
System Design Deep Dive: Connection Pooling, Latency, and PgBouncer
Understand the system design mechanics behind database connections. We explain process forking, memory exhaustion, and the benefits of multiplexing.


You have likely experienced a specific, frustration-inducing scenario in your journey as a developer.
You write a backend application on your local machine, such as a simple API using Python, Go, or Node.js.
You run it against a local database. It feels incredibly snappy.
The API responds instantly, the database queries finish in single-digit milliseconds, and the logic flows perfectly. You are confident.
Then, you deploy this application to a production environment. You expose it to real-world traffic.
Suddenly, the performance degrades.
Response times creep up from 50 milliseconds to 500 milliseconds, then to two seconds.
Eventually, the database server stops accepting new connections entirely, throwing “Connection Refused” errors, and your application crashes.
You check the query logs, but the SQL is efficient. You check the code loops, and there are no obvious bottlenecks. You check the CPU usage, and it isn’t maxing out.
The problem is rarely the logic of your code.
The problem is the infrastructure of communication.
In a distributed system, the way your application connects to the database is often the single biggest bottleneck.
This post will explain the hidden mechanics of network connections, the massive cost of the TCP handshake, and how Connection Pooling solves the physics of latency.
The High Cost of “Hello”
To understand why your application slows down, we must look at what happens physically when you write a line of code like db.connect().
It feels like a simple instruction; a variable assignment. However, in a networked environment, opening a connection is a rigorous negotiation process between two computers.
They cannot simply start exchanging data; they must first agree on the rules of engagement.
This process is governed by the Transmission Control Protocol (TCP) and is known as the TCP 3-Way Handshake.
The Physics of the Handshake
When your application (the client) wants to talk to the database (the server), it must initiate a strict three-step sequence. This is not a software abstraction; this is a physical exchange of packets across network cables.
SYN (Synchronize): The client sends a packet with the SYN flag turned on. This tells the server, “I want to open a new connection, and here is my initial sequence number.”
