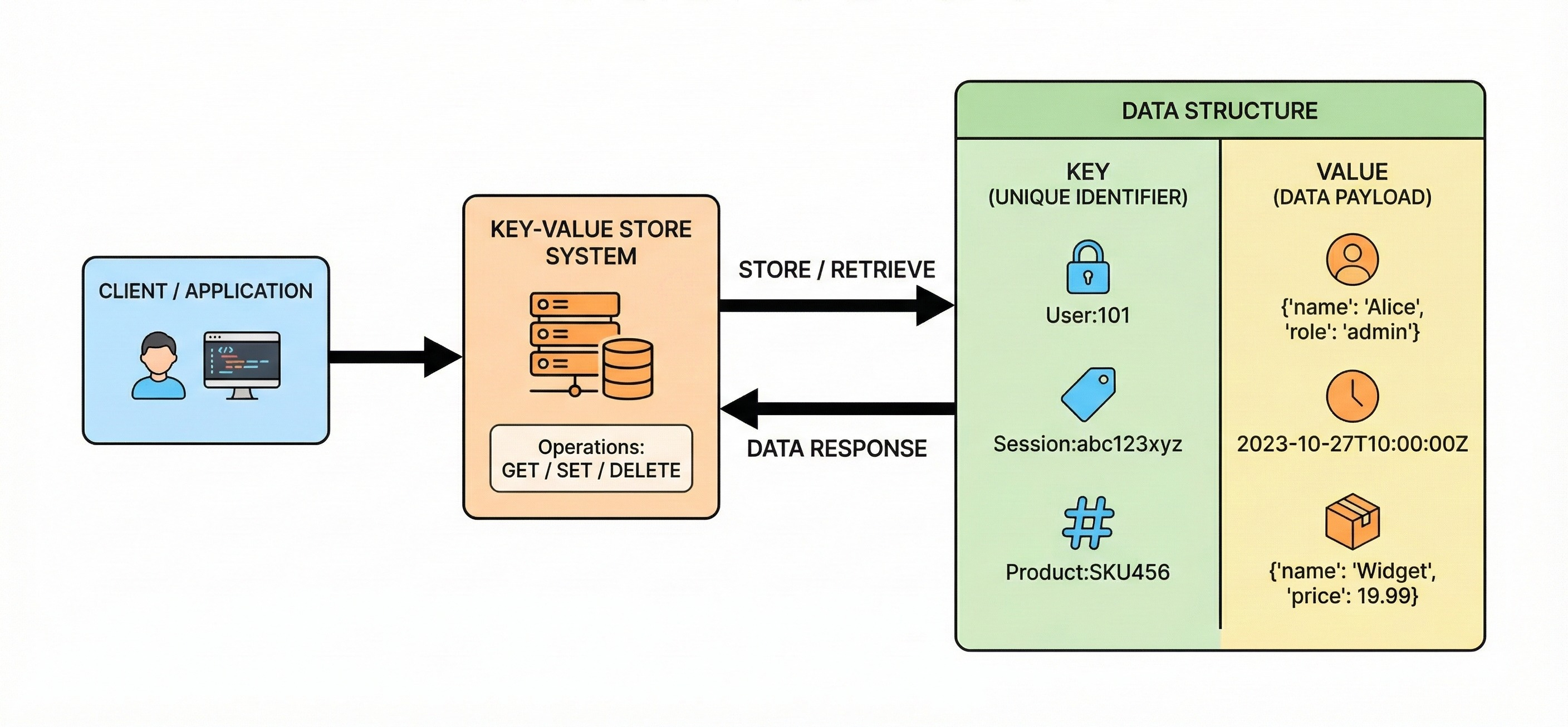
Engineers often use key-value stores for caching.
When a computation is expensive, the result is saved here for quick retrieval. They are also useful for managing session data where the lookup pattern is always based on a unique ID.
Redis is the standard example, often keeping data in memory for maximum speed.
3. Wide-Column Stores
Wide-column stores organize data into columns rather than rows.
