
The System Design Behind Scalable AI Agents
A Practical Guide to the Architecture Behind Production AI Agents in 2026, Covering Queues, Memory, Tool Calls, and Failure Recovery


What This Blog Will Cover
Why agents are hard to scale
Queues as the execution backbone
Memory and context management
Reliable tool calls and recovery
How the pillars work together
Building a single AI agent has become easy.
A developer can wire a large language model to a few tools, give it a goal, and watch it reason through a task in an afternoon. These demos are impressive, and they have convinced many teams that agents are ready for production.
Running one agent on a laptop and running thousands of agents reliably for real users are entirely different problems.
The moment agents move into production, a set of hard system design challenges appears that the demo never revealed.
The agent that worked perfectly in testing now fails halfway through, costs more than expected, hangs on a slow tool, or loses its context and starts over.
By 2026, agentic systems have crossed from novelty into infrastructure, and scaling them has become a genuine engineering discipline.
The teams succeeding with agents are not the ones with the cleverest prompts. They are the ones who built the architecture underneath the agent to handle execution, state, action, and failure at scale.
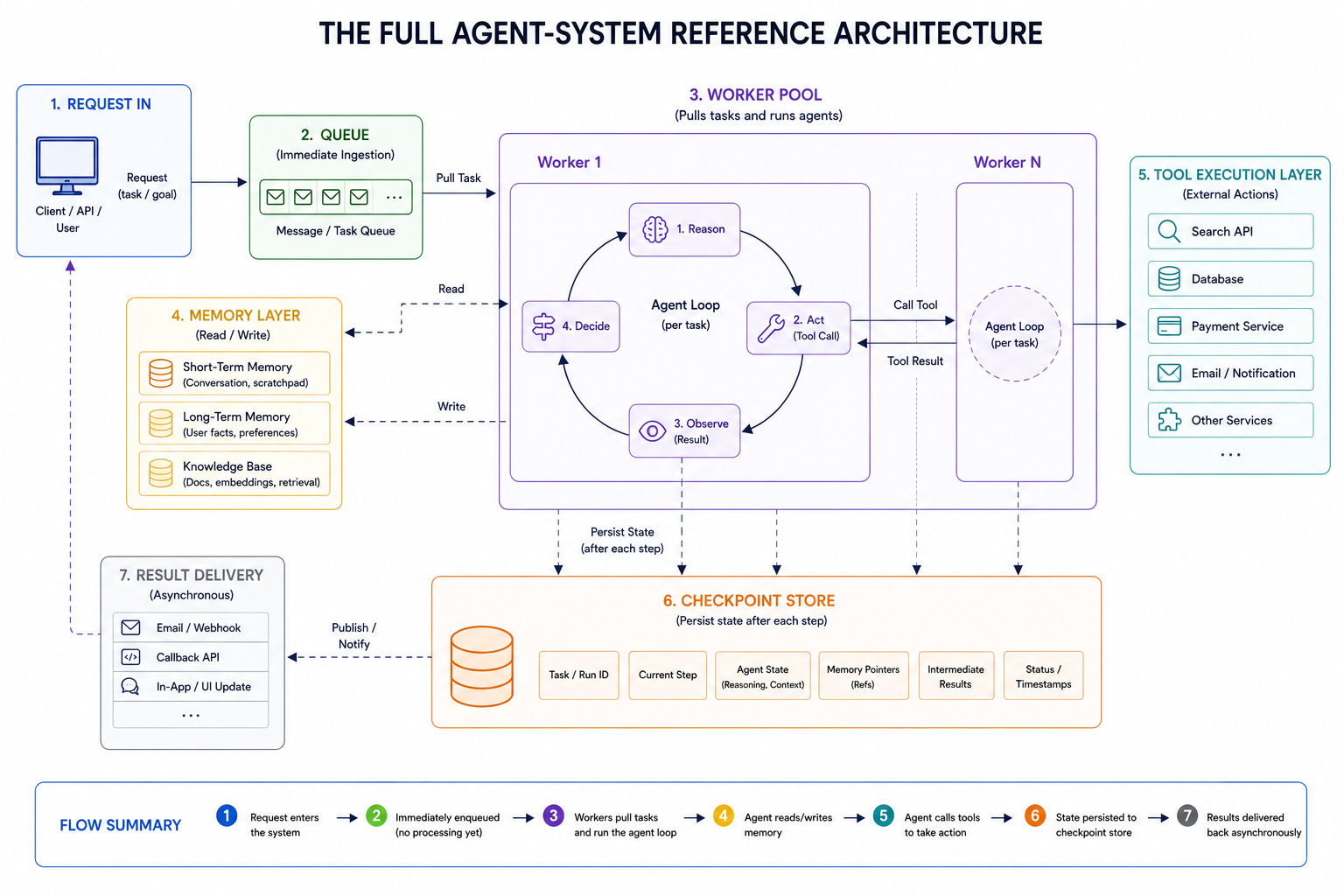
That architecture rests on four pillars.
Queues handle the long-running, asynchronous nature of agent execution.
Memory manages the state and context an agent needs across steps and sessions.
Tool calls let the agent act on the world reliably and safely. And failure recovery keeps the system robust when the many things that can go wrong inevitably do.
This article walks through each of these four pillars in depth, explaining the problems they solve and the patterns that solve them. It is written for engineers building real agent systems in 2026, who need to move beyond the demo and design something that works at scale.