SYN-ACK (Synchronize-Acknowledge): The server receives the packet. If it is willing to accept the connection, it allocates a kernel structure to track it. It sends back a packet with both the SYN and ACK flags. This tells the client, “I received your request, and here is my initial sequence number.”
ACK (Acknowledge): The client receives this and sends a final ACK packet. This tells the server, “I have received your confirmation, and we are now connected.”
Only after this third step is the connection established (the state changes to ESTABLISHED).
This exchange is bound by the speed of light and network latency.
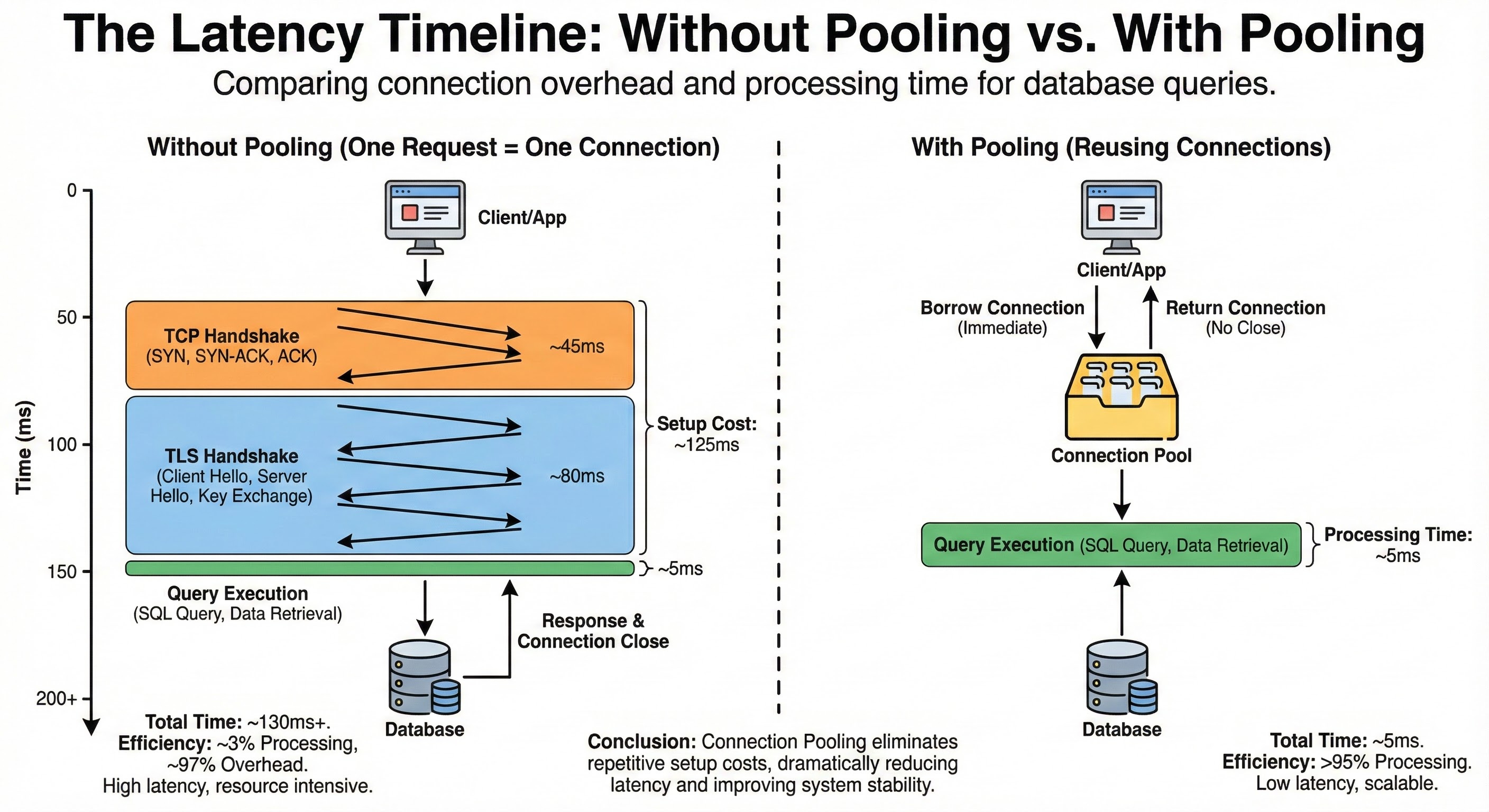
If your application server and database server are in different availability zones (AZs), a single round trip might take 30 milliseconds.
The handshake requires 1.5 round-trip. That is 45 milliseconds of waiting before you can even attempt to send a SQL query.
The Security Tax (SSL/TLS)
In modern production environments, we never send data over plain text.
We use encryption (SSL/TLS). This adds a second, even heavier handshake immediately after the TCP handshake completes.
The client and server must exchange digital certificates, verify signatures against a Certificate Authority (CA), and negotiate a cipher suite. This involves complex mathematical operations (like RSA or Elliptic Curve Cryptography) that consume CPU cycles.
If you add the TCP handshake (45ms) and the TLS handshake (60-100ms) together, the “setup cost” of a single connection can easily reach 150 milliseconds.
Consider the math: If your SQL query takes 5 milliseconds to execute, but the connection setup takes 150 milliseconds, your system is spending 97% of its time waiting for the network and only 3% of its time actually processing data.
Why “One Request, One Connection” Fails
The naive approach to backend development is to open a new connection for every single HTTP request.
User requests a profile page.
App opens a connection (150ms delay).
App queries the user table (5ms).
App closes the connection.
App returns the page.
This approach is functionally correct, but it is disastrous for performance.
Beyond the latency, it causes Resource Exhaustion on the database server.
The Memory Penalty: Processes vs. Threads
A database connection is not just a network socket.
On the database server side, a connection is a heavyweight object.
In databases like PostgreSQL, the architecture is process-based.
