
Complete NoSQL Database Guide for System Design Interviews [2026 Edition]
Build real understanding of NoSQL concepts that system design interviews test, explained clearly with modern best practices.

This blog covers:
NoSQL basics
Data models and tradeoffs
Consistency and replication choices
Scaling, partitioning, indexing
2026 interview expectations

Modern software systems keep growing in three directions at the same time: more users, more data, and more moving parts.
The moment a system crosses a certain scale, the database stops being “just storage” and becomes the central performance and reliability constraint.
Relational databases are excellent at many things, but they come with two friction points that show up early in large-scale design discussions: horizontal scaling is not always straightforward, and strict relational features (like multi-table joins) can become expensive when the goal is predictable low latency at very high throughput.
This is one of the motivations behind the NoSQL family of databases and services.
A good way to think about NoSQL for interviews is simple: NoSQL is a set of database designs that trade some familiar constraints for better control over scale, latency, and availability.
The trade is not random.
It is guided by the system’s access patterns, failure tolerance, and consistency needs.
NoSQL is not one thing. It includes multiple data models (key-value, document, wide-column, graph, and more). Each model pushes the system toward a different “shape”: how data is stored, how queries work, and how the database behaves under partitions, node failures, and region outages.
NoSQL in System Design Interviews
In interview settings, “NoSQL” usually means non-relational storage, meaning the database does not require data to be modeled primarily as rows in tables with foreign-key relationships.
Instead, it stores data as documents, key-value pairs, wide rows, or graph structures.
The term itself is commonly explained as “non-SQL” or “not only SQL,” reflecting that many of these systems either do not use SQL or support SQL-like querying alongside other APIs.
In an interview, the point is not vocabulary. The point is demonstrating that database choice is a design decision.
A correct answer is usually not “pick database X,” but “pick a data model that matches the access patterns, then choose a database that implements it well.”
What Interviewers are Testing
System design interviews typically test four database instincts:
First, modeling instinct: picking a data model that supports the required queries without fighting the storage engine.
Second, distribution instinct: understanding how data is partitioned across nodes and why partitioning decisions dominate scalability and reliability.
Third, consistency instinct: being able to explain what kind of consistency is needed, what the database can guarantee, and what the system must do when guarantees are weaker than “always current.”
Fourth, operational instinct: identifying hotspots, index costs, compaction costs, replication lag, and failure modes that appear in real distributed databases.
The Core NoSQL Promise
Most NoSQL systems are designed to make two things easier:
Scale-out growth: add nodes (or partitions) to increase total throughput and storage, rather than scaling a single machine vertically.
Flexible data shapes: store records whose fields may evolve without enforcing a strict table schema up front.
It is important to be precise: flexibility and scale are not “free.” They are bought by accepting tradeoffs in joins, cross-record transactions, query expressiveness, or consistency behavior.
The NoSQL Families Worth Knowing
Interview conversations usually revolve around a handful of NoSQL families:
Key-value stores: data is retrieved by a key; operations are simple and fast, and the access pattern is usually key-based.
Document stores: records are stored as documents; querying is often richer than key-value, but still guided by how documents are structured and indexed.
Wide-column stores: data is organized into partitions and clustering, optimized for very large datasets and predictable query patterns.
Graph databases: the first-class concept is relationships between nodes, with properties on nodes and edges.