In a traditional row-oriented database, all data for a single record is stored together on the disk. To analyze a single attribute across millions of users, the system must read every entire row.
Columnar stores group the data of a specific column together on the disk. This makes aggregation queries highly efficient.
If you need to calculate the average of a specific column, the database can read just that column block without scanning the irrelevant data in other columns.
These databases are optimized for write-heavy workloads and big data analytics. They can handle massive amounts of data spread across many servers.
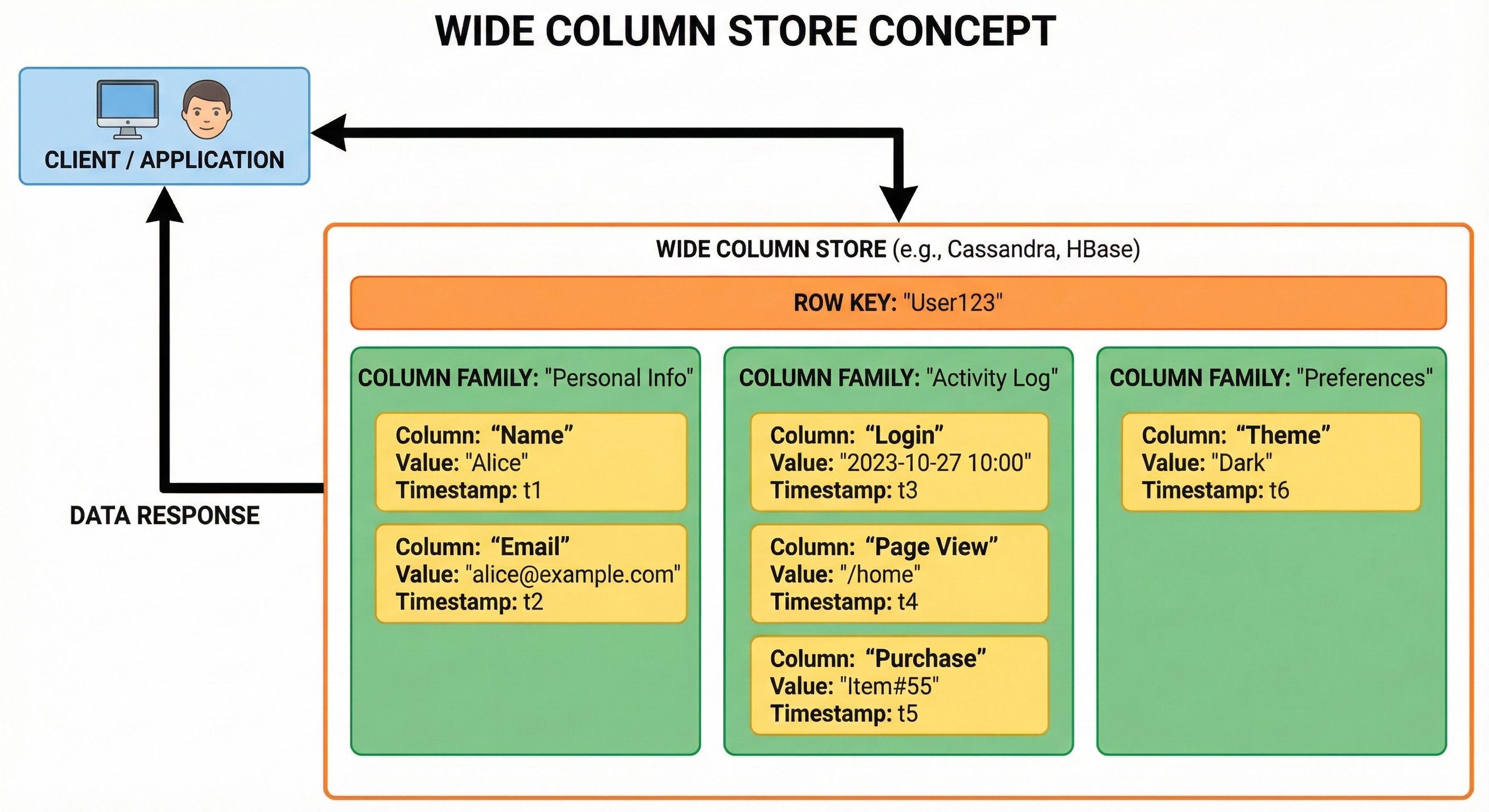
Apache Cassandra and ScyllaDB are frequently used in large-scale systems where high availability is more important than immediate consistency.
