
Database Indexing Explained: How B-Trees Make Queries 1000x Faster
Explore the technical mechanics behind database indexing. We explain full table scans and how structured trees optimize query speeds in software architecture.


Software applications usually perform perfectly during their initial launch phase.
A fresh database processes data retrieval requests almost instantly.
The server hardware experiences zero operational strain when handling small datasets. Everything functions smoothly during the early days of development.
However, a silent performance killer emerges as applications mature and grow.
The database continuously stores thousands and eventually millions of raw records. Suddenly, simple data retrieval operations take seconds instead of milliseconds.
The backend programming interface freezes while waiting for information.
Central processing unit utilization spikes to maximum capacity during these moments. This severe performance degradation happens because the system must inspect every single row to find specific data.
This sequential scanning process causes countless system scaling failures.
Understanding how to organize data efficiently is a fundamental requirement for software architecture.
The exact technical solution to this massive operational bottleneck is a concept known as database indexing.
The Raw Storage Problem
Consider a database table named Users containing columns for identifiers and email addresses.
The database engine writes new information sequentially, placing raw data into fixed storage chunks on the hard drive.
These chunks are called Pages.
The database allocates more pages and appends new rows as data arrives. This raw data possesses no inherent sorting mechanism.
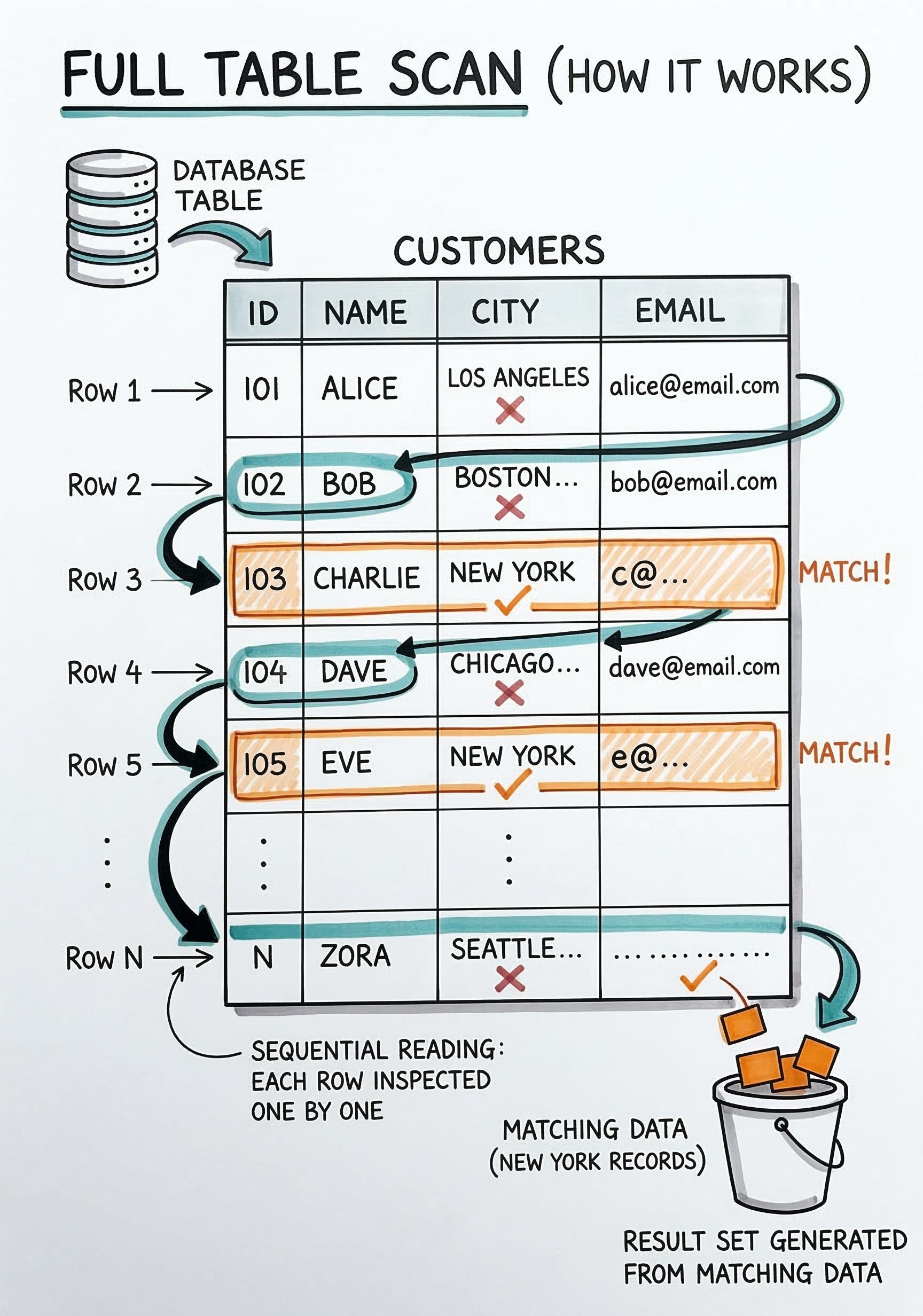
When an application requests an email, the database does not know which page contains it. The system must start reading from the very first page.
It loads the first page into system memory and checks every single row.
If the email is not there, it moves to the second page. It continues this process sequentially until it finds the correct information.