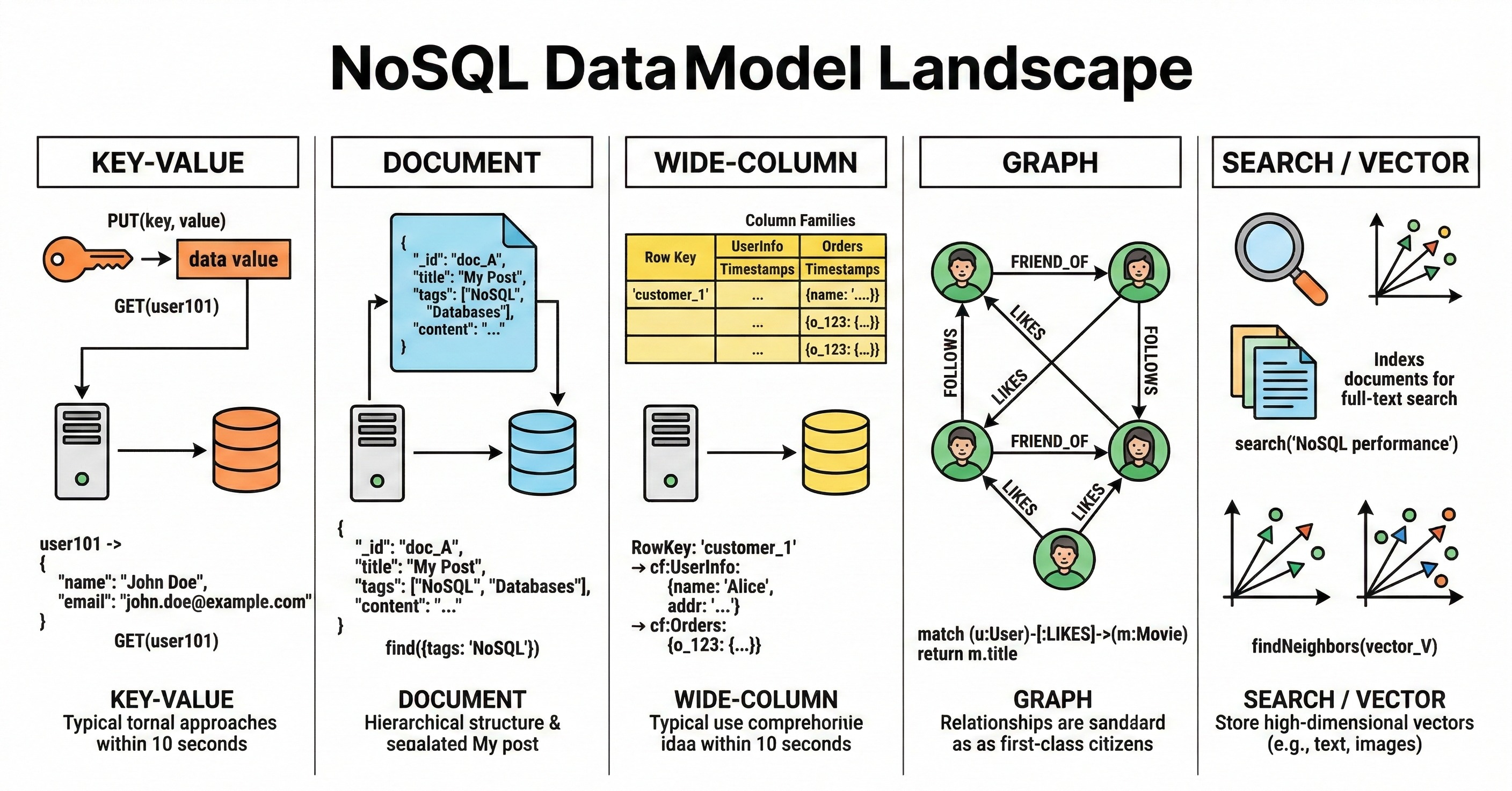
In 2026, most serious stacks also include search and vector retrieval capabilities, either as separate systems or embedded into operational databases.
NoSQL data models and schema design
For beginners, the biggest mindset shift is this:
Relational modeling often starts with normalization: reduce duplication, enforce relationships, then query with joins.
NoSQL modeling often starts with access patterns: list the queries first, then shape the stored data so those queries are fast and predictable.
This is the reason NoSQL interview answers often include phrases like “denormalization” and “precomputed views.”
It is not a preference.
It is how performance is achieved when joins are unavailable or expensive at scale.
Key-value Model
A key-value database stores values indexed by a key.
The important detail is not “the value.”
The important detail is that the database expects most reads and writes to be key-based, since the partitioning strategy usually hashes the key to place the item on a specific partition.
A minimal mental model looks like this:
Key: an opaque identifier used for routing
Value: a blob or structured payload returned as a whole
The “behind the scenes” fact that matters: at scale, the key is the routing handle.
If the key is chosen poorly, throughput can collapse due to uneven distribution across partitions.
Key-value systems often become the simplest way to deliver predictable latency, because they encourage narrow APIs that avoid complex queries.
Document Model
A document store saves records as documents, commonly JSON-like structures.
The key advantage is that fields can differ between documents without enforcing a rigid table schema.
The key design detail is that documents are the unit of reading and writing in many systems.
That pushes design toward storing related fields together so a single read returns what a request needs.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.