4. Graph Databases
Relational databases can handle relationships, but they do so by linking separate tables. As the number of connections grows, the complexity of joining these tables degrades performance.
Graph databases treat the relationship itself as a first-class citizen. They consist of nodes (entities) and edges (relationships). Both nodes and edges can hold properties.
The physical storage mechanism often uses “index-free adjacency.” This means every node contains a direct pointer to its adjacent nodes.
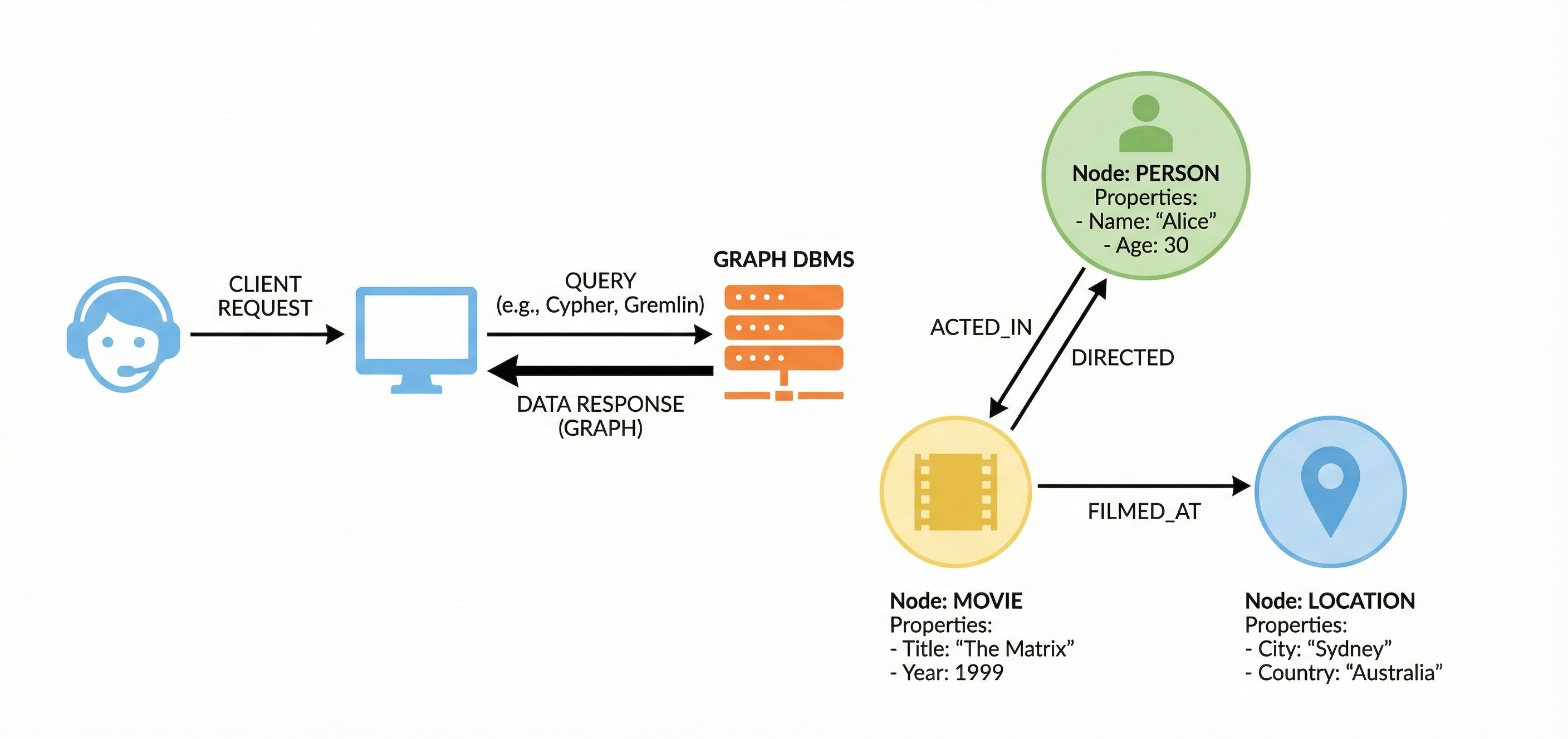
Traversing millions of connections becomes an instant memory lookup rather than a complex search operation. These are essential for systems that analyze networks, fraud detection patterns, or recommendation engines where the connections are just as important as the data itself.
Neo4j is a widely used example.
Vector Databases
By 2026, the rise of Artificial Intelligence and Large Language Models (LLMs) has made Vector Databases a standard component of system design.
Traditional databases search for exact matches. They look for a specific string of text or a number.
Vector databases are designed to store and search high-dimensional vectors.
A vector is a long list of numbers that represents the semantic meaning of data, such as an image or a block of text.
This numerical representation is called an embedding.
Similarity Search
The core function of a vector database is not exact matching, but “similarity search.” When a query enters the system, it is converted into a vector.
The database then calculates the mathematical distance between this query vector and the stored vectors.
Vectors that are close to each other in this multi-dimensional space are considered semantically similar. This allows systems to find relevant context even if the exact keywords do not match. This technology underpins the long-term memory of AI agents and advanced search functionality.
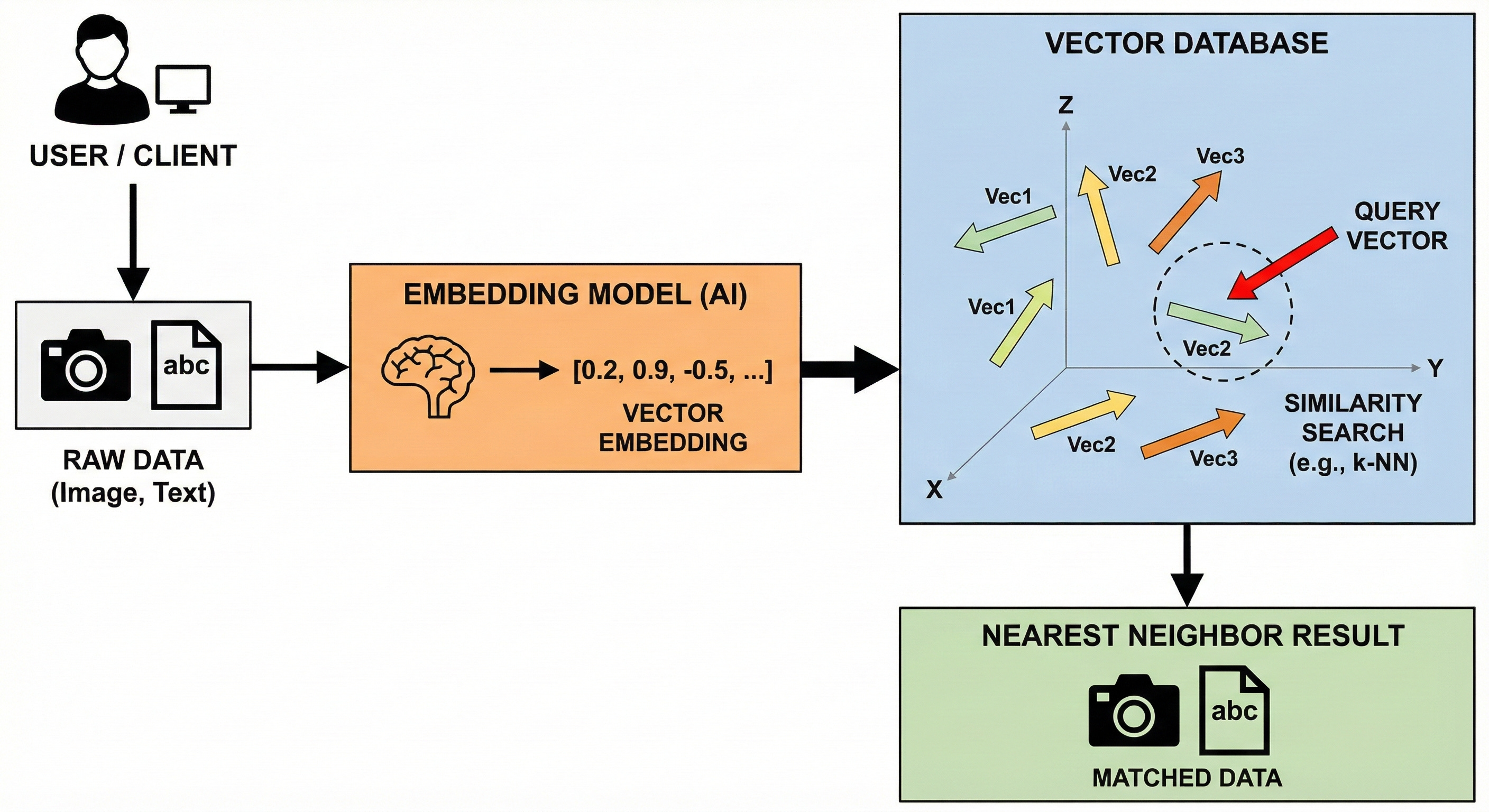
Pinecone and Milvus are top choices in 2026, while pgvector allows PostgreSQL to handle this workload as well.
NewSQL and Distributed SQL
A recurring challenge in system design is the trade-off between the strong guarantees of SQL and the scalability of NoSQL.
NewSQL databases attempt to provide the best of both worlds.
These systems maintain the relational data model and ACID guarantees. However, they use a distributed architecture under the hood. They automatically partition (shard) data across multiple servers.
The database engine handles the complexity of distributed consensus.
From the developer’s perspective, it looks like a standard single SQL database. Behind the scenes, it operates like a scalable NoSQL cluster.
This is increasingly popular in 2026 for core banking and inventory systems that need both massive scale and perfect accuracy.
CockroachDB and YugabyteDB are leaders in this space.
Time-Series Databases
Some data is strictly chronological.
Metrics from servers, readings from sensors, or financial tick data arrive in a constant stream.
Time-Series Databases (TSDB) are optimized to handle this specific pattern.
They prioritize fast ingestion of new data points. They are also optimized for querying ranges of time.
Unlike standard databases that might overwrite old values, a TSDB appends new values with a timestamp. This allows for efficient compression and analysis of trends over time.
