
Designing for Failure: Dead Letter Queues, Retries, and Fallbacks in Event-Driven Systems
Discover how message brokers use dead letter queues to isolate corrupted data and prevent permanent blockages in event-driven architecture.

This blog will explore:
Handling unexpected network drops.
Managing permanently broken payloads.
Building automated retry loops.
Designing safe application fallbacks.

Building distributed software systems requires accepting a fundamental truth about infrastructure. The underlying physical hardware and network connections will constantly fail.
Developers write code that runs on remote servers they cannot physically control. Hardware degradation and network connection drops happen continuously.
Software that assumes perfect stability will experience catastrophic data loss when these inevitable failures occur.
Anticipating these technical interruptions is the entire foundation of designing for failure. The application code must be explicitly programmed to survive when the machines running it suddenly break.
This specific architectural approach focuses on predicting and handling technical interruptions automatically.
The primary goal is ensuring temporary connection drops do not destroy active data pipelines. Understanding these exact failure patterns is absolutely critical for building resilient software platforms.
The Mechanics of Event-Driven Systems
To understand how software survives failures, we must examine how modern applications communicate.
Large applications are split into smaller independent programs called microservices. These independent microservices run on different servers and communicate over a network.
In an event-driven architecture, this communication happens asynchronously.
A sending microservice generates a small text-based data packet called an event. This event signifies that a specific action successfully occurred within the application.
The sending microservice transmits this event to a central routing hub called a message broker.
The message broker holds the incoming data securely inside a sequential structure called a queue. The sending microservice immediately moves on to its next task without waiting for a reply.
Other microservices connect to this message broker to download and process the waiting events. This asynchronous design allows systems to process massive amounts of data rapidly. However, this disconnected network communication introduces a massive new technical vulnerability.
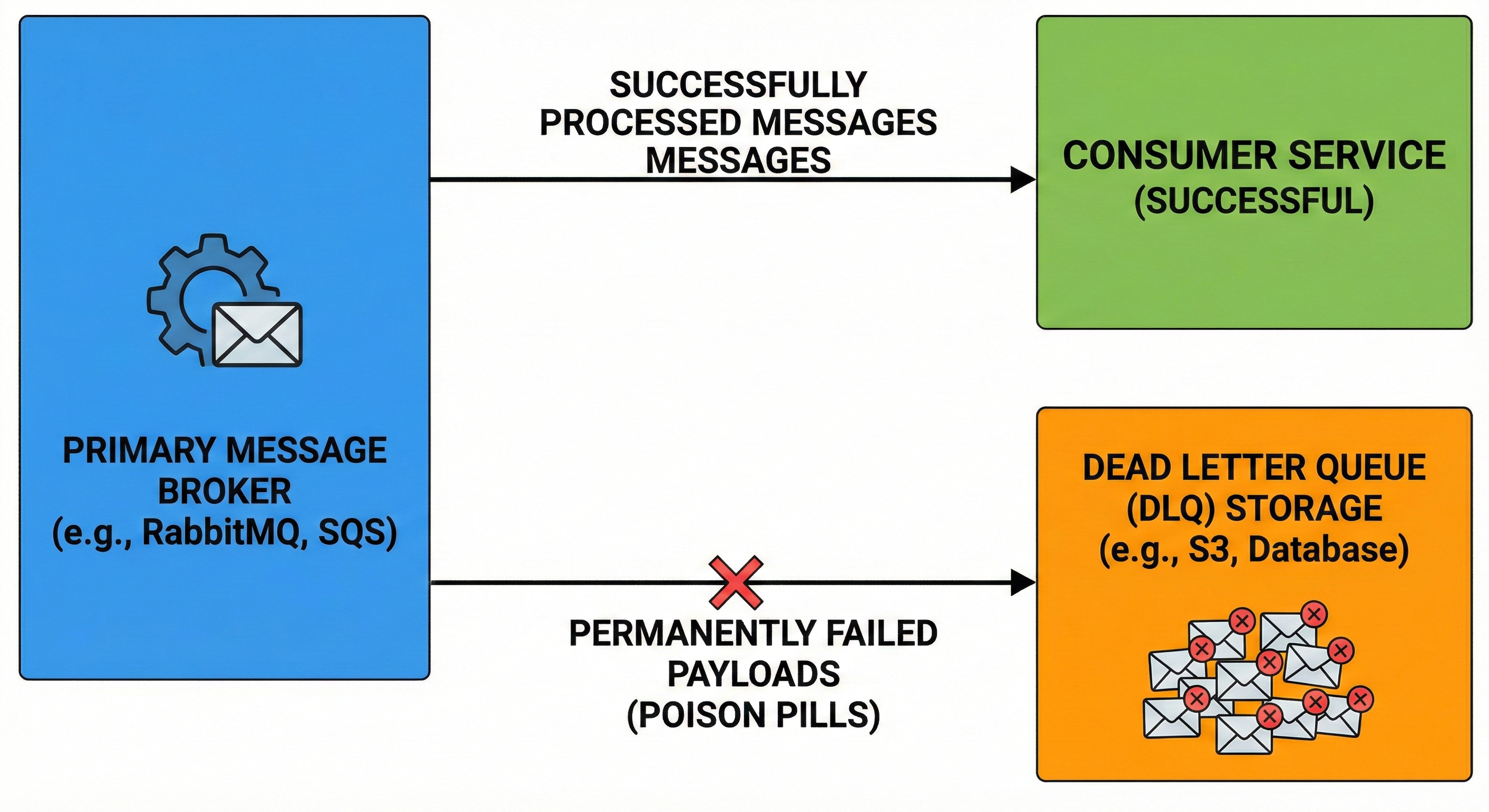
If a receiving microservice crashes while downloading an event, that data might disappear completely. The network connection between the broker and the microservice might briefly disconnect. Engineers must implement specific software patterns to prevent permanent data loss during these events.
Solving Temporary Glitches with Retries
Network connections inside massive data centers are highly unpredictable. A database server might briefly lock a table to perform a background update. During this brief lock, any incoming connection requests will fail instantly.
These brief communication interruptions are technically known as transient failures. A transient failure is a strictly temporary glitch that usually resolves itself within milliseconds. The underlying software is not permanently broken or corrupted.
Terminating the entire software process because of a transient failure is a terrible strategy. The most logical automated response is simply to try the exact same operation again. This automated approach is called a retry mechanism.
