
Essential Cache Strategies Every Junior Developer Must Know
Learn the fundamentals of caching strategies in system design. Explore read strategies, write patterns, and memory management for junior developers.


Every successful software application eventually experiences severe performance bottlenecks. When an application grows, the primary database receives thousands of simultaneous network requests. Processing these heavy queries takes significant time and consumes immense computing power.
If the primary database crashes under this continuous pressure, the entire software application stops working.
Fetching data directly from a primary database is always computationally expensive. Databases store information on physical disk drives to ensure data remains safe permanently. Reading data from these physical disks requires mechanical or heavy electronic processes.
Software engineers need a reliable way to serve data quickly without constantly overloading the main servers.
This fundamental challenge is where caching becomes absolutely essential for system scale.
Caching stores frequently requested information in a temporary memory layer.
This temporary storage layer significantly reduces database load and speeds up response times. Understanding how to implement this memory layer correctly is critical for building robust software architecture.
Complete Guide to Cache Strategies
To understand caching, we must first look at how computers store data.
Primary databases usually store their information on physical hard drives or solid state drives. Reading data from a physical disk takes a relatively long time in computing terms.
As web traffic grows, these small disk reading delays add up.
They eventually create massive performance issues for the entire system.
A cache is a high speed data storage layer designed to solve this exact problem.
Instead of using physical disks, caches operate entirely in Random Access Memory.
Random Access Memory is an incredibly fast hardware component. However, it is also volatile and highly expensive to purchase.
Because it is so expensive, engineers cannot simply store the entire database in this memory. Software engineers must carefully choose which specific pieces of data to store in the cache.
The main goal is to keep the most requested data readily available. When the application needs this data, it grabs it from the fast memory instead of the slow disk. This drastically reduces latency.
Latency is the total time it takes for a system to fetch data and return it to the user.
Let us explore how this works behind the scenes.
We will look at the different strategies engineers use to read data from and write data to this memory layer.
What Happens Behind the Scenes
Consider a system that needs to load a user profile document. The application sends a request to the database to find this specific profile document.
The database scans its hard drive, finds the document, and sends it back to the application.
This process requires heavy computation and takes valuable milliseconds to complete.
If one thousand users request that exact same profile document, the database repeats that slow process one thousand times.
This is incredibly inefficient and wastes massive amounts of processing power.
By introducing a cache, we place a fast memory component directly between the application and the database.
This directly solves the repetition problem.
Now, the database only processes the very first request for that profile document. The system saves a copy of the returned document inside the fast memory component. For the remaining requests, the application retrieves the document instantly from the fast memory. The database is completely protected from the repetitive workload.
Cache Reading Strategies
When an application needs to display data, it must decide where to look first. The system must choose how the application, the cache, and the database interact with one another.
There are two primary strategies for reading data efficiently.
The Cache Aside Pattern
The Cache Aside strategy is the most common caching pattern in distributed systems. In this architectural setup, the cache sits right next to the main database.
The application communicates with both the cache and the database directly. The cache itself never talks to the database.
Here is exactly what happens during a data request.
First, the application asks the cache if it holds the required data.
If the data is present, this specific event is called a cache hit.
The application immediately retrieves the data from memory and returns it to the user.
If the data is not in the cache, this event is called a cache miss. The application then goes directly to the main database to fetch the missing information.
The slow database processes the query and returns the required information.
Once the application retrieves the data from the database, it copies that data into the cache. The next time the application needs this same data, it will experience a successful cache hit.
The user gets their data instantly without bothering the database.
This strategy is often called lazy loading because data is only loaded into the cache when actively requested. It prevents the limited memory from filling up with useless data. However, a major downside is that a cache miss forces the application to make three separate network trips.
The Read Through Pattern
The Read Through strategy takes a different architectural approach.
In this pattern, the application does not communicate with the main database at all.
The cache sits directly between the application and the database. The application treats the cache as the only data store it needs to know about.
When the application needs data, it simply asks the caching layer.
If the data is available, the cache returns it immediately.
If there is a cache miss, the cache itself is strictly responsible for fetching the data from the database.
The cache retrieves the data from the database and updates its own internal memory. After saving the data internally, the cache sends the data to the application. The application remains completely unaware that a database query even occurred.
This approach greatly simplifies the core application code. The developers do not need to write complex logic to handle cache misses inside the main application. The caching service handles all the background synchronization automatically.