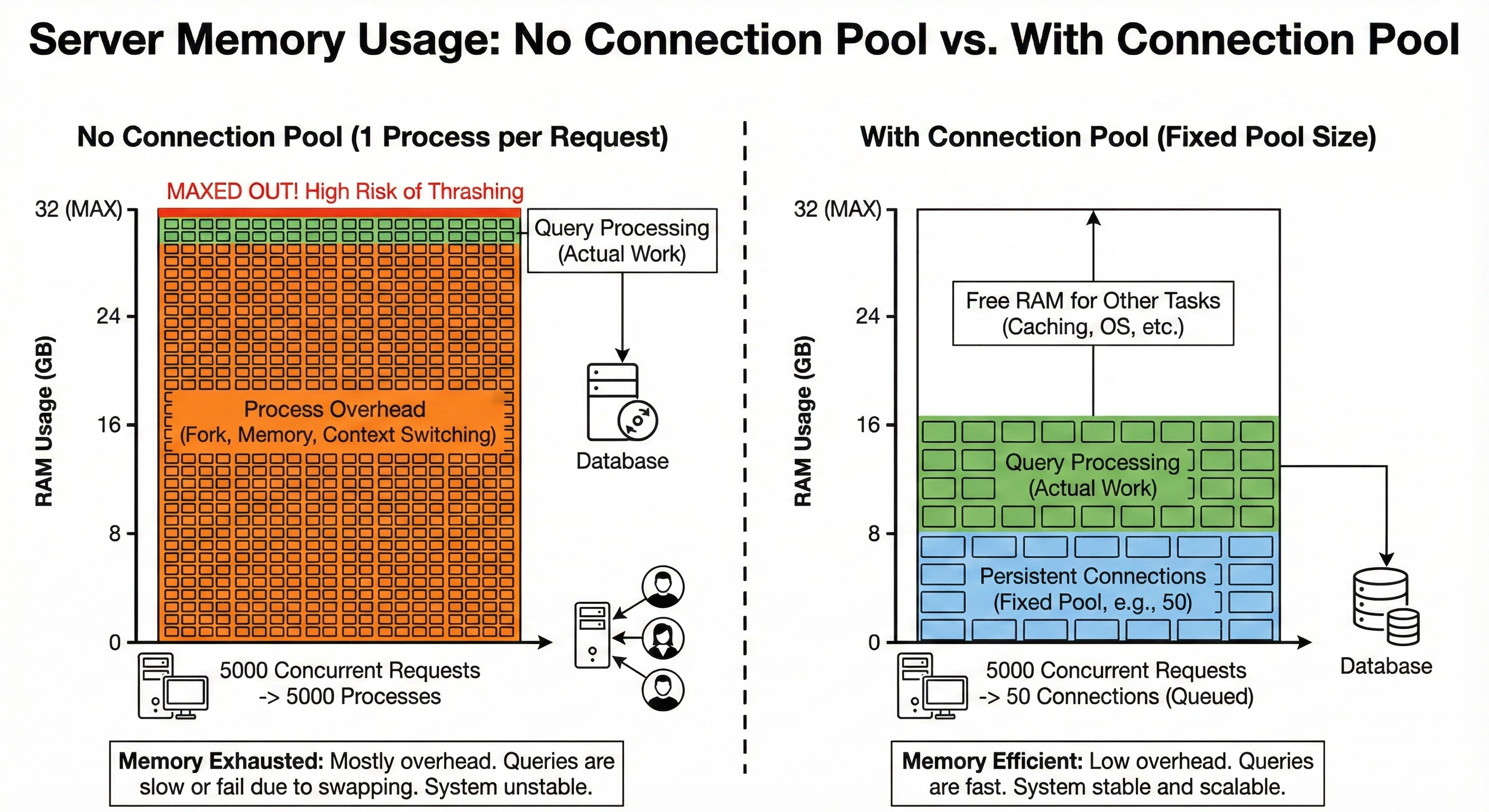
Every active connection triggers the operating system to fork() a new process. This new process requires its own private memory space (RAM) to manage data buffers, query states, descriptors, and sorting areas.
Suppose each connection consumes roughly 10 MB of RAM.
If you have 10 users, you use 100 MB. This is negligible.
If you have a traffic spike of 5,000 concurrent users, your database tries to allocate 50 GB of RAM instantly.
If the server does not have that much physical memory available, it will start swapping.
The operating system will move memory pages to the hard disk to make room.
Disk access is nanoseconds vs. milliseconds, thousands of times slower than RAM.
The system will grind to a halt, and queries that usually take milliseconds will take seconds or minutes.
The CPU Penalty: Context Switching
Even if you had infinite RAM, you would hit the CPU bottleneck.
A CPU core can only execute instructions for one process at a specific moment in time.
If you have 8 CPU cores and 5,000 active processes, the operating system must share the cores among them. It does this by “time-slicing”; running Process A for a tiny fraction of a second, pausing it, saving its state, loading Process B, running it, and so on.
This saving and loading of states is called Context Switching.
Context switching is not free. It consumes CPU cycles.
As the number of processes rises, the CPU spends more time switching between processes than it does actually running your SQL queries. This leads to a degradation curve known as thrashing, where the server is working at 100% CPU capacity but accomplishing almost zero productive work.
The Solution: Connection Pooling
To solve both the latency issue (time) and the resource exhaustion issue (hardware), we use a Connection Pool.
A connection pool is a cache of database connections that are kept open and reused for multiple requests.
It is a fundamental pattern in system design that shifts the model from “creation and destruction” to “borrowing and returning.”