This exhaustive process is called a Full Table Scan. It is a highly inefficient method for managing large datasets.
The Brutal Cost of Full Table Scans
Computer science uses Big O Notation to describe algorithmic performance.
A full table scan operates at O(N) time complexity, meaning execution time grows linearly alongside data volume.
If the table holds one million rows, the database must potentially check one million rows. Checking millions of rows creates a massive hardware burden.
Hard drives are the slowest components inside a server. Loading data pages into memory is extremely slow, a process called Disk Input Output.
High disk operations rapidly destroy performance. Memory buffers become saturated when loading huge data blocks.
The processor wastes cycles inspecting irrelevant rows, creating a queue of delayed queries.
This bottleneck ultimately results in severe server timeouts. Adding more hardware resources only temporarily masks the underlying problem.
Developers need a method to find specific data without scanning the entire file.
Introducing the Database Index
A Database Index is a specialized data structure designed to accelerate data retrieval, functioning separately from the main table.
When developers create an index, they select a column to optimize.
The database extracts values from that column, sorts them mathematically, and stores them inside the index structure. It only stores the sorted value alongside a Pointer.
A pointer is a memory address indicating exactly where the full row lives on disk. The engine intercepts search queries to check if a relevant index exists.
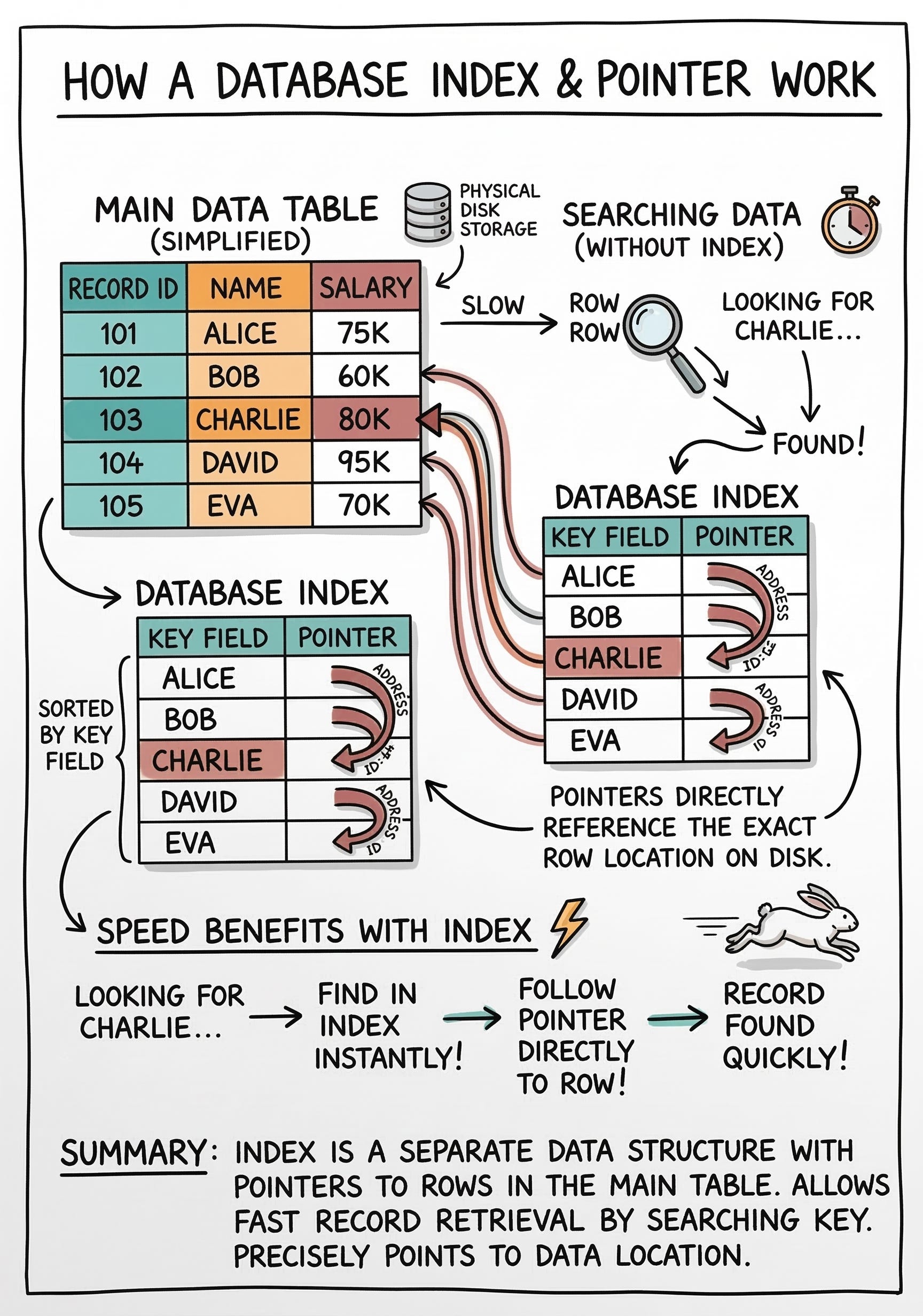
If one exists, the database searches the sorted structure, finds the exact pointer, and jumps directly to the correct disk page.
Behind the Scenes: The Balanced Tree Data Structure
Relational databases do not store index values in a simple vertical list. They utilize a highly complex data structure called a Balanced Tree.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.