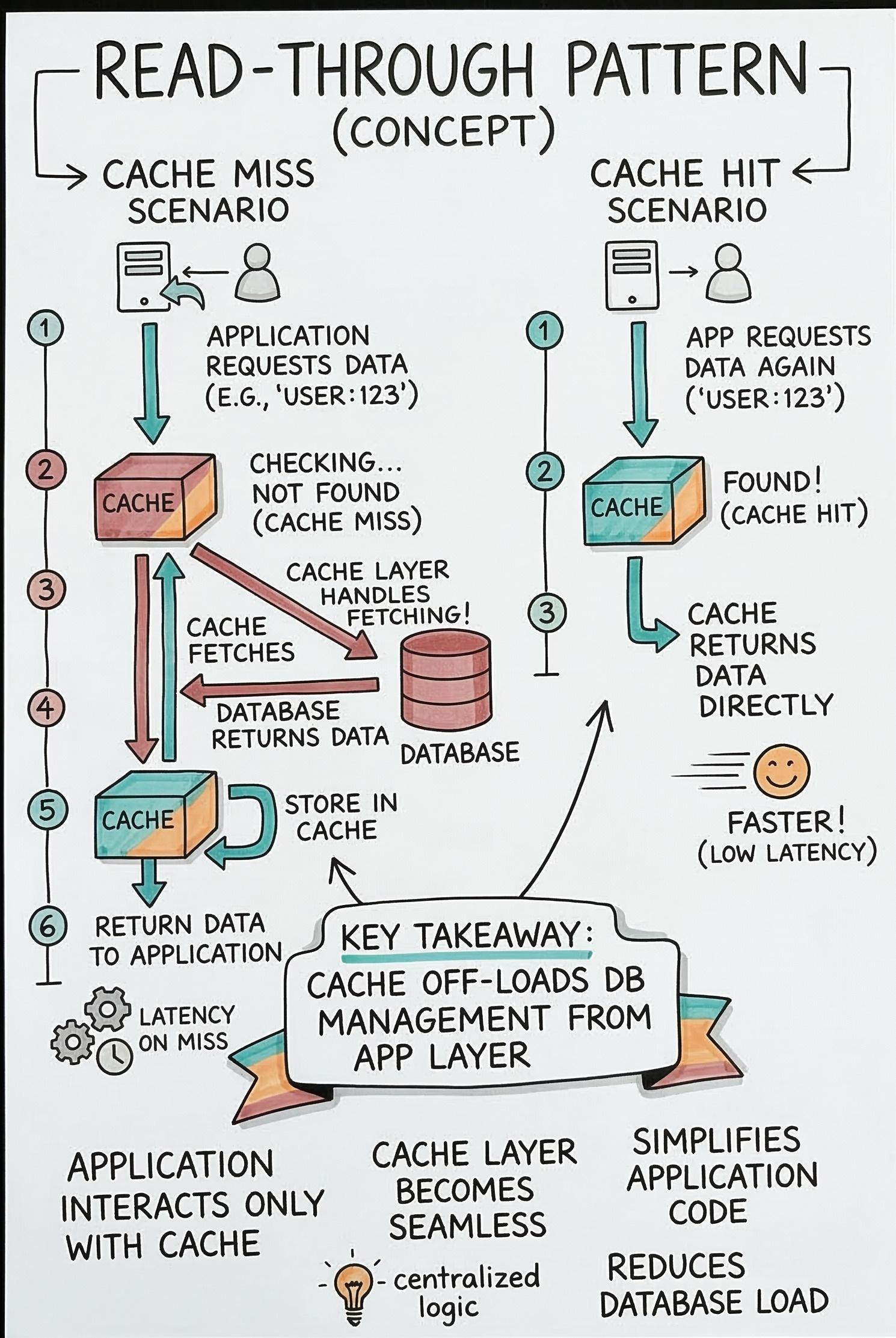
The main disadvantage is that the initial setup requires complex configuration.
Engineers must properly configure the caching service to connect directly with the database. It is highly effective for systems where the exact same data is requested repeatedly.
Cache Writing Strategies
Reading data is only half of the system design equation.
Applications also need to update and save new data constantly. When an application writes new data, the system must ensure the cache and the database stay synchronized.
If they do not match, the application will display incorrect information.
The Write Through Pattern
In a Write Through strategy, data is written to the cache and the database at the exact same time. The application sends the new data to the cache layer first.
The cache then immediately writes that data directly into the main database synchronously.
Synchronous means the operations happen one after the other in a strict order.
The process is only considered successful when both the cache and the database have safely saved the data.
This completely guarantees that the fast memory and the permanent disk are perfectly synchronized.