What Makes Agents Hard to Scale
Before the pillars, it is worth understanding why agents are so different from the services engineers are used to building. Their difficulty comes from a few properties that ordinary request-response systems do not share.
An AI agent is a system where a large language model is given a goal and the ability to take actions, then runs a loop.
In each iteration, the model reasons about what to do, calls a tool to take an action, observes the result, and decides what to do next, repeating until the goal is met. This loop is the fundamental unit of an agent, and everything else is built around it.
The first hard property is that agent runs are long-lived.
A normal web request completes in milliseconds, but an agent run can take seconds, minutes, or even hours, because it makes many sequential model and tool calls. You cannot hold a connection open and block a user for that long.
The second property is that agents are stateful.
The loop carries an accumulating context of reasoning steps, tool results, and memory. This state must be preserved across many steps and sometimes across sessions, which is unlike the stateless services that scale so easily.
The third property is that agents make many expensive, slow, and non-deterministic calls. Every model call costs money in tokens, takes meaningful time, and is subject to rate limits.
The same input can produce different outputs, which makes behavior hard to predict and debug.
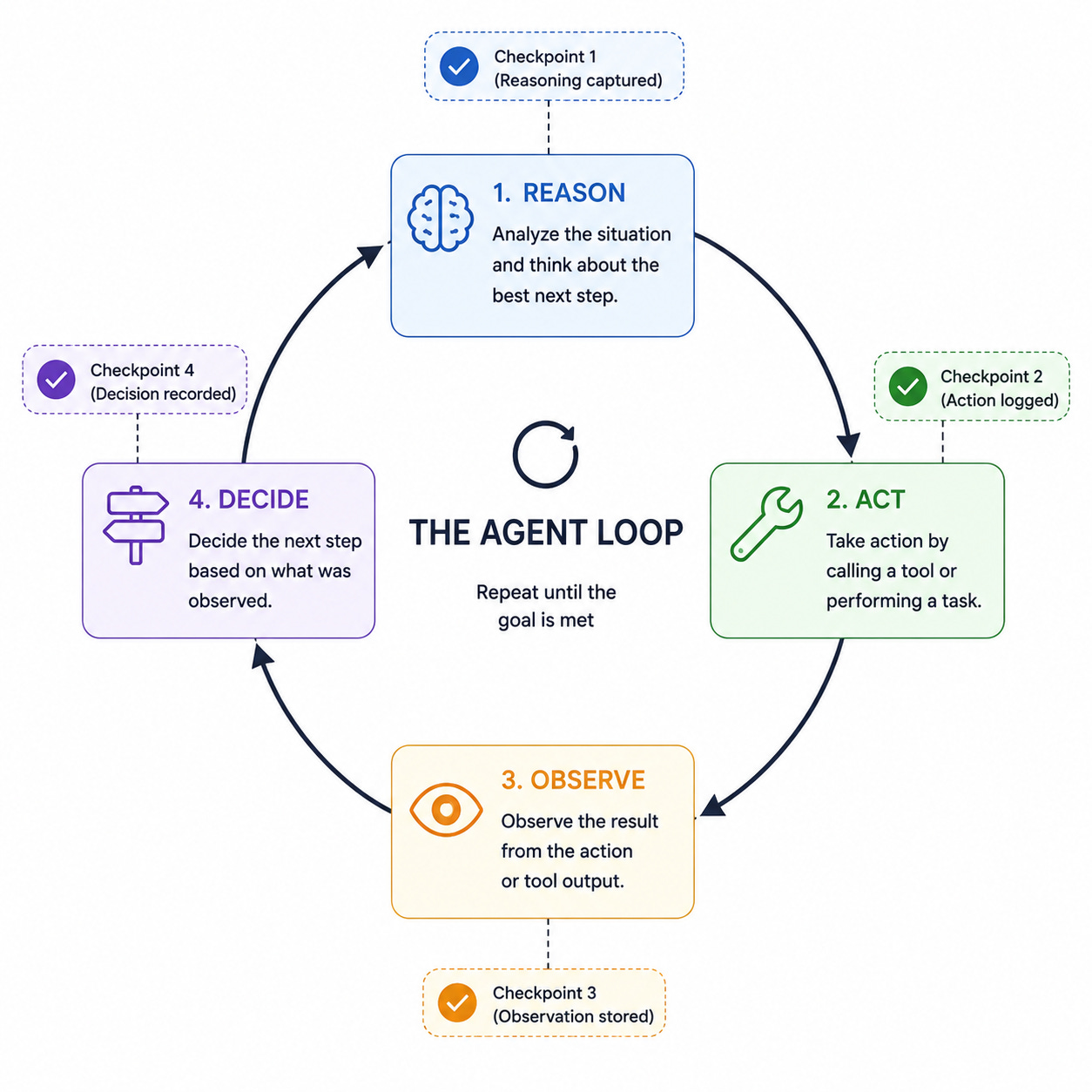
The fourth property is that failure is normal, not exceptional.
A tool can fail, a model call can time out, the loop can get stuck making no progress, a run can exhaust its budget, or a worker can crash partway through a run that has already done expensive, real work.
Designing for failure is not optional.
These four properties, long-lived, stateful, expensive, and failure-prone, are exactly why the four pillars exist. Each pillar addresses one face of this difficulty.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.