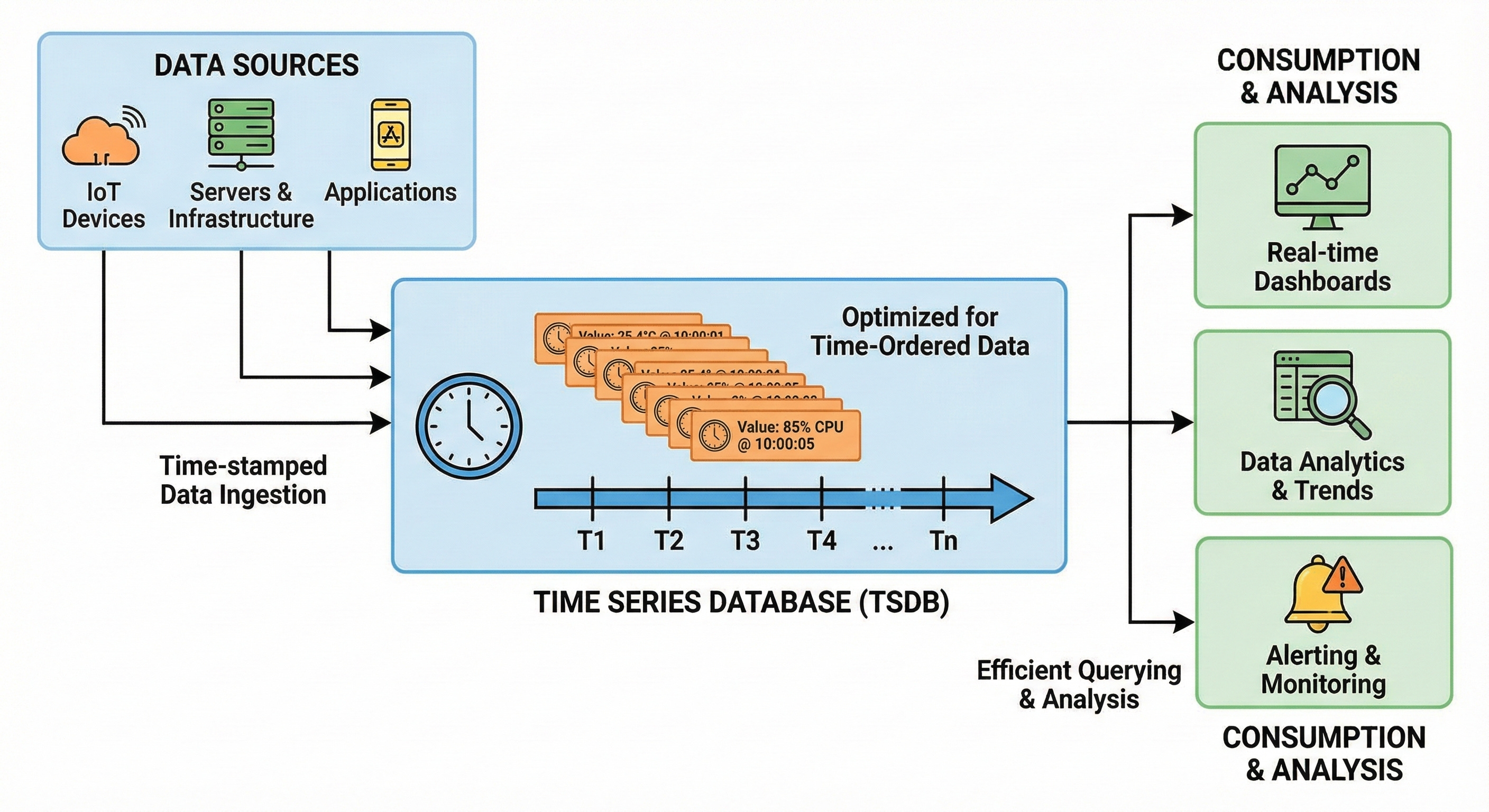
InfluxDB and TimescaleDB are designed for these high-velocity workloads.
Conclusion
The “best” database does not exist in isolation.
The choice depends entirely on the requirements of the system.
Structure: If the data has a strict schema and requires complex transactions, Relational databases remain superior.
Flexibility: For rapidly changing data shapes or massive content catalogs, Document stores provide the necessary agility.
Speed: Key-Value stores offer the lowest latency for simple lookups.
Connections: Graph databases excel when the value lies in the relationships between data points.
Intelligence: Vector databases are the engine for semantic search and AI memory in 2026.
Understanding these distinctions allows developers to build architectures that are robust, efficient, and capable of handling the demands of modern software.
A most common misconception about relational database is having "relationships". Actually relationships in statistics mean tables, in other words database in RDBMS is stored in tables as opposed to other formats
Good one Arslan.
Here’s a similar article I’ve written, with a very clear beautiful table cheat sheet which helps in choosing the right database in a system design interview
https://pradyumnachippigiri.substack.com/p/sql-vs-nosql-a-simple-checklist-to