There is absolutely no risk of displaying outdated information because the cache is always accurate.
The major disadvantage here is high write latency. Because the application must wait for the data to be written to both storage layers, the save process takes longer.
Every single write operation incurs the heavy delay of writing to the slow database disk.
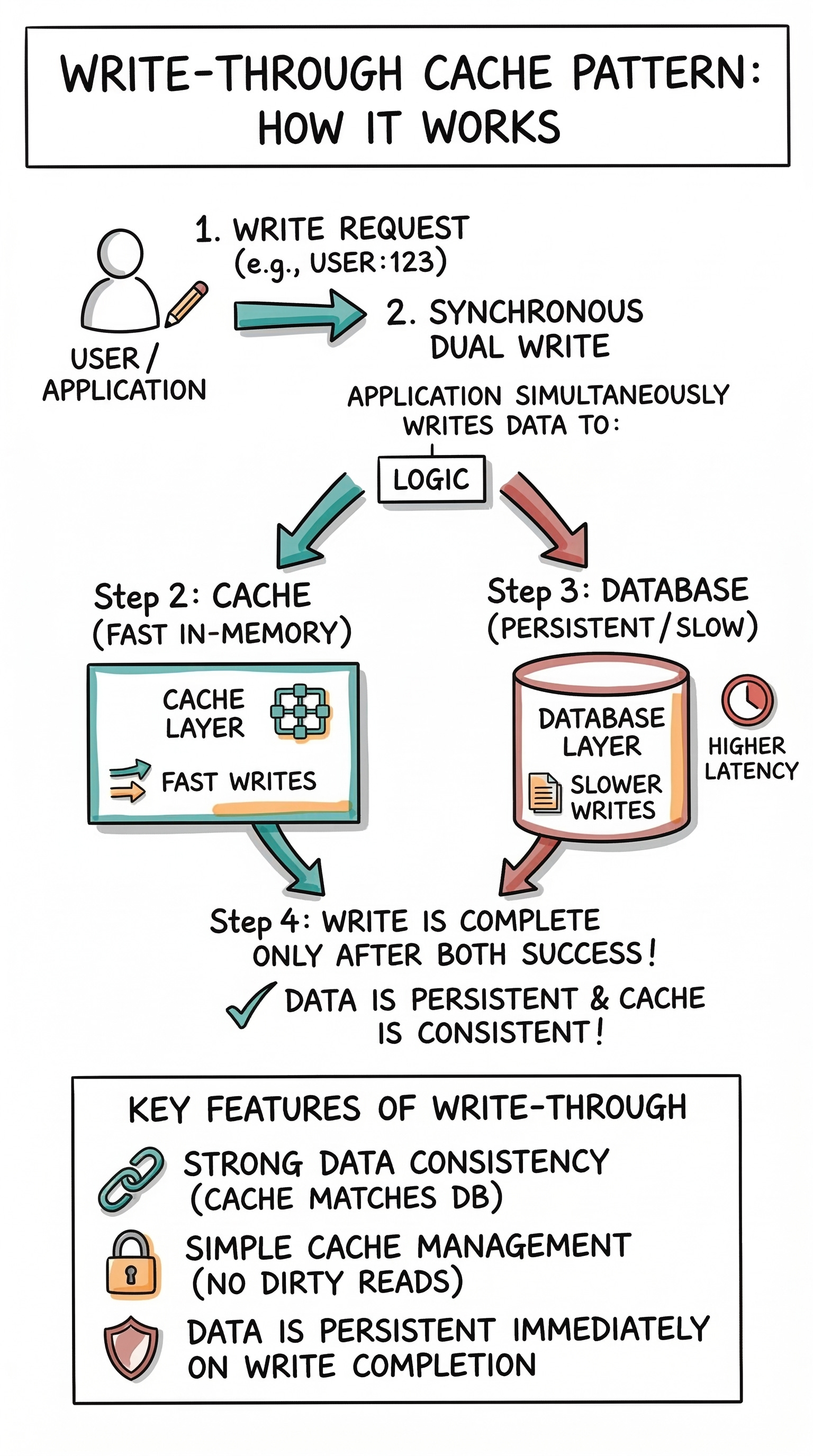
This strategy is best for financial systems where data accuracy is strictly mandatory.
A banking application cannot afford to show a user an incorrect account balance for even one second.
The Write Behind Pattern
The Write Behind strategy is designed for maximum speed and overall performance. Just like the previous strategy, the application writes new data directly to the cache. However, the cache does not immediately write this data to the